论文阅读笔记:“TokenLearner:What Can 8 Learned Tokens Do for Images and Videos?(NIPS 2021)”

TokenLearner: What Can 8 Learned Tokens Do for Images and Videos?(NIPS 2021)
网络结构
Framework for Video
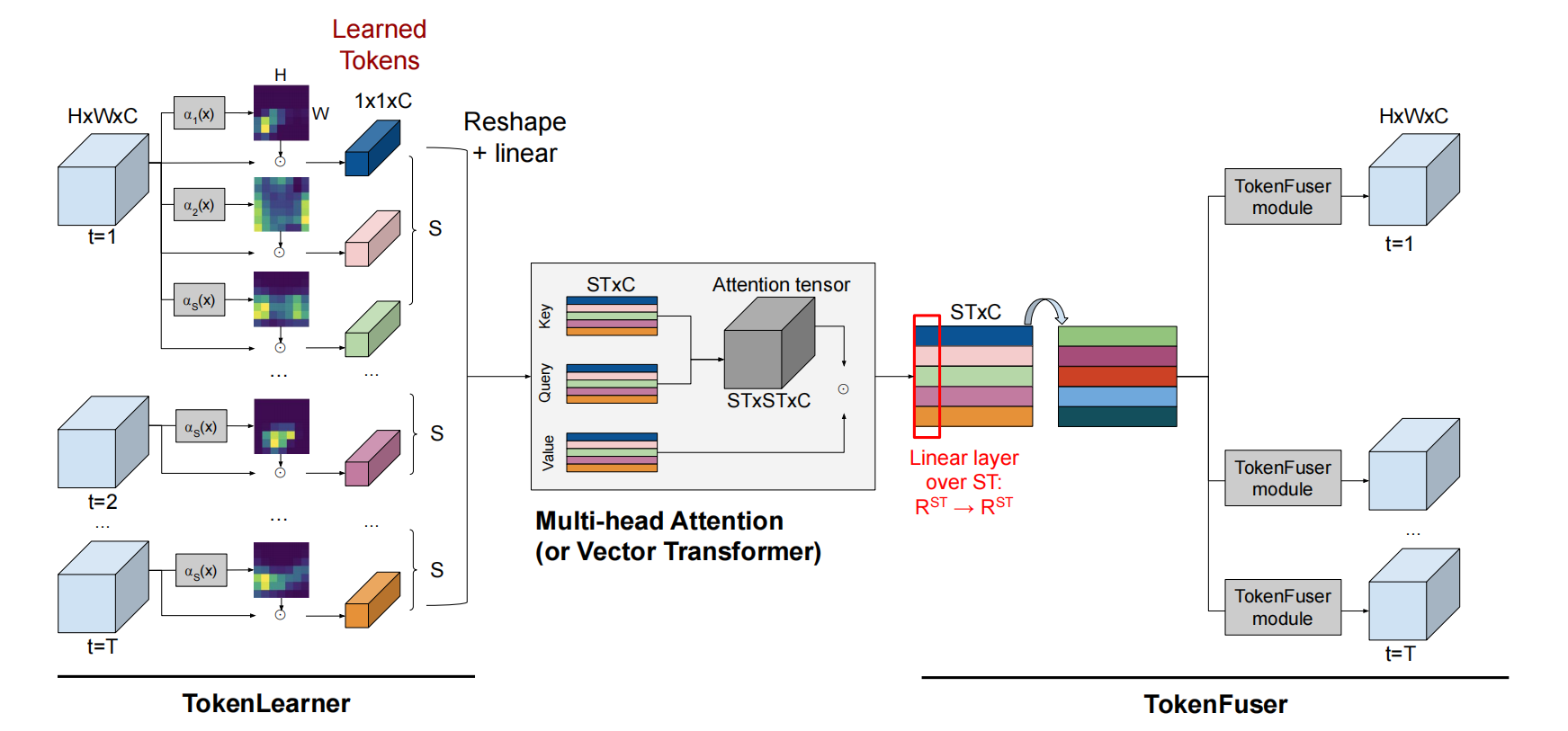
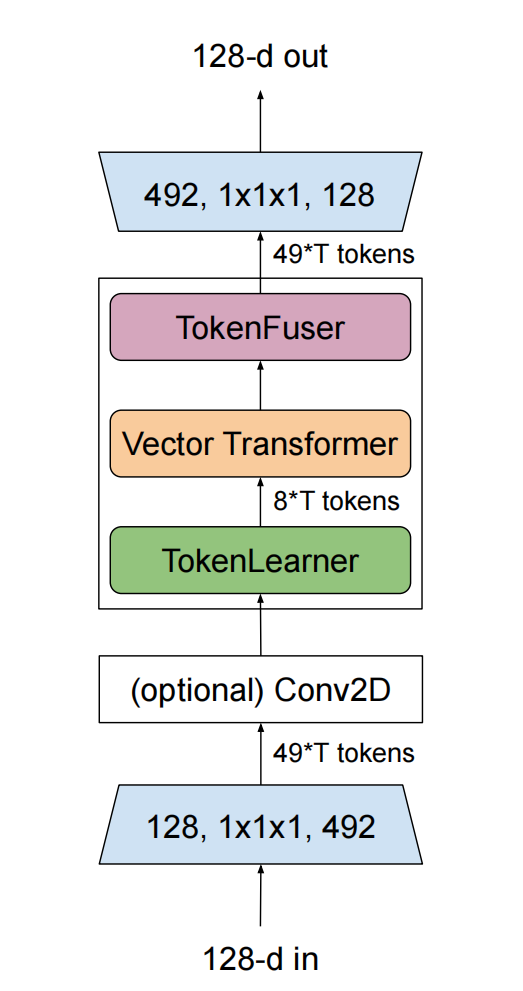
TokenLearner自适应地学习标记向量的集合,MHSA对时空关联进行建模,最后TokenFuser将它们结合起来,并重建为原始的输入tensor大小。
TokenLearner
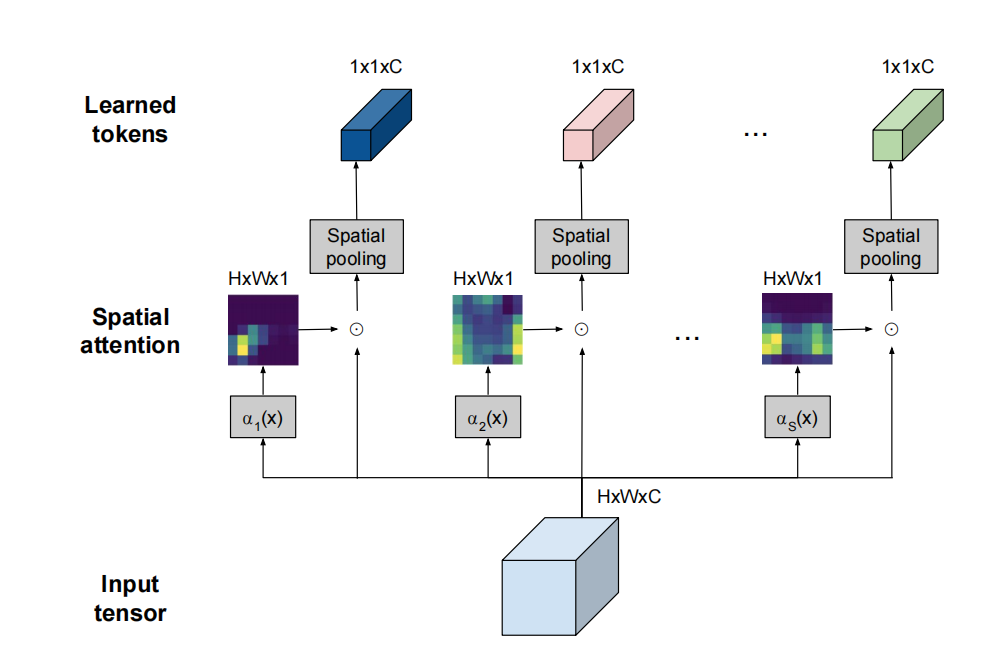
TokenFuser
token-wise linear layer: 在各个token间融合时空信息
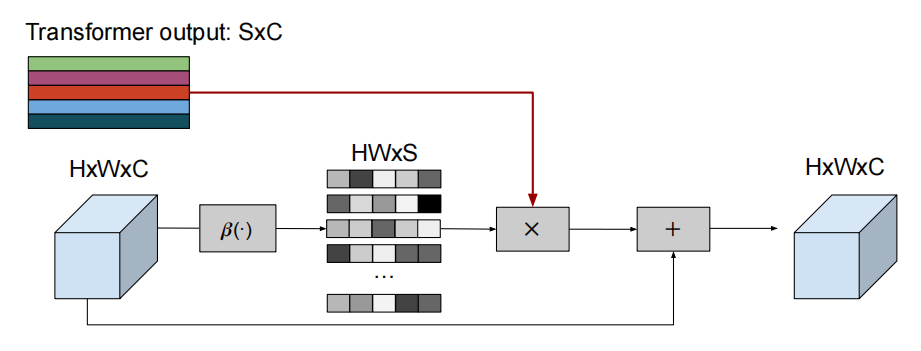
token特征的反向映射(映射回原先的tensor shape)
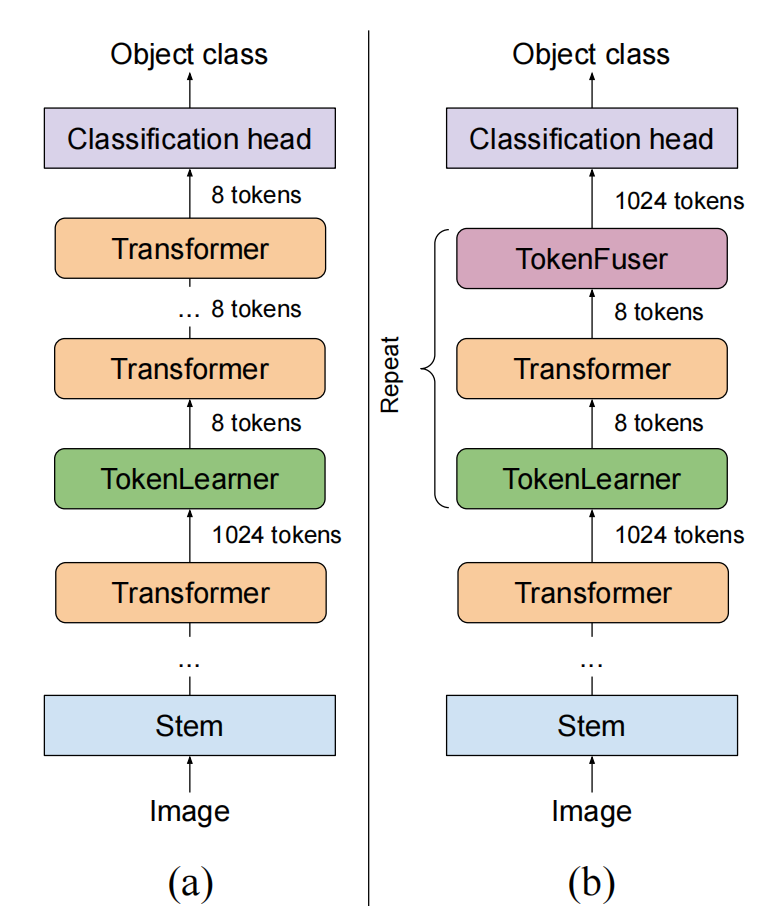
Embedding into ViT architecture
实验
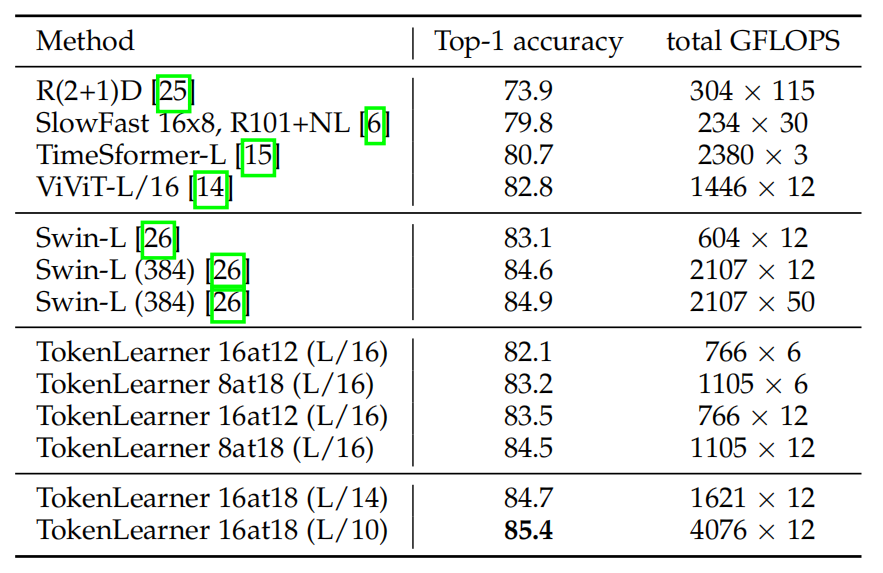
kinetics400上的SOTA对比
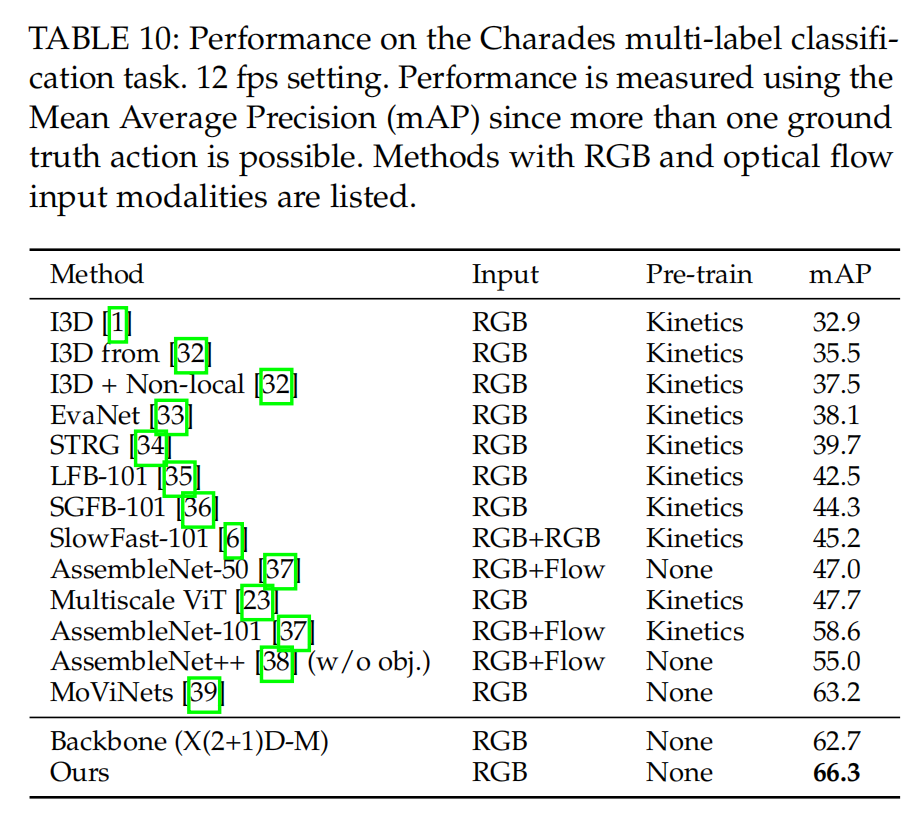
charades数据集上的模型优化
将TokenLearner嵌入X3D中,将3D卷积换成了一对2D卷积和1D卷积。1D卷积采用是TokenLearner进行替换。并把MHSA替换未来vector transformer。
- Post title:论文阅读笔记:“TokenLearner:What Can 8 Learned Tokens Do for Images and Videos?(NIPS 2021)”
- Post author:sixwalter
- Create time:2023-03-06 00:00:00
- Post link:https://coelien.github.io/2023/03/06/paper-reading/paper_reading_060/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments