论文阅读笔记:“Masked Autoencoders As Spatiotemporal Learners”

Masked Autoencoders As Spatiotemporal Learners
框架
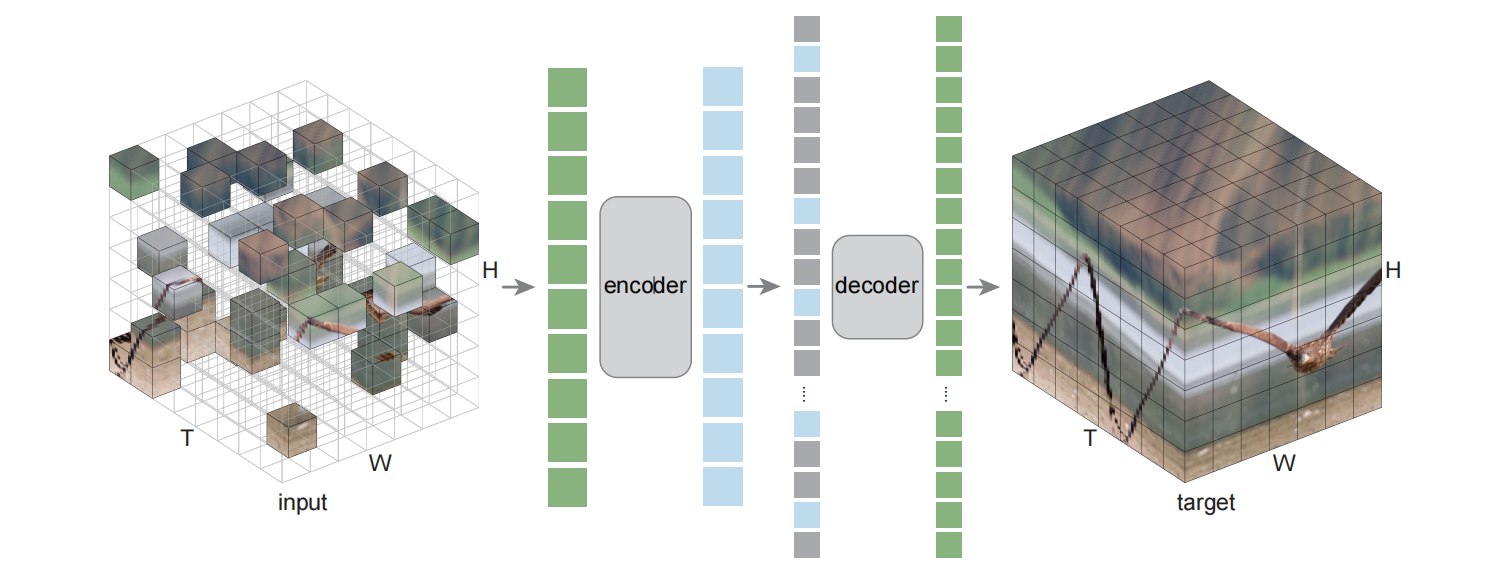
- 从损坏的输入重建干净的信号
发现
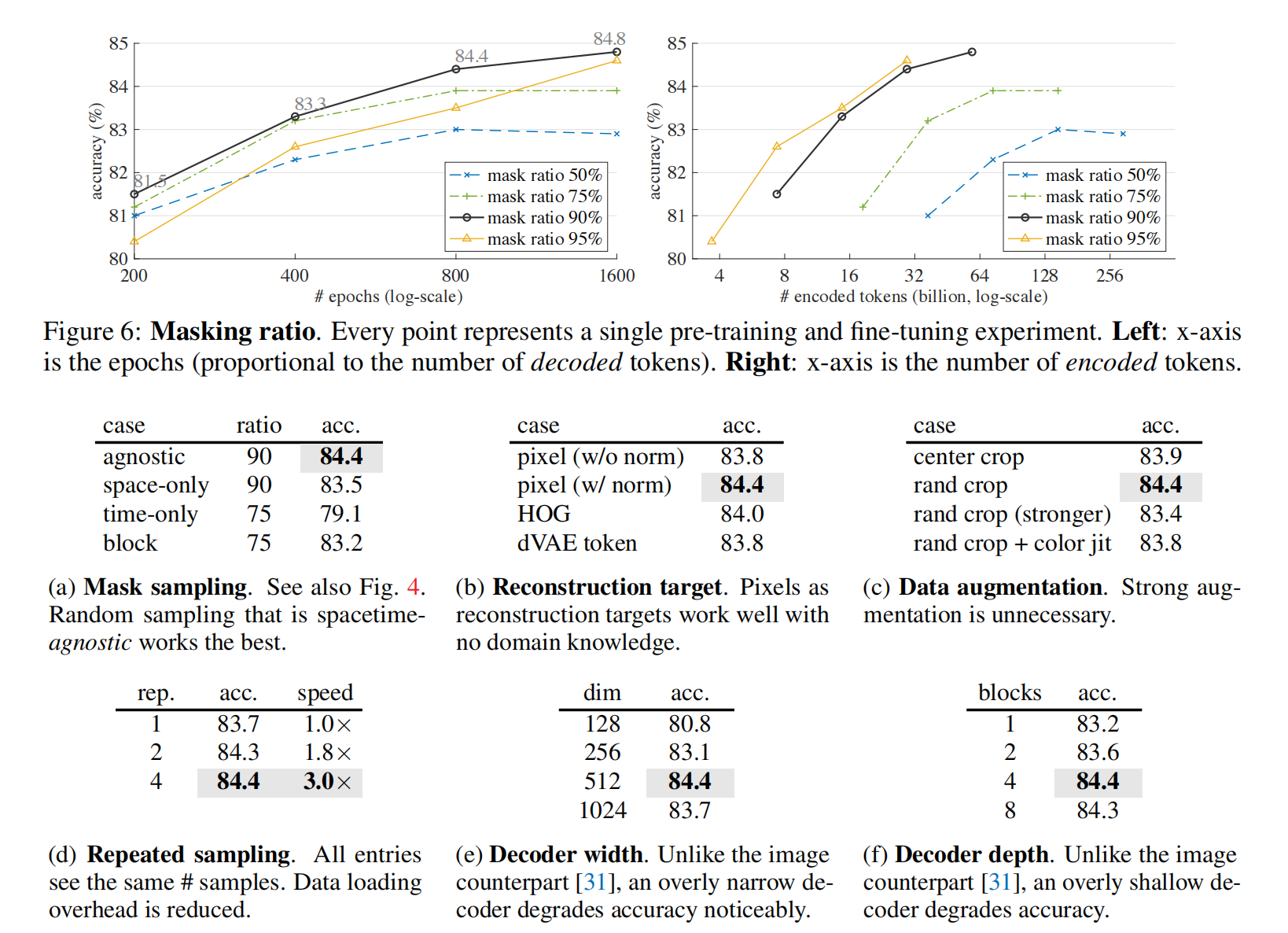
最优mask比率和数据中的信息冗余度相关
使用更高的mask比率可以更好地利用视频的时序关联信息

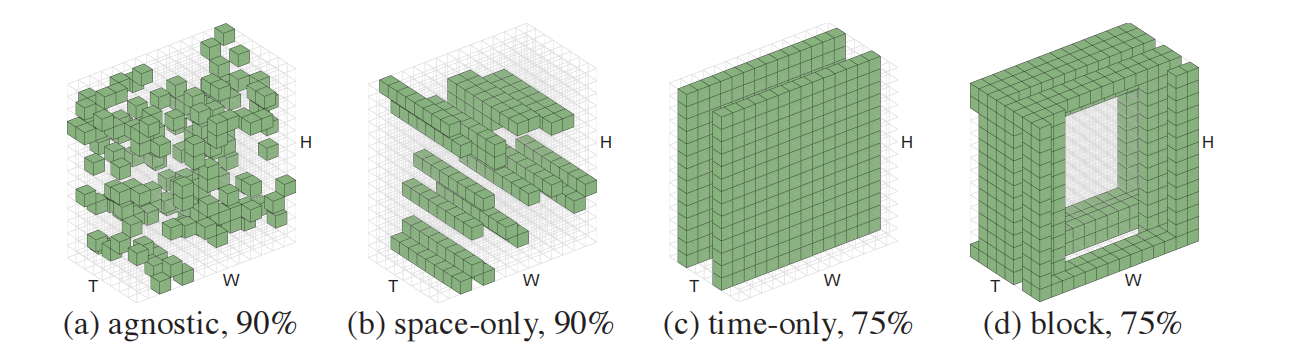
采样方法
自编码
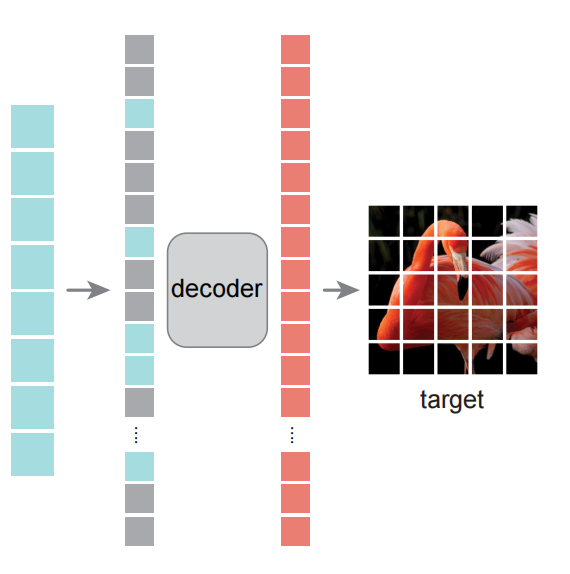
- decoder结构与encoder相比是不对称的,且只在预训练进行视频重建的时候使用。其复杂度远远小于encoder,因而就算处理的是全部的patches,它也不是性能瓶颈。
实验
性能优势

a masking ratio of 90% reduces the encoder time and memory complexity to *<1/*10
- 理论上, 7.7× 在计算量上的减少 vs. 编码全部tokens
精度优势
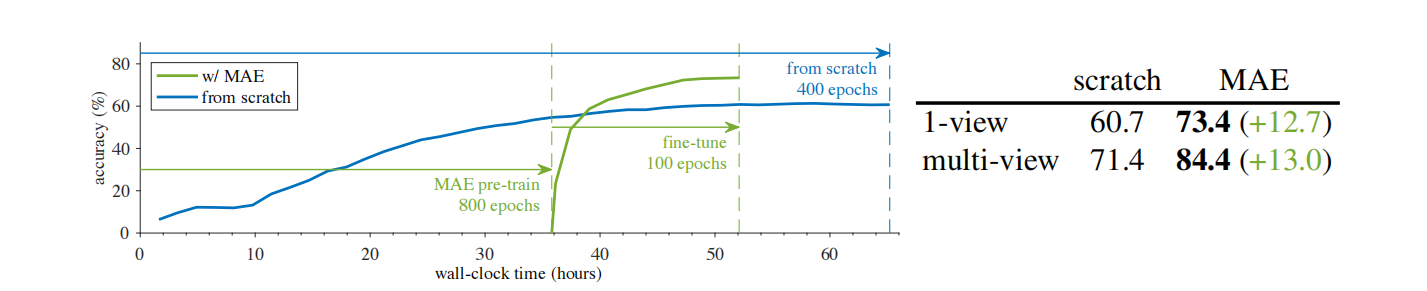
- 加入MAE能提升10个百分点以上,同时减少近1/5的训练时间
消融实验
- Post title:论文阅读笔记:“Masked Autoencoders As Spatiotemporal Learners”
- Post author:sixwalter
- Create time:2023-03-13 00:00:00
- Post link:https://coelien.github.io/2023/03/13/paper-reading/paper_reading_061/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments