实验记录05.09.2023

实验总结05.09.2023
joints分支
实验一:调lr+预训练joints数据

加入joints数据后发现效果一般,考虑是不是joints本身训练的问题,调整完学习率之后发现有效果:
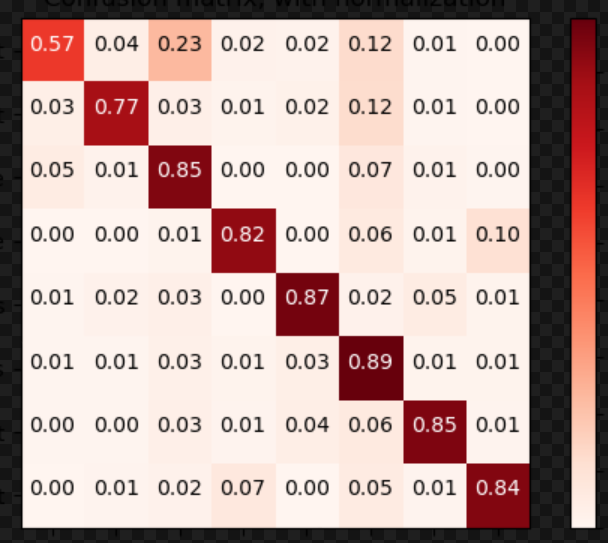
没想到改了学习率之后效果这么好,有点惊讶:
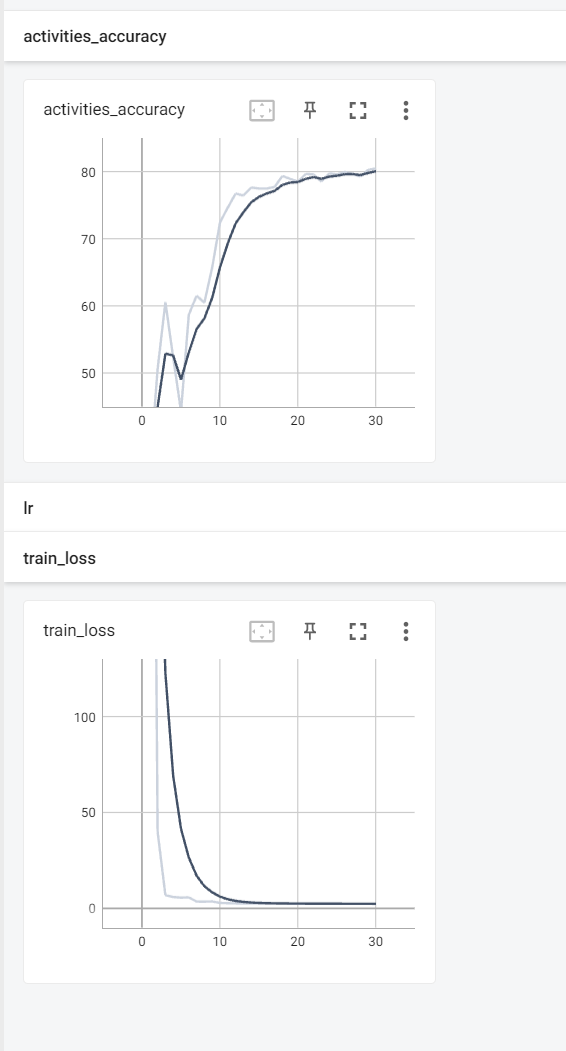
修改代码,直接载入预训练好的pose分支模型:

目前已经比baseline效果好了,现在的**结果已经达到了93%**,很接近SOTA方法(SOTA:93.6%),加入以下实验精度肯定会更高:
实验二:对数据进行标准化
实验三:增加坐标位置编码
实验四:增加时间位置编码
实验五:增加节点类型编码
实验分支
实验一:使用光流特征
实验二:更换backbone(inceptionV3)
实验三:使用tokenizer
(已尝试,效果可以,可以合入主分支中)
实验四:使用自适应的decoder代替maxpooling
(已尝试,效果可以,可以合入主分支中)
实验五:使用数据增强方法
主分支
实验一:加入全局场景自注意力(精度)
(已尝试,效果可以,已合入主分支中)
实验二:加入层次式的推理方法(精度)
我们可以通过得到的pose特征,使用自注意力机制后,得到优化后的pose特征,将其组合成为人的特征,并与rgb的人特征进行concat,再使用注意力机制优化。
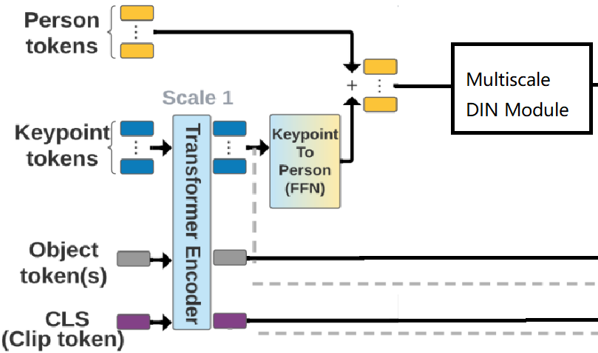
实验三:加入交互推理模块(精度)
- 先看看composer的推理模块
- 对人与人之间的交互进行建模,利用提取的交互信息增强个体特征,这里考虑修改DIN模块
实验四:Transformer优化(精度)
目前代码其实没有用transformer,加入transformer也可,看精度是否提升
实验五:减少计算复杂度(性能)
使用tokenizer或是maskencoder,希望结合两者的优势,看代码好改不,不好改的话用tokenizer即可(先用这个)
- Post title:实验记录05.09.2023
- Post author:sixwalter
- Create time:2023-05-09 00:00:00
- Post link:https://coelien.github.io/2023/05/09/deep-learning/第一章/实验记录5.09/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments