
C++ 面向对象
拷贝控制
类可以在创建此类型对象时做什么,类在控制该类型对象拷贝、赋值、移动或销毁时做什么。类通过一些特殊的成员函数进行这些拷贝控制操作:拷贝构造函数、移动构造函数、拷贝赋值运算符、移动赋值运算符以及析构函数。
- 难点是首先认识到什么时候需要定义这些操作
拷贝、控制和销毁
拷贝构造函数
1 | class Foo{ |
拷贝初始化
通常使用拷贝构造函数完成(有时也会使用移动构造函数)
发生在:
string s2 = "9-999999-999-99";或string nines = string(100,'9');- 将一个对象作为实参传递给非引用类型的形参
- 从一个返回类型为非引用类型的函数返回一个对象
- 用{}初始化一个数组中的元素,或一个聚合类的成员
- 某些类类型会对它们所分配的对象使用拷贝初始化:初始化标准库容器或是调用其insert、push成员
由此可以看出拷贝构造函数是极其有用的
为什么拷贝构造函数自己的参数必须是引用类型?
因为如果是非引用类型,我们必须拷贝它的实参,所以又必须调用拷贝构造函数,如此循环
拷贝初始化的限制:初始值要求使用一个explicit的构造函数来进行类型转换时,就只能直接使用,而不能隐式使用
拷贝赋值运算符
1 | class Foo{ |
- 若一个未定义自己的拷贝赋值运算符,编译器会为他生成一个合成拷贝赋值运算符:

析构函数
析构函数释放对象所使用的资源并销毁对象的非static数据成员
没有返回值,也不接受参数
销毁类类型的成员需要成员执行自己的析构函数,销毁内置类型不需要做什么
什么时候会调用析构函数?
- 变量离开其作用域时被销毁
- 对象被销毁时,其成员被销毁
- 容器被销毁时,其元素被销毁
- 对于动态分配的对象,当对它的指针应用delete运算符时被销毁
析构函数函数体自身并不直接销毁成员,是在隐含的析构阶段被销毁的
三/五法则
- 需要析构函数的类也需要拷贝与赋值操作
1 | HasPtr p("somevalue"); |
1 | HasPtr::~HasPtr(){ delete ps;} |
- 需要拷贝操作的类也需要赋值操作,反之亦然
例如一个类为每个对象分配一个唯一的序号,需要自定义拷贝赋值运算符来避免将序号赋予目的对象;
使用=default
- 显式地要求编译器生成合成的版本
阻止拷贝
- 例如,iostream类阻止了拷贝,以避免多个对象写入或读取相同的IO缓冲。
定义删除的函数
- 虽然声明了它们,但不能以任何方式使用它们
1 | struct NoCopy{ |
- 我们尽量不要删除析构成员,若删除可以动态分配这种类型的对象(但不能释放这些对象)
合成的拷贝控制成员可能是删除的
如果一个类有数据成员不能默认构造、拷贝、复制或销毁,则对应的成员函数将被定义为删除的
如果具有引用成员或是无法默认构造的const成员的类,编译器不会为其合成默认构造函数
如果一个类有const成员,则它不能使用合成的拷贝赋值运算符
对于有引用成员的类,将新值赋值给引用成员,改变的是所引用对象的值,而不是引用本身,不会与右侧运算对象指向相同的对象,不能使用合成的拷贝赋值运算符
拷贝控制与资源管理
管理类外资源的类必须定义拷贝控制成员
首先确定此类型对象的拷贝语义
类的行为像一个值
它应该有自己的状态,拷贝副本与原对象是完全独立的
类的行为像一个指针
共享状态,副本和原对象使用相同的底层数据
行为像值的类
1 | class HasPtr{ |
类值拷贝赋值运算符
- 通常组合了析构和拷贝构造函数的操作
1 | HasPtr::HasPtr& operator=(const HasPtr& p){ |
- 之所以先拷贝,再delete是为了保证:将一个对象赋予它自身时,赋值运算符需要正确工作
行为像指针的类
- 使用shared_ptr来管理类的资源(该类负责记录有多少用户共享它所指向的对象以及释放资源)
- 有时,我们希望直接管理资源:
- 使用引用计数
引用计数
- 除了初始化对象外,每个构造函数还有创建一个引用计数,用来记录目前有多少对象正在与当前正在创建的对象共享状态
- 拷贝构造函数不分配新的计数器,而是拷贝给定对象的数据成员,包括计数器,并进行递增操作。
- 析构函数递减计数器,若变为0,析构函数释放状态
- 拷贝赋值运算符,递增右侧对象的计数器,递减左侧对象的计算器,如果左侧计数器为0,意味着必须销毁状态
在哪里存放引用计数?
- 将计数器保存在动态内存中
1 | class HasPtr{ |
- 析构函数不能无条件地delete ps
1 | HasPtr::~HasPtr(){ |
- 赋值运算符必须处理自赋值
1 | HasPtr& operator=(const HasPtr& rhs){ |
交换操作
对于分配了资源的类,swap可能会是一种重要的优化手段
- 一般我们交换两个类值HasPtr的代码可能如下:
1 | HasPtr temp = v1; |
这种赋值实现的交换存在多次动态内存分配
- 我们更希望swap交换指针,而不是分配新副本:
1 | string *temp = v1.ps; |
- 编写自己的swap函数来重载默认行为:
1 | class HasPtr{ |
- 在赋值运算符中使用swap
拷贝和交换技术
1 | HasPtr& HasPtr::operator=(HasPtr rhs){ |
自动是异常安全的,且能处理自赋值
动态内存管理类
设计简化版的vector
1 | class StrVec{ |
1 | void StrVec::push_back(const string &s){ |
- 用allocator分配内存时,必须记得内存是未构造的(原始内存);
alloc_n_copy成员
1 | std::pair<std::string*, std::string*> |
- pair.first:指向分配的内存的开始位置
- pair.second:指向最后一个构造元素之后的位置
free成员
1 | void StrVec::free(){ |
拷贝控制成员
1 | StrVec::StrVec(const StrVec &s){ |
移动构造函数和std::move
- 将资源从给定对象移动,而不是拷贝到正在创建的对象
reallocate成员
1 | void StrVec::reallocate(){ |
对象移动

进行不必要的拷贝代价很高,所以引入了移动的概念
右值引用
- 必须绑定到右值的引用(窃取状态)
- 不能将一个右值绑定到左值上
1 | int i = 42; |
- 左值持久,右值短暂
右值只能绑定到临时对象:要么将要被销毁,要么该对象没有其他用户
使用右值的代码可以地接管所引用对象的资源
标准库move函数
- 可以显式地将一个左值转换为对应的右值引用类型
- 通过move来获得绑定到左值上的右值引用
1 | int &&rr3 = std::move(rr1); |
- 我们可以销毁一个移后源原对象,也可以赋予他新值,但不能使用其值
移动构造函数和移动赋值运算符
- 必须记得将原对象的资源置为NULL,否则析构时会释放掉我们刚刚移动的内存
1 | StrVec::StrVec(StrVec &&s) noexcept:elements(s.elements),first_free(s.first_free),cap(s.cap){ |
- 移动操作窃取而不分配任何资源,所以通常不会抛出任何异常
- 必须显式告诉标准库我们的移动构造函数可以安全地使用:noexcept
1 | StrVec& StrVec::operator=(StrVec && rhs) noexcept{ |
移后源对象必须可析构,用户不能对其值进行任何假设
合成的移动操作
定义了一个移动构造函数的类也必须定义自己的拷贝操作,否则这些成员默认地被定义为删除的
移动右值,拷贝左值
当既有移动构造又有拷贝构造时,编译器使用函数匹配规则来确定使用哪个:
不能隐式的将右值引用绑定到一个左值
but we could bind const lvalue reference to rvalue
1 | const auto& ptr3 = ptr + 5; // correct! const save us a lot! |
如果没有移动构造函数,右值也会被拷贝

- 因为我们可以将Foo&&转换为一个const Foo&,所以可以使用拷贝构造函数
拷贝并交换赋值运算符
拷贝并交换挺有意思的
1 | HasPtr::HasPtr(HasPtr &&p) noexcept: ps(p.ps), i(p.i){ |
- 这时,如果右侧运算对象是一个右值引用,会调用移动构造函数
- 这时,如果右侧运算对象是一个左值,会调用拷贝构造函数
- swap会交换两个运算对象的状态
RULE of FIVE:所有的五个拷贝控制成员应该被看作一个整体
移动迭代器
1 | void StrVec::reallocate(){ |
使用
uninitialized_copy来构造新分配的内存比循环更简单。移动迭代器会解引用出右值引用:
1 | void StrVec::reallocate(){ |
注:不要随意使用移动操作,只有当你确信需要且是安全的,才可以使用std::move
在成员函数中使用右值引用
1 | void push_back(const X&); |
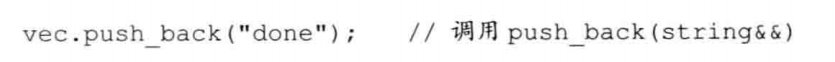
引用限定符
阻止向右值进行赋值,强制左侧运算对象是一个作值
1 | Foo &operator=(const Foo&) &; |
- 可以用来区分重载版本

- 编译器会通过对象的左值右值属性来确定使用哪个版本

重载运算与类型转换
为什么要重载运算?
使得程序更易于编写和阅读,不用的话,冗长而不清晰,示例如下:

可以被重载的运算符

- 尽量使用与内置类型一致的含义(返回值也要兼容),首先应该考虑这个类提供哪些操作
- 执行IO操作
- 检测相等性
- 包含内在的单序比较
何时选择为成员,何时为非成员?
- =,【】,(),->必须是成员
- 改变对象状态的运算符或者与给定类型密切相关的运算符,如递增递减,通常为成员
- 具有对称性的运算符,如算数,相等性,关系,位运算通常是普通的非成员函数
输入输出运算符
重载输出运算符
1 | ostream &operator<<(ostream &os, const Sales_data &item){ |
- 输出运算符尽量减少格式化操作:使得用户 有权控制输出的细节
- 必须是非成员函数,而且一般被声明为友元
重载输入运算符
1 | istream &operator>>(istream &is, Sales_data &item){ |
输入运算符必须处理输入可能失败的情况
当发生读取操作错误时,输入运算符应该负责从错误中恢复
算数和关系运算符


相等运算符
- 若有判等操作,应该定义
- 更容易使用标准库和算法
- 相等运算符和不等运算符中的一个应该把工作委托给另一个
赋值运算符
- 第三种赋值运算符:
1 | vector<string> v; |
下标运算符
通常会定义两个版本:
- 返回普通引用
- 返回常量引用
1 | class StrVec{ |
面向对象程序设计
基于三个基本概念:数据抽象、继承和动态绑定
为什么要使用继承和动态绑定?
- 可以更容易地定义与其他类相似但不完全相同的新类
- 再用这些彼此相似的类进行编程时,可以一定程度上忽略它们的区别,以统一的方式使用它们的对象
一个适合OOP好的例子
- 书店中不同书籍的定价策略可能不同。
- 打折、原价、超过数量打折、前多少打折
基类和派生类
虚函数
- 基类希望它的派生类自定义适合自身的版本
- 派生类必须对虚函数进行声明,可以显式注明它将使用哪个成员改写基类的虚函数:
1 | double net_price(std::size_t) const override; |
动态绑定
- 能使用同一段代码分别处理Quote和Bulk_quote的对象


- 根据实际传入item的对象类型决定执行net_price的哪个版本

访问控制
派生类能访问基类的共有成员、保护成员, 但不能访问私有成员
派生类到基类的类型转换
可以将基类的指针或引用绑定到派生类对象中的基类部分:

- 如图,Bulk有两个子对象。
派生类的声明
- 包含类名,但不包含它的派生列表
1 | class Bulk_quote; |
派生类构造函数
- 派生类必须使用基类的构造函数来初始化它的基类部分
- 首先初始化基类的部分,然后按照声明的顺序依次初始化派生类的成员
遵循基类的接口
- 每个类负责定义各自的接口
- 派生类不要直接初始化基类的成员
静态成员的继承
- 整个继承体系只存在该成员的唯一定义
类型转换和继承
静态类型与动态类型
1 | Bult_quote bulk; |
- Quote& 为静态类型
- Bulk_quote为动态类型
- 引用或指针的静态类型和动态类型不同正是c++支持多态性的根本所在
不能将基类隐式转换为派生类
但是如果确定是安全的,可以用static_cast来强制转换(不推荐)
在对象之间不存在类型转换

- bulk的Bulk_quote部分被切掉了

虚函数
- 对非虚函数的调用在编译时进行绑定,通过对象进行的函数调用也在编译时绑定
- 当且仅当通过指针或引用调用虚函数时,才会在运行时解析该调用。
override和final说明符
c++11中可以使用override说明符来说明派生类中的虚函数。
- 使得意图更加明确
- 让编译器为我们发现一些错误
若定义为final,任何尝试覆盖该函数的操作都将引发错误

回避虚函数的机制
- 通常当一个派生类的虚函数调用它覆盖的基类的虚函数版本时会需要回避
- 否则会导致无限递归(被解析为对自身的调用)
抽象基类
含有纯虚函数的类是抽象基类:
1 | class Disc_quote: public Quote{ |
我们不能直接创建一个抽象基类的对象
加入Disc_quote是重构的典型示例
访问控制与继承

派生访问说明符目的是控制派生类用户对于基类成员的访问权限
1 | struct Priv_Derv: private Base{ |
意思是说base的所有成员对于派生类的用户来说都是不可访问的
派生类内对基类成员的访问权限只与基类中的访问说明符有关
但是派生类的派生类会受到派生访问说明符的影响:
1 | struct Derived_from_Private: public Priv_Derv{ |
派生类向基类转换的可访问性
- 只用公有继承,用户代码才可以使用派生类到基类的转换
- 无论什么继承,D的成员函数都可以使用派生类到基类的转换
- 公有和受保护的继承,D的派生类的成员和友元可以使用派生类到基类的转换

友元与继承
- 友元关系不能继承也不能传递

- 尽管看起来有点奇怪,但f3是正确的:如果Base对象内嵌在其派生类对象中也是OK的
可以改变个别成员的可访问性

- 通过using声明,我们可以将该类的直接或间接基类中的任何可访问成员标记出来
默认的继承保护级别

- 唯一差别是默认成员访问说明符和默认派生访问说明符
- struct默认public继承
- class默认private继承
继承中的类作用域
- 派生类的作用域位于基类作用域之内(有意思的是派生类和基类的定义相互分离)
- 名字解析过程:

- 我们能使用哪些类型仍然是静态类型决定的
1 | Bulk_quote bulk; |
尽管在bulk中确实含有一个discount_policy成员,但是该成员对于itemP确实不可见的。因为Quote不包含该成员,所以无法通过Quote的引用或指针调用它
在内层作用域重新定义外层的名字可以隐藏同名的基类成员,使用
Base::mem可以使用被隐藏的成员
名字查找先于类型检查
- 声明在内层作用域的函数不用重载声明在外层作用域的函数,如果同名,会隐藏该基类成员

- 因为解析的时候会先进行名字查找,而派生类已经定义了,所以查找会终止
虚函数与作用域
如果基类与派生类虚函数接受的实参不同,是无法通过基类的引用或是指针调用派生类的虚函数的
非虚函数不会进行动态绑定,实际调用的函数版本由指针的静态类型决定
覆盖重载的函数
如果派生类希望所有的重载版本对他都是可见的,那么它就需要覆盖所有版本或者一个都不覆盖
为重载的成员提供一条using语句指定名字即可,这样就无需覆盖基类中的每一个重载版本了,对派生类没有重新定义的重载版本的访问实际上是using声明点的访问。
构造函数与拷贝控制
虚析构函数
- 动态分配继承体系中的对象,应该将析构函数定义为虚函数
1 | class Quote{ |
- 析构函数的虚属性会被继承,所以只要析构函数是虚函数,就能确保我们delete指针时,运行正确的析构版本
合成拷贝控制与继承

- 如果基类中的默认构造、拷贝构造、拷贝赋值或析构是删除的,则派生类中对应的成员将是被删除的
- 如果我们需要执行移动操作,应该首先在基类中去定义

派生类的拷贝控制成员
- 当派生类定义了拷贝或是移动操作时,该操作负责拷贝或移动包括基类部分成员在内的所有对象

- 派生类赋值运算符:
1 | //Base::operator=(const Base&) |
- 派生类析构函数:只需要销毁派生类自己分配的资源
- 在构造函数和析构函数中调用虚函数:如果这么做了,则我们应该执行与构造函数或析构函数所属类型相对应的虚函数版本。
继承的构造函数
- c++11新标准中,构造函数是可以继承的
- 一个类只继承其直接基类的构造函数
1 | class Bulk_quote: public Disc_quote{ |
- 作用于构造函数时,using语句令编译器产生代码。对基类的每一个构造函数,编译器都生成一个对应的派生类构造函数。形如:
derived(params):base(args){}

- 定义在派生类中的构造函数会替换继承而来的构造函数
容器与继承

在容器中放置(智能)指针而非对象

- 在第二个push_back中,传入的是Bulk_quote类型的智能指针。c++会把派生类的智能指针转换为基类指针(自动转换)
编写Basket类
- 对应C++面向对象编程来说,我们无法直接使用对象进行面向对象编程,而是必须使用引用和指针(有点好笑)
- 经常定义一些辅助类来处理这种复杂情况(涉及指针)
回顾下之前的类定义:





1 | class Basket{ |
multiset保存多个报价,按照compare成员排序
total_receipt将购物篮中的内容逐项打印成清单,并返回购物篮中所有物品的总价格
1 | double Basket::total_receipt(std::ostream& os) const{ |
- upper_bound可以令我们跳过与当前关键字相同的所有元素,他返回一个迭代器,指向所有与iter相等的元素中最后一个元素的下一个位置
- print_total调用了虚函数,其结果依赖于**iter的动态类型
隐藏指针
目前Basket的用户依然必须处理动态内存:
1 | Basket bsk; |
下一步修改add_item,让Basket进行内存分配:
1 | void add_item(const Quote& sale); |
但是问题是,add_item不知道要分配的类型,所以如下的分配是有误的:
1 | new Quote(sale) |
如果sale实际指向的是Bulk_quote对象,那么该对象将被迫切掉一部分
模拟虚拷贝
1 | class Quote{ |
- 尽管sale类型是右值引用类型,但是sale本身是个左值,因此用move把一个右值引用绑定到sale上
文本查询程序再探
初始版本
实现需求
在一个给定文件中查询单词,查询结果是单词在文件中出现次数及其所在行的列表:


数据结构
从定义一个保存输入文件的类开始:TestQuery
vector用来保存输入文件的文本
map用来关联每个单词和它出现的行号set
这个类里有个执行查询的操作:查找map,检查给定的单词是否出现,涉及这个函数的难点是应该返回什么内容,我们需要知道它出现了多少次,行号,以及每行的文本。
返回这些内容的最简单的方法是定义另一个类:QueryResult来保存查询结构,该类有一个print函数,完成结果打印工作。
先编写使用这个程序的类:

文本查询程序类的定义

- QueryResult需要共享保存输入文件的vector和保存单词关联的行号set
TextQuery构造函数

- 调用reset更新lines引用的shared_ptr,并使其指向这个新分配的set
QueryResult类


query函数

- 使用find而不是下标可以避免将单词添加到wm中
打印结果


优化版本
实现功能
单词查询:得到匹配某个给定string 的所有行
逻辑非查询:得到不匹配查询条件的所有行
逻辑或查询:返回匹配两个条件中任意一个的行
逻辑与查询:返回全部匹配两个条件的行
同时可混合使用:如
fiery & bird | wind
面向对象解决方案
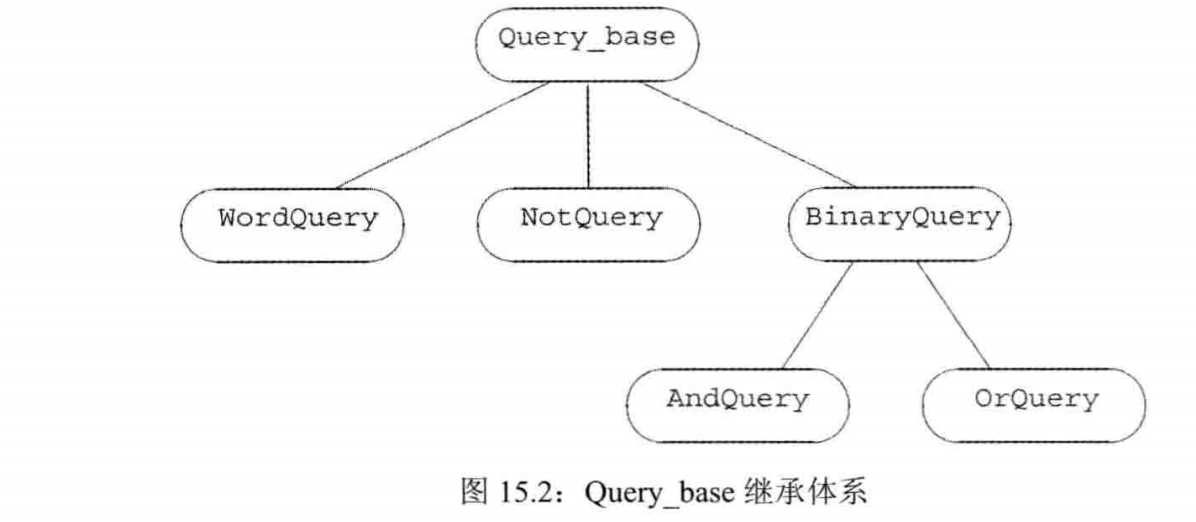
将不同查询建模成相互独立的类:
- WordQuery
- NotQuery
- OrQuery
- AndQuery
它们共享一个公共基类
它们只包含两个操作:
- eval:接受一个TextQuery并返回一个QueryResult
- rep:返回基础查询的string表示形式
抽象基类
将层次关系隐藏于接口类中
- 首先必须建立查询命令,可以使用如下代码,来实现之前描述的复合查询:
1 | Query q = Query("fiery") & Query("bird") & Query("wind"); |
- 我们会定义一个接口类Query,隐藏整个继承体系。它将保存一个Query_base指针,该指针绑定到Query_base的派生类对象上。eval用于求查询的结果,rep用于生成查询的string版本
- 用户通过Query对象的操作间接地创建并处理Query_base对象
- &运算符生成一个绑定到新的AndQuery对象上的query对象
- |运算符生成一个绑定到新的OrQuery对象上的query对象
- ~运算符生成一个绑定到新的NotQuery对象上的query对象
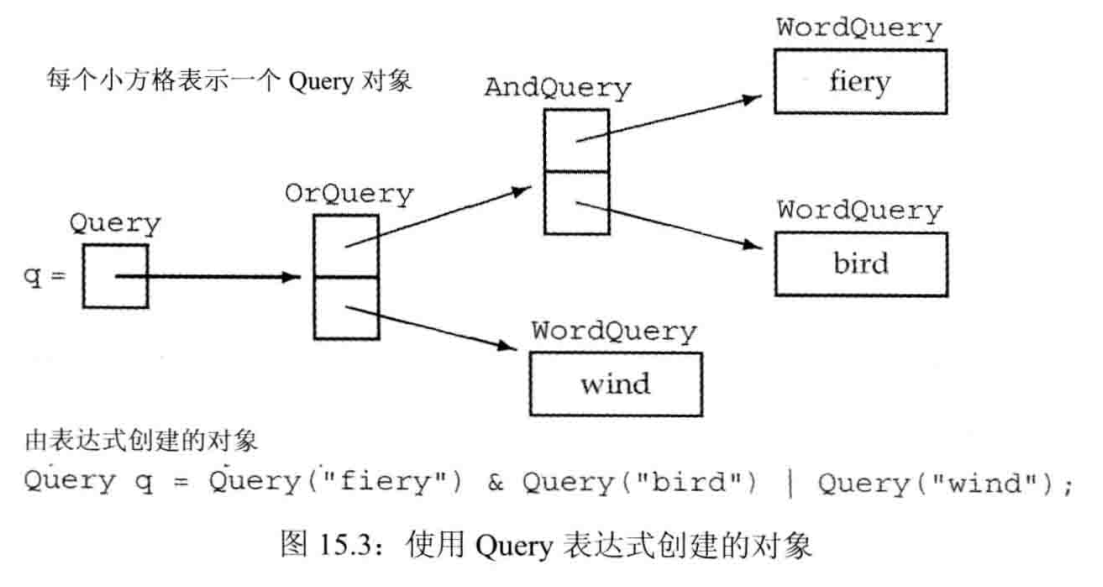
类工作机理
- 构建代表用户查询的对象是该应用程序的核心
代码实现
Query_base类
1 | class Query_base{ |
- 我们不希望用户或是派生直接使用querybase,所以没有public成员
Query类
1 | class Query{ |
Query的输出运算符

WordQuery类
1 | class WordQuery: public Query_base{ |
1 | inline |
NotQuery类
1 | class NotQuery: public Query_base{ |
- Post title:C++ 面向对象
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/coding-solution/c++ primer_OOP/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.