
并行软件设计—以“质数并行筛选”为例
并行编程
为什么要并行编程?
主进程可以在子进程执行的时候执行其他事务,提高时间效率。这个想法可以分为三个部分:
- 过程(process):在子进程执行的同时,推进自己的计算
- 通信(communication):从独立执行的子进程中获取result
- 同步(synchronization):等待子进程的结束
一旦我们能分离出子进程(子任务),就可以使用RPC来远程运行
进程本质上是一个函数,但是它有自己的内存空间,以及私有栈。我们能对函数做些什么呢?
- 调用(call)
- 调用并且独立执行(fork一个子进程,在子进程中执行)
- 用目标函数替换当前的计算(进程被替换了,exec in Unix,shell执行命令执行的就是这种策略)
- 函数A可以调用函数B,AB可以相互切换(协程,linux pipelines, 操作系统调度器都使用了这种策略)
本篇博客主要关注于第二点:调用并且独立执行
并行模型
进程管理
进程创建
1 | begin func(arg) |
- 创建一个进程,arg是传给新进程的参数(传递新进程信息最好的方式)
- 父进程的下一条指令会和子进程的第一条指令并行执行
进程终止
- 从func返回
- 调用显示的进程终止函数
通信通道(Communication Channels)
有点像pipelines,可以用pipe为例来思考
1 | c: channel of [int]; |
- 向通道发送一个数据:
c1 <- = val - 从通道接受一个数据:
x= <- c1
同步原理
如果发送方发送数据,但是没有接收方接受数据,发送方直到接收方接收之前会被阻塞
如果接收方接受数据,但是没有发送方发送数据,接受方知道发送方发送之前会被阻塞
其他同步模型还有很多:信号量,Condition variables ,spin lock , queued lock
Unix实现pipelines
它实现了上述提及的编程模型中的Communication Channels
- 使用了buffering的概念
- 发送进程会将其输出保存在buffer中
- 当接收进程准备好读数据时,pipeline的下一个进程从buffer中读取数据
- 当buffer被填满时,发送进程会被阻塞,直到接收进程将数据从buffer中移出
- Linux默认的buffer大小为65536字节(64KB)
实例应用:primes (moderate)/(hard)
动机(motivations):
为什么要做该实例?
这个MIT偏hard难度的作业题要想独立解决真的不简单,它用到了递归的思想,同时也要注意进程的退出条件,以及文件描述符的正确使用(文件描述符数量有限)
该实例是对Linux pipelines并行编程的比较好的实践,需要去仔细处理进程通信以及同步
题目介绍:
使用管道pipelines对小于35的质数进行筛选(可以并行筛选处理)
算法框架:
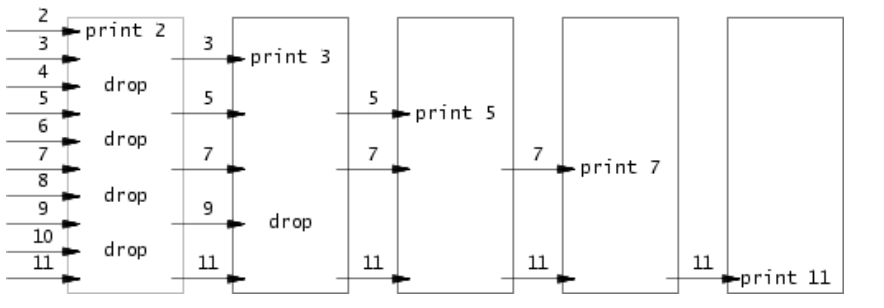
生成进程负责生成所有待筛选的数,之后的每个进程负责筛质数(这个筛的过程是并行的)。比如第一个子进程筛掉所有2的倍数,第二个并行的进程(子孙进程)筛掉所有3的倍数,以此类推。
解决方法:
对于这个问题的解决其实是一步步的,较为复杂的问题需要我们一点点去调试纠错
version 1
这个版本的实现可以看出父进程并没有等待子孙进程的退出(即没有处理好同步)
version 2
父进程等待子进程退出,但是子进程没有正确退出,即wait()卡死了
Final version 3
经过两个多小时的不懈努力终于解决
处理好递归终止条件是解决这个题的关键:即我们需要处理好最后一个没有子孙进程的进程的正确退出
这里使用函数(在函数中fork)来处理这个问题:
- 一方面:利用了递归的思想,不需要编写重复代码
- 另一方面:体现了进程的本质即函数的思想
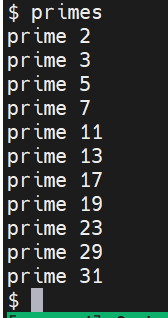
运行效果:
代码如下:
1 |
|
- Post title:并行软件设计—以“通过流水线管道pipes对质数进行并行筛选”为例
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/course-learning/MIT6.S081/lab1/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.