
MIT6.S081 tips:常用工具
工欲善其事,必先利其器
C pointers
preps
1 | int a[4]; |
Q1
1 | printf("1: a = %p, b = %p, c = %p\n", a, b, c); |
answer:
- 1: a = 0x7ffdd2edd3f0, b = 0x56411ea742a0, c = 0x7ffdd2edd889
Q2
1 | c = a; |
answer:
- 2: a[0] = 200, a[1] = 101, a[2] = 102, a[3] = 103
Q3
1 | c[1] = 300; |
answer:
- 3: a[0] = 200, a[1] = 300, a[2] = 301, a[3] = 302
Q4
1 | c = c + 1; |
answer:
- 4: a[0] = 200, a[1] = 400, a[2] = 301, a[3] = 302
Q5
1 | c = (int *) ((char *) c + 1); |
answer:
5: a[0] = 200, a[1] = 400, a[2] = 500, a[3] = 302
wrong! this answer is much more difficult
5: a[0] = 200, a[1] = 128144, a[2] = 256, a[3] = 302
why a[1] = 128144, a[2] = 256? 这个题对于不懂大小端以及指针的人来说挺难的
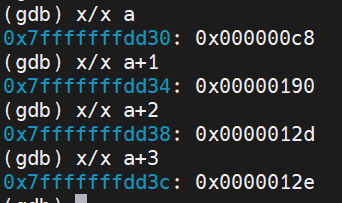
如上图,其实是以大端的方式存储的(方便查看内容),但是其实在该计算机中实际以小端存储:
(以a[0]-a[2]为例)c8000000 90010000 2d010000…
c实际上是:

也就是修改*c,会修改加粗部分的内容c8000000 90010000 2d010000…(整体向后偏移1字节,因为char大小为1字节),修改后为:c8000000 90f4010000 00010000…,转换为大端表示如下图所示:
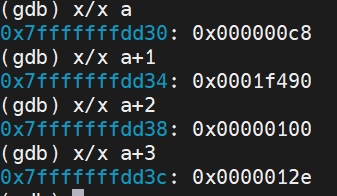
Q6
1 | b = (int *) a + 1; // a+4 |
answer:
- 6: a = 0x7fffac3d88e0, b = 0x7fffac3d88e4, c = 0x7fffac3d88e1
git
从有向无环图去理解git的原理: 一个git 仓库永远仅仅只是一个DAG和它的便利贴(branch 可以移动,tag则不行)
Storage
git 对象存储 仅仅只是 对象的有向无环图, 它们通过SHA-1哈希来压缩和识别
blob

- 最简单的对象,字节的集合。通常是一个文件,但也可以是一个符号链接或是其他任何东西。
tree

- 目录由tree进行表示。他们指向的是file blobs 或 是其他的trees(子目录)
commit

- 一个commit指向一个代表提交时刻文件状态的tree,它还可以指向0~n个其他的父commits,如果父commits多于一个意味着该commit是merge,没有父commit意味着是初始提交。
refs
references, heads or branches

- refs就像一个节点的便利贴一样,或是书签,表示“我在该节点工作”
- git commit 在有向无环图中加入一个新的节点,并将当前分支的便利贴移动到最新的节点
- HEAD ref比较特殊,因为它实际上指向另一个ref(指向当前正在活跃的branch)
remote refs

- 远程ref在不同的namespace下,并由远程服务器控制,git fetch可以更新它们
tag

- tag既是有向图中的节点,又是一个便利贴,它指向一次提交(不会移动的便利贴)
History
how to manage history?
simplest repo

fetch one from remote

git merge remote

git commit and git fetch later

git merge remote

- wasn’t fast-forward
- a new commit node was create(e)
a few commits on both branches and another merge

- DAG records exactly what the history of actions taken was
rebase

- your commit is replaced by another commit with a different parent, and your branch is moved there.
- the d is still here, not removed:

rebase multiple commits

script
为什么用script?
script是用来记录一个terminal session中发生的所有事情的
session的所有都可以被回放(replay),但需要timing log file的支持,详见scriptreplay
当print语句很多时,我们想要搜索我们关注的部分,可以把所有的console输出到一个文件中方便我们查找,别忘了记录完要exit哦
用法:
script [options] [file]
选项:
- -a:追加输出到文件
- -c:运行命令
- -f:每次写之后刷新输出
- -T: 记录时间信息到文件中
- -I:记录输入到文件
- -O:记录输出到文件
退出:
exit
展示:
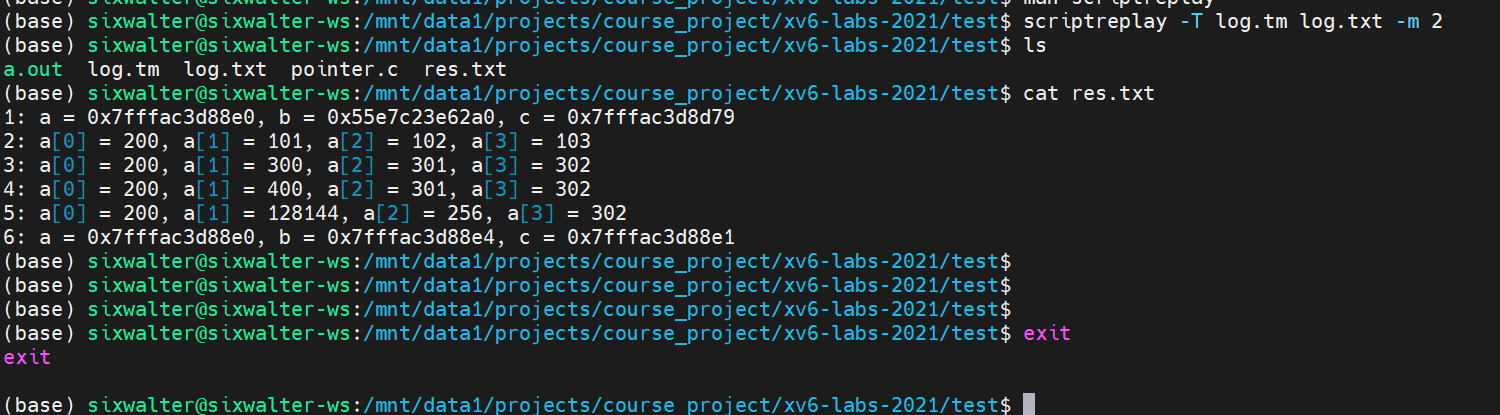
addr2line
当内核出现错误,它会打出一个错误信息,里面包含程序计数器的值。可以使用addr2line将程序指令地址转换为所对应的函数名、以及函数所在的源文件名和行号。
例如,我们写一个错误程序:
1 |
|

查看系统日志的错误信息发现,就是出错时所执行的位置。使用addr2line将程序指令地址进行转换,但是出现了显示??:的问题
我试了好久,原来是每次程序运行时其VA(虚拟地址都是不同的),所以需要指定其偏移而不是绝对地址。那么是关于哪一个section的偏移呢?我试验了使用text是有问题的,即得不到正确的错误代码所在的行号:

实际上错误代码所在行号为5,而不是18;
为此,我查阅了资料,发现**/proc/id/maps** 对于正确使用addr2line很有帮助。
use /proc/id/maps to view the virtual address space of a particular process.
Segment Types
- Code segments
- Data segments
- Stack segments
- Shared libraries segments
Segment Permissions
- read-only (r) means that the segment is readable, hence all segments usually have that mode
- read-write (w) means that the segment is readable and writeable to allow for data modification
- execute (x) means that the segment contains executable code
- private (p), which means that the segment is private, thus only visible from that process
- shared (s), which means that multiple (at least 2) processes share that segment
Understanding Output
1 | <address start>-<address end> <mode> <offset> <major id:minor id> <inode id> <file path> 559b8c418000-559b8c41a000 r--p 00000000 08:30 1708 /usr/bin/cat |
- address start – address end is the start and end address of that mapping. Note that the whole output is sorted based on those addresses, from low to high.
- mode (permissions) specifies which actions are available on this mapping and if it’s private or shared.
- offset is the start offset in bytes within the file that is mapped. This only makes sense for file mappings. For instance, stack or heap mappings are examples of mappings that aren’t files, and in those cases, the offset is 0. In the above example, the mapping is of the /usr/bin/cat file, and the offset is 0.
- major:minor ids represent the device that the mapped file lives in the form of a major and minor id. In the above example, 08:30 represents the major and minor id of the hard drive that has the root filesystem. For non-file mappings, this column shows 00:00*.*
- inode id of the mapped file (again, that’s only valid for file mappings). Inodes are data structures that contain the core filesystem-related metadata. When it comes to non-file mappings, this field is set to 0. In our example, this id is 1708.
- The file path of the file for that mapping. In the event that this is not a file mapping, that field is empty.
Used in Code
1 | char buff[64] = {0x00}; |
objdump
还有一个工具对使用addr2line也很用帮助: objdump
用法: objdump -d a.out
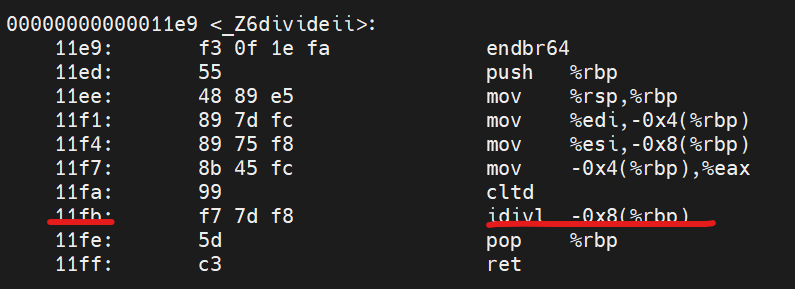
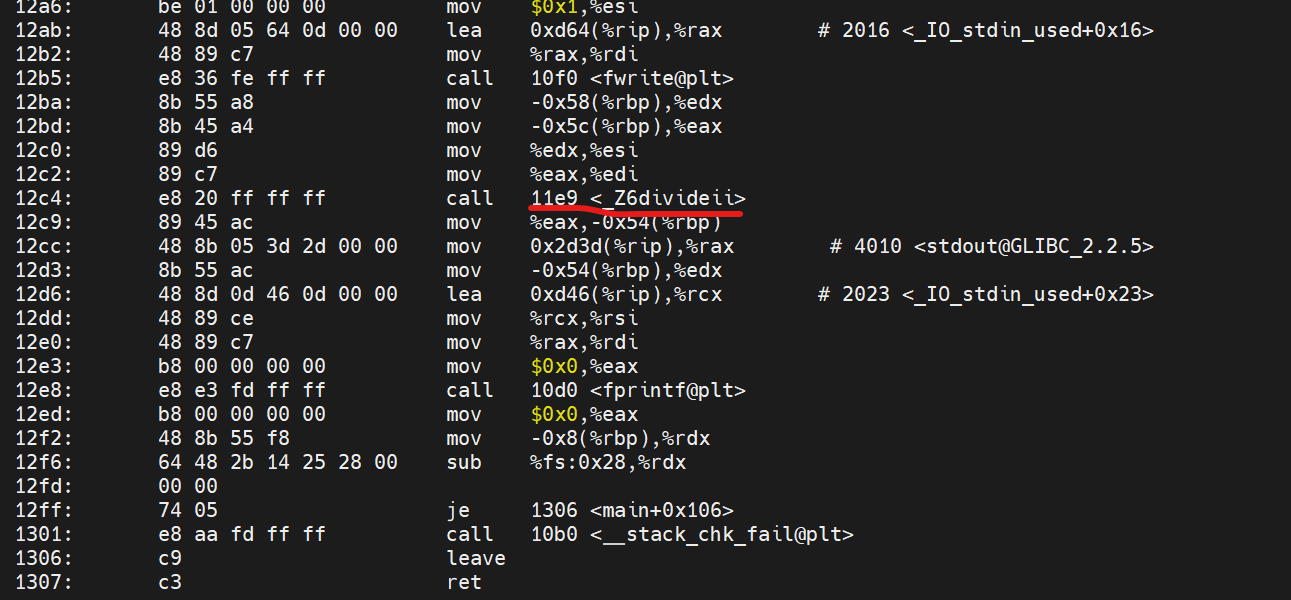
然后,可以发现 0x11fb终于显示出来正确的错误行数:

由此我们可以发现,VA对我们使用addr2line找bug作用极小,因为程序是动态加载的,VA是不断变化的,只有偏移是不变的。

所以,只有找到偏移才对我们使用addr2line有用。由sprintf(buff, "cat /proc/%d/maps", getpid());打印出:
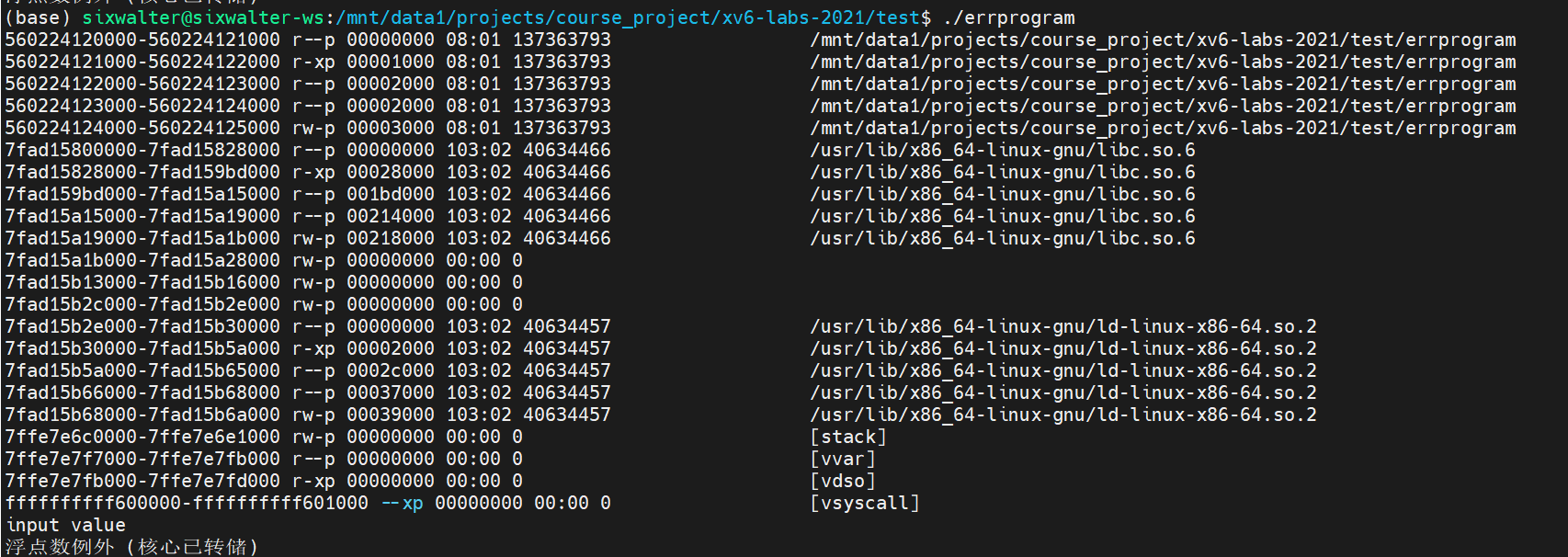
我们可以看出text段是在(560224121000-560224122000),它的offset是1000,所以可以找到偏移地址为11fb。最后使用addr2line可以显示出正确行数:
GDB
start QEMU with GDB
- make qemu[-nox]-gdb, then start GDB in a second shell
Breakpoints
break <location>
location can be address, or names(mon backtrace , monitor.c:71 )
Watchpoints
watch <expression>
stop execution whenever the expression’s value change
watch -l <address>
will stop execution whenever the contents of the specified memory address change
p.s. what ‘s the difference between ‘wa var and wa -l &var ?
rwatch [-l] <expression>
will stop execution whenever the value of the expression is read
Examining
x/x for hexadecimal, x/i for assembly
x prints the raw contents of memory in whatever format you specify
print
evaluates a C expression and prints the result
info registers
prints the value of every register
info frame
prints the current stack frame
list <location>
prints the source code of the function at the specified location
backtrace
- Post title:MIT6.S081 tips:常用工具
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/course-learning/MIT6.S081/tools_learning/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.