
Large-scale Video Classification with Convolutional Neural Networks
这一篇论文因其经典性,着重探索的各种模型的连接性,讨论如何更好地去获得时间信息,可以说是之后的C3D,Res3D,R(2+1)D的思想的先驱,有较大的参考价值,故阅读并写下笔记。
Introduction
这篇文章的研究背景是利用CNN在大规模视频数据集上进行分类。此时的网络将不只能够接触到静态表观信息,还能够接触到复杂的时序变化信息。这篇文章研究了扩展CNN在时间域上的连接性的诸多方法,这些方法有效利用了局部时空信息。文章还提出了一种能够加速训练的多分辨率方法。
数据集
论文首先从实践的角度,判断当时没有合适的视频分类基准数据集。为了获取足够充分的数据来训练CNN,作者团队自己采集了名为Sports-1M的数据集。
建模
从建模的角度,作者以问题为导向,分析了在CNN中,什么样的时间连接模式在捕获视频中的局部运动信息是最佳的;而这些额外的运动信息是如何影响模型的预测的;它对预测效果的提升究竟有多大。作者尝试了在时间域中结合信息的不同方法。
计算
从计算的角度,因为训练CNN需要优化数百万参数,非常消耗时间,提高计算能力,对于大型网络结构较为重要。如上图所示,作者提出了双流法,将处理过程分为了两个结构相同的场景流和中心流。场景流学习低分辨率帧的特征,而中心流只学习图像中心的特征。使用这种方法大大提高了计算速度,同时对网络的性能几乎没有影响。
核心亮点
真知灼见:预测未来模型的发展是具有泛化性的Deep model on Large data
上千万的参数量的大模型,以及大规模的标注数据集能够给出state-of-arts结果。为了模型的泛化能力,作者研究了CNN在大规模数据集上的表现,并通过迁移学习,看它在更小的数据集上的泛化效果如何
temporal connectivity pattern 时序连接模式
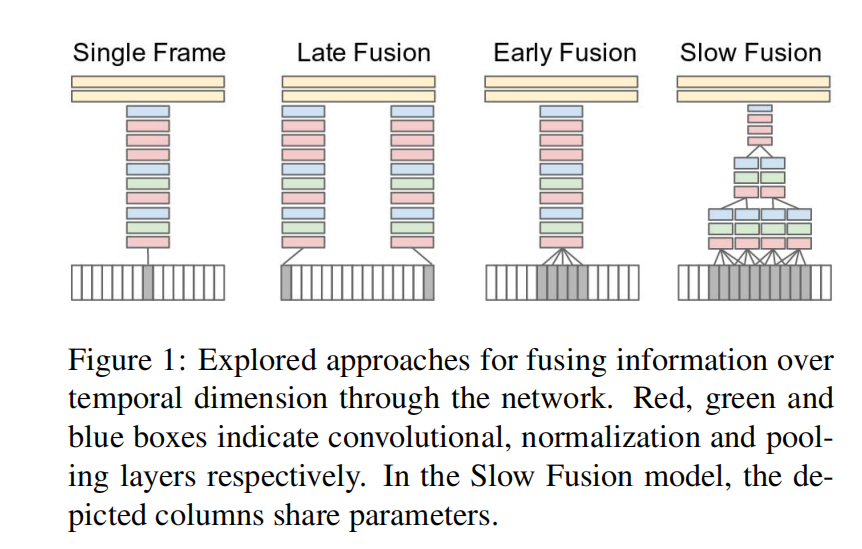
- single frame model
如上图所示,最左边的single frame模型是baseline模型,而右边的三种不同时间融合方式的模型是它的扩展。baseline模型只提取了视频中的静态表观信息;这个对照主要是为了判断静态表观信息对分类的影响。其网络结构为:C(96, 11*,* 3)-N-P-C(256, 5*,* 1)-N-P-C(384, 3, 1)- C(384, 3*,* 1)-C(256, 3*,* 1)-P-FC(4096)-FC(4096),
- late fusion model
第二个late fusion模型设置了两个平行的且共享参数的single-frame网络,这两个相隔15帧的流在第一个全连接层中进行汇聚;第一个全连接层可以计算全局运动特征。
- early fusion model
early fusion在像素级别上就将整个时间窗口上的多帧信息进行融合,这时其第一个卷积层的过滤器的shape就变为了$11113*T$,实际上所做的就是3D卷积;论文说early fusion的连接可以允许网络精确地检测运动方向和速度。
- slow fusion model
slow fusion结合了前两种方法,在整个网络中缓慢地融合时间信息,这样高层能同时获取较为同步的全局时空信息,整个表观特征的提取和时序信息的提取是同时进行的。这个方法参照了3D卷积网络2013年的文章,前三个卷积层都是3D卷积,后面两个为2D卷积
多分辨率CNN
为了改进运行时性能,作者改善了网络结构,但同时不影响其精度。
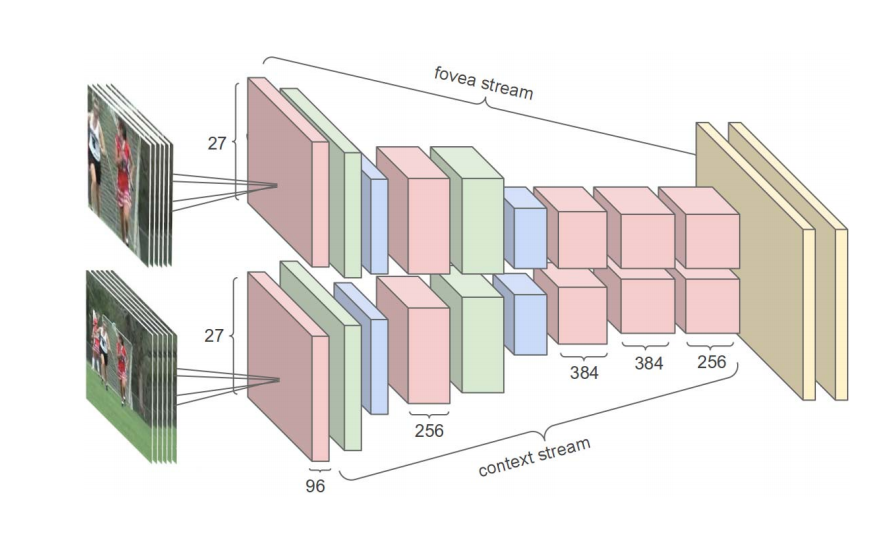
如上图所示,为了试验不同的网络结构和不同的超参,作者提出了双流法,将处理过程分为了两个结构相同的场景流和中心流。这种双流方法改变了网络结构,但缩减了运行时间的同时又没有牺牲性能。场景流学习低分辨率帧的特征,而中心流只学习图像中心的特征。使用这种方法将帧分辨率从$178178
学习过程
优化
它使用的优化算法为 Downpour Stochastic Gradient Descent,可以参考查看这篇文章(Large scale distributed deep networks,NIPS 2012)
数据增强和预处理
首先,裁剪所有图片到中央区域,放缩图片到$200200
170170$的区域,最终以50%的概率对图片进行水平随机翻转,并进行中心化
实验结果
对比实验
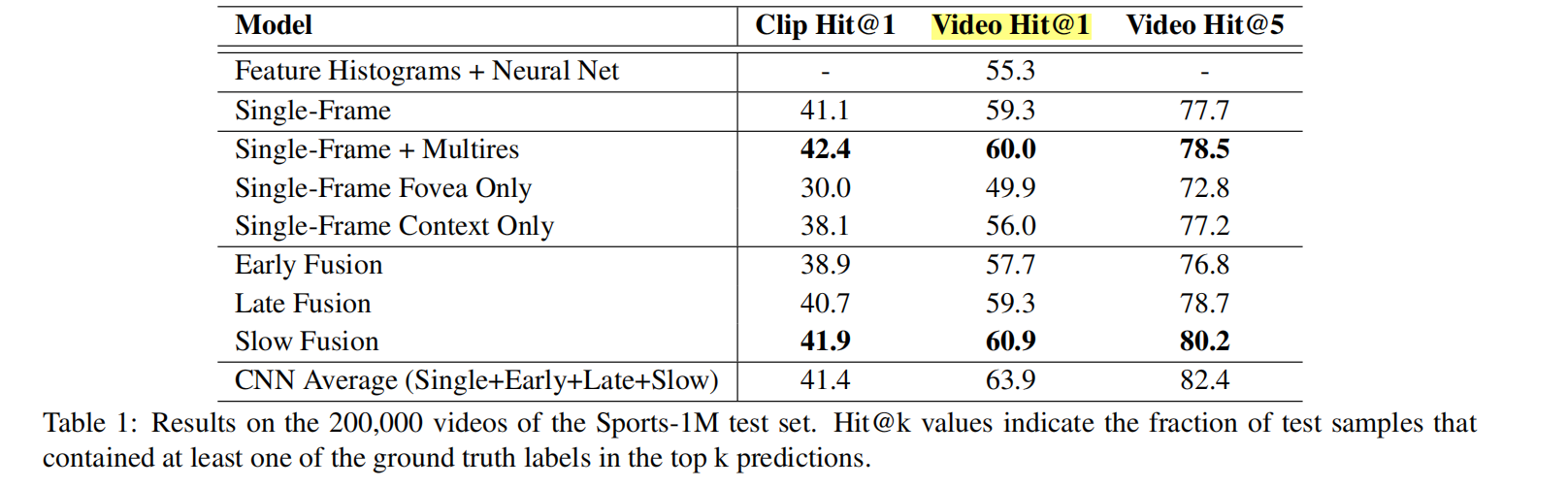
这个实验令人惊异的是不同的架构对于精度的影响不大(抱有怀疑),但是slow fusion效果最好是有目共睹的
运动信息对实验的影响
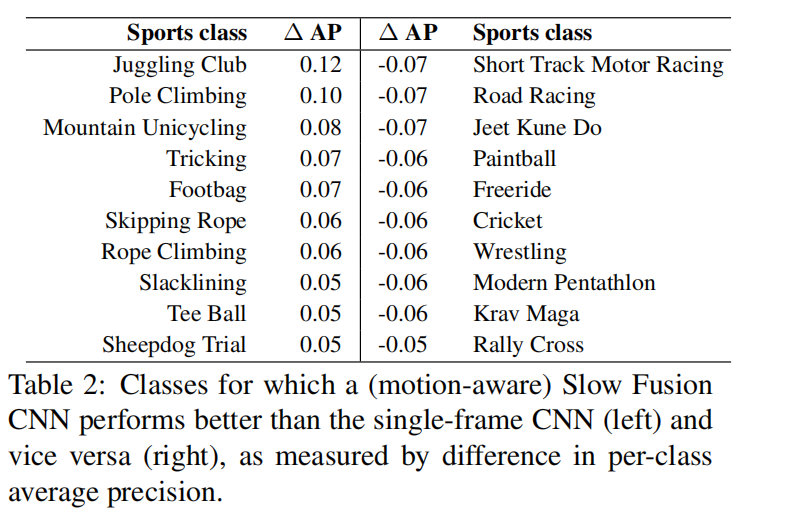
有意思的是,比起singleframe,slowfusion对于类别的预测有部分很好,都也有部分比singleframe要弱,这些较弱的部分一般都有相机运动的存在。
对于第一个卷积层filters的可视化

可见,场景流主要学习的是颜色特征,而中心流主要学的是高频率的灰度细节特征。
混淆矩阵的研究
通过对混淆矩阵的研究发现,大部分分类错误都来自数据集的细粒度类别,模型对于细粒度的行为分类效果较差
迁移学习
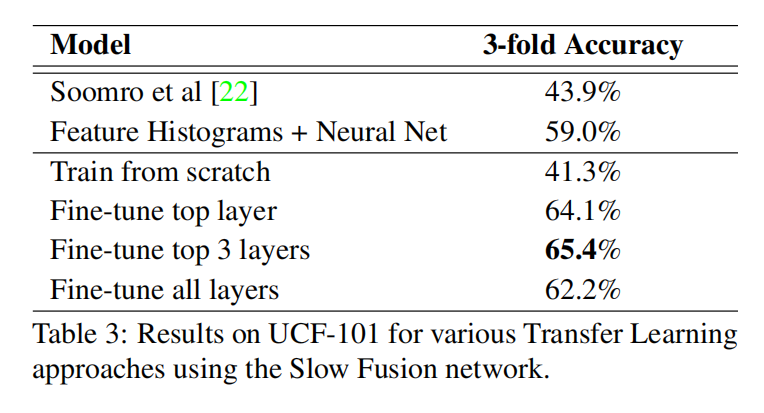
只训练top层accuracy就很高了,说明学习到的特征具有普遍性。
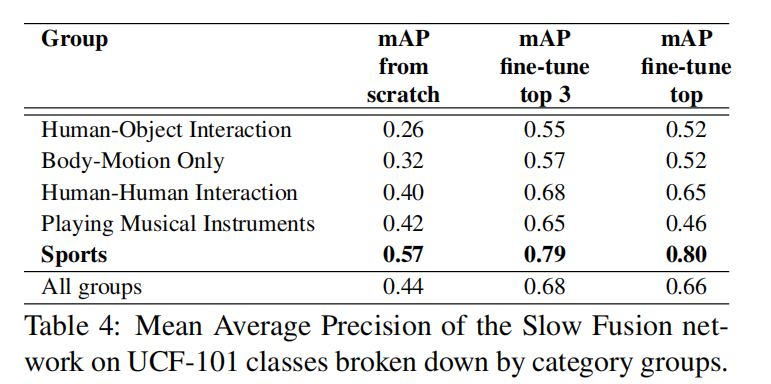
发现对于运动组的分类精度最高。
- Post title:论文阅读笔记:”Large-scale Video Classification with Convolutional Neural Networks“
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_003/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.