
Social GAN阅读笔记(cvpr 2018)
方法
问题定义
论文的目标在于同时推理和预测在一个场景里的所有实体的未来行动轨迹。假设我们可以获得场景里人们的所有轨迹信息为
GAN
论文模型包含三个关键组件:生成器G,池化模块PM,和判别器D。G是基于编解码框架的网络,论文使用了PM模块来连接编码器和解码器的隐状态。模块G提取输入Xi并输出预测轨迹
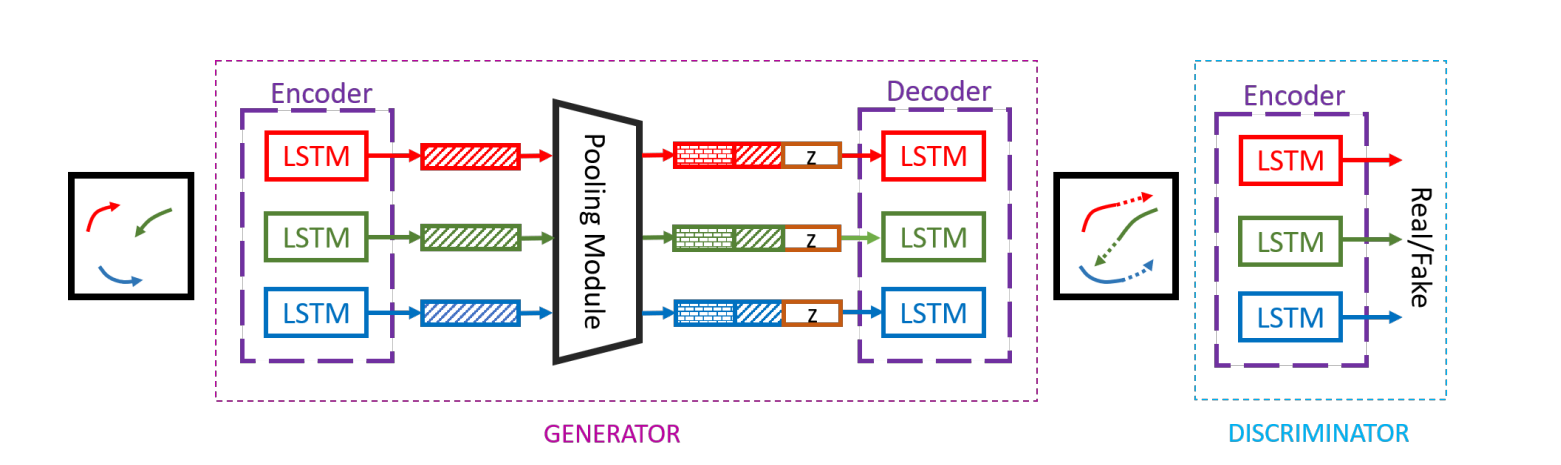
GENERATOR
在模块G中,论文首先使用一个单层的多层感知机把每个行人的位置信息嵌入并得到了固定长度的向量
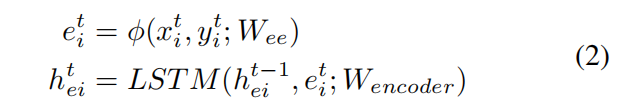
其中,
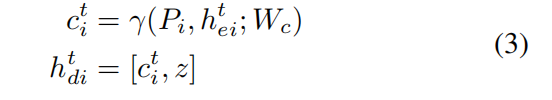
其中,
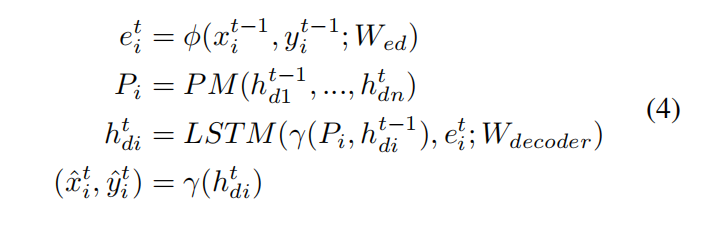
Pooling Module
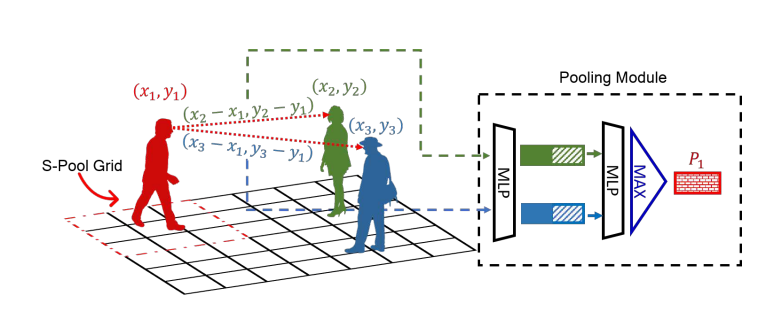
对于行人1来说,其位置为(x1,y1),将场景内其他人相对行人1的位置坐标(如
多模态输出
论文提出了一种损失函数,它可以促进网络生成多样的样本。对于每个场景,我们生成了K个可能的预测输出,并选择其中最好的预测作为最终的预测。
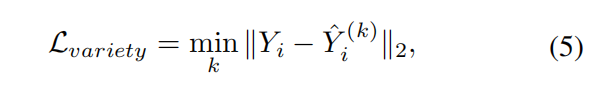
实现细节
作者在GAN中使用了长短时记忆这一特殊的RNN来处理序列位置数据。编码器的隐状态维度为16,而解码器的隐状态维度为32。我们将输入坐标序列编码为了16维向量。作者使用Adam优化算法训练生成器和判别器200个epoch。其batch size大小为64,初始学习率为0.001。
实验
指标
- 平均位移误差(ADE):在所有预测时间点的L2距离
- 最终位移误差(FDE):在预测最终位置和真实最终位置间的距离
基线
- 线性:一个最小化最小二乘误差的线性回归器
- LSTM:一个没有pooling机制的简单LSTM
- S-LSTM:每个行人通过一个带隐状态的LSTM进行建模,该隐状态在LSTM的每个时间点使用social pooling layer进行池化
消融实验
论文对于不同的控制设定进行了消融实验。在测试时,论文从模型中采样N次并选择最好(L2距离小)的预测用来进行定量评估。
评估方法
论文使用了留一法来评估模型,即将数据集分为5个集合,每次在其中的4个数据集合上进行训练,在剩余的一个数据集合上进行测试,重复训练5次。论文观测8个时间点(总计3.2秒)的历史轨迹,并预测8和12个时间点的未来轨迹。
定量分析
- 指标精度
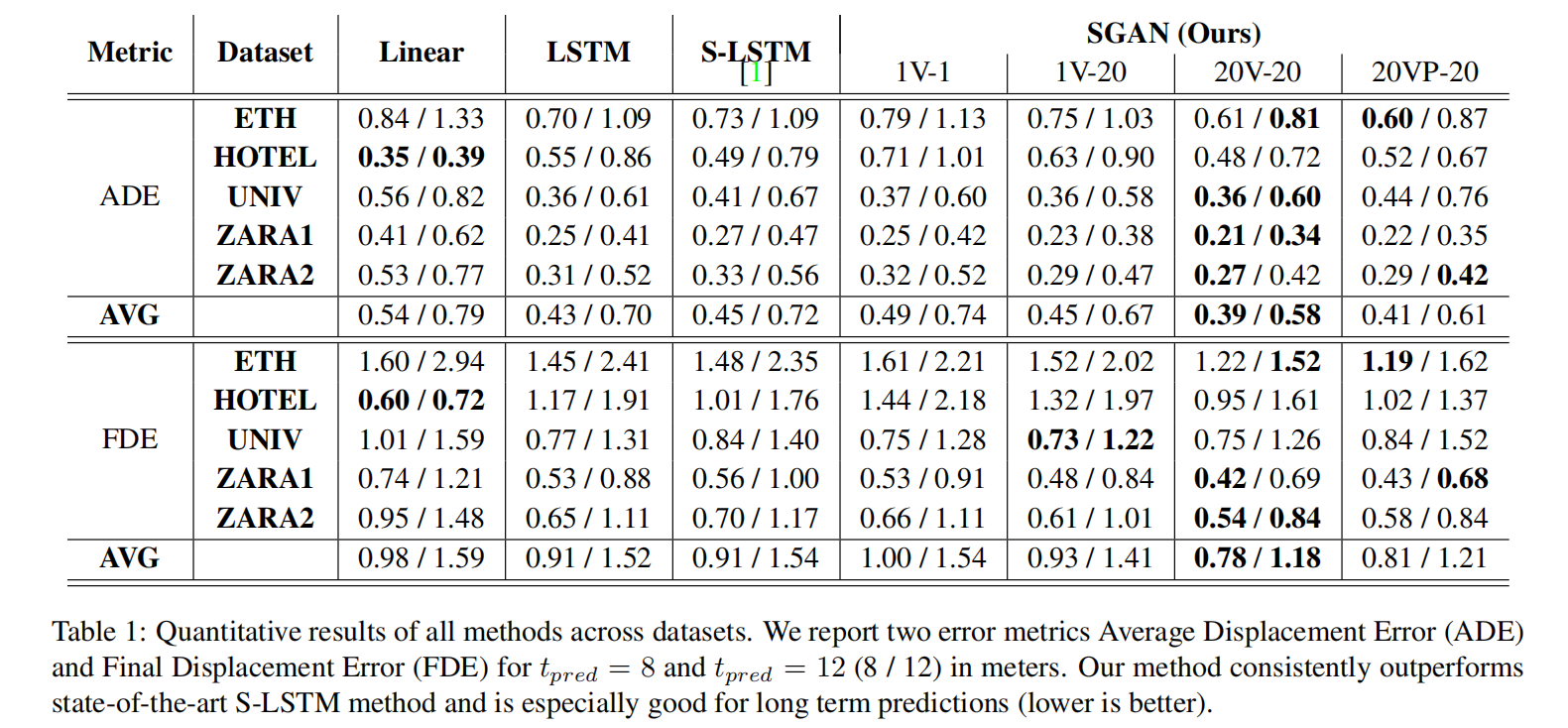
因为线性模型只能够建模直线路径,所有其表现没有LSTM和S-LSTM好,因为他们可以建模更复杂的轨迹。但在实践中S-LSTM的性能并没有像论文中所说的那样超越LSTM。SGAN-1V-1表现没有LSTM好的原因在于模型的条件输出只是多种可能的未来轨迹的其中之一,也许与真实标签有较大差异,但当我们考虑多样本时,SGAN表现超越了baseline方法,这从一个侧面证明了该模型具有很好的多模态输出性质。
- 性能速度
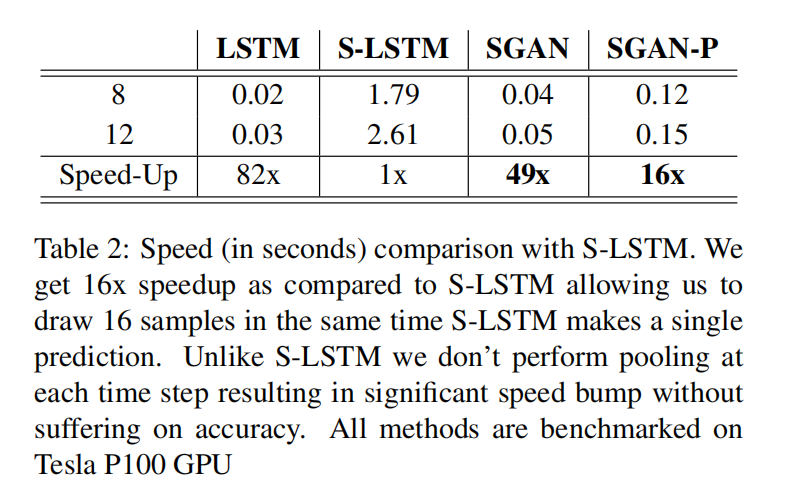
SGAN-P的预测速度是S-LSTM块近16倍,LSTM更快但是不能避免碰撞和实现多模态输出预测。
- Post title:论文阅读笔记:”Social GAN:Socially Acceptable Trajectories with Generative Adversarial Networks“
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_004/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.