
Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset(CVPR 2017)
该论文提出了Kinetics这一更大的人类行为视频数据集,使用它进行预训练的模型更适合于迁移学习。该论文提出了一个新的模型I3D,并将该模型与之前提出的不同行为分类架构进行比较。
模型网络
I3D
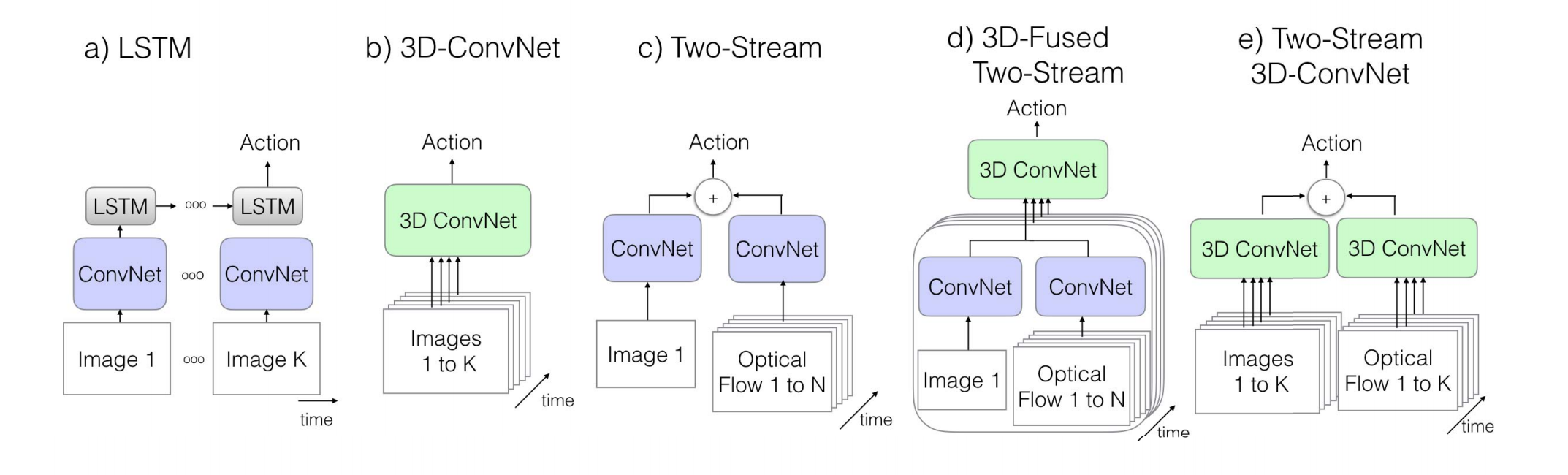
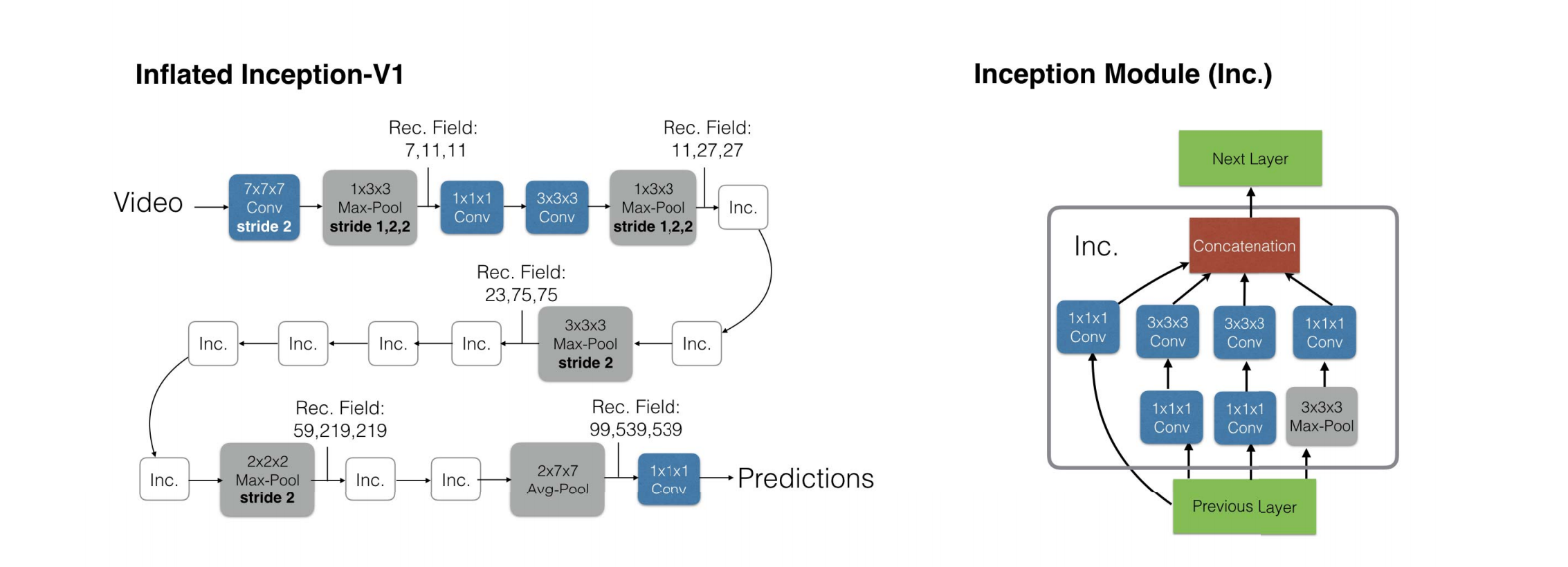
b图3D-convnet架构的缺陷是,无法有效利用ImageNet预训练模型,需要从头开始训练,并且由于参数量的庞大而较难以训练,因此网络较浅。c图双流法弥补了a图LSTM低层次运动信息的缺陷,而且更加容易训练。d图在双流法的基础上将空间和光流信息在最后进行融合,并将融合的信息送入3D-convnet进行分类。e图的I3D在d图的架构上进行了改进,用3D-convnet对之前的convnet进行了平滑扩展,并且可以充分利用ImageNet预训练参数。这里的想法是可以通过对原图片进行复制,并将其转换为每帧都相同的视频序列(boring-video)。但其实我们也不需要真的训练,这里需要满足一个条件我们就可以直接利用2D-convnet的参数:在视频上的响应或激活特征应与单张图片时作为输入时相同。所以我们只需对2D-filters沿时间维度进行复制,并将权重缩小n倍即可。还有一个问题也需要处理,就是如何进行时间维度感受野的设置,即我们如何设置时间维度的stride步长。它的设置应与采样帧率与图像维度有关,过大会会导致混淆不同物体的边缘,不利于学习良好的特征;过小也会不利于捕获场景中的动态信息。通过实验,作者认为在前两个maxpooling层不执行时间维度的池化会比较有效。下图是I3D主干网络的结构图:
作者认为如果只使用RGB输入,模型只单纯地进行前馈计算,而因为光流算法涉及一些迭代优化,这可能是加入光流对模型性能有较大提升的原因。值得一提的是,作者并没有进行端到端的训练,而是分别训练两个不同输入的模型;并且训练时作者多个GPU进行同步训练。
- Post title:论文阅读笔记:“From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting(ICCV 2021)”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_007/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.