论文阅读笔记:“Notes on Long-Term Temporal Convolutions for Action Recognition”

Notes on Long-Term Temporal Convolutions for Action Recognition
一. 论文思想
典型的人体动作经常持续数秒,只学习少数帧无法对动作在其持续时间范围内进行有效建模,将具有特定特征的视频分解为clips,并在视频层面将各个clips的信息加以聚合的方法可能不是最优的,因此该论文尝试通过长期时间卷积(LTC)来学习视频的有效表示。为了不让复杂度过高,使模型易于处理,作者在增加时间范围的同时降低了空间分辨率。
二. 模型结构
作者以C3D模型为基础,扩展该模型实验了不同输入时间分辨率(
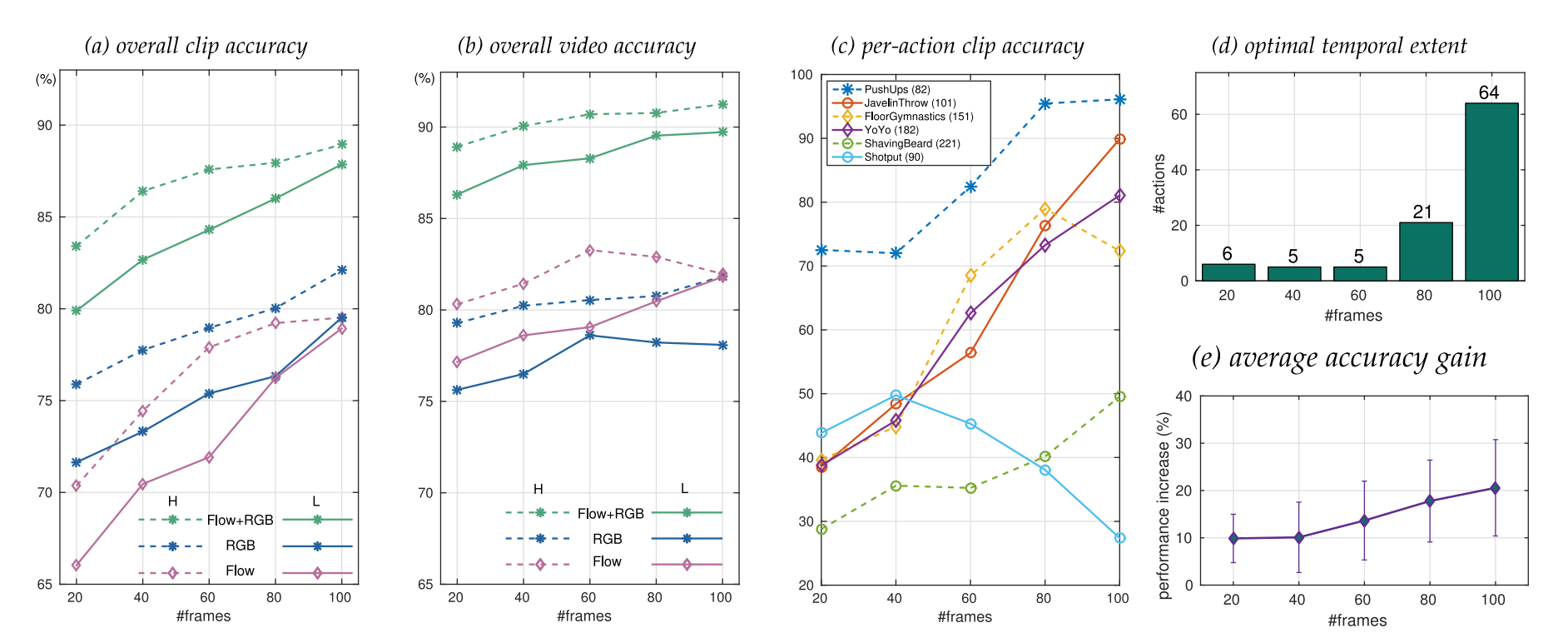
如上图a,b所示,文章发现更大的空间分辨率在时间范围较小时对结果的提升较为明显,但是相当于空间分辨率,时间分辨率对结果的提升更明显,作者认为这可能是因为更多的参数需要大数据集进行训练,而训练数据的不足导致了过拟合。图c说明了时间分辨率对不同行为分类准确率的影响,小部分历时较小的行为(例如shotput)甚至会导致较差的效果。为了判断最优时间范围,作者统计了不同时间分辨率下的准确率最高的行为数量分布,如图d 所示,可见绝大部分的最优准确率均在100处获得。e图计算了平均准确率增益,进一步印证了在100时获得的增益最多。

如上图,作者还研究了对不同时间分辨率的LTC网络进行组合(通过late fusion)所带来的增益。

由图,在网络的越高层,越高的时间分辨率,同一个filter所对应的响应更加纯化(即同类的行为具有更高的聚合性)。
- Post title:论文阅读笔记:“Notes on Long-Term Temporal Convolutions for Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_010/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments