
MoViNets: Mobile Video Networks for Effificient Video Recognition
一. 论文思想
传统视频行为识别需要巨大的计算量和存储需求,该论文所提出的模型极大地优化了计算和存储效率,movinet可以线上对流视频进行实时推理。该论文首先设计了一个视频网络搜索空间,应用NAS技术生成有效且多样的3D架构。其次论文引入了流缓冲技术,将内存从视频剪辑中解耦,从而允许3D网络仅需常数的内存足迹就可以嵌入任意长度的流视频序列进行训练和推理。该论文还使用了一种简单的组合方法来提升精度。值得注意的是,该模型未使用任何预训练技术,并且仅使用RGB输入。
该论文在提高视频模型的效率做了进一步的研究。SlowFast networks, X3D等是这方面的代表。有些网络TSN等进一步探索了2D网络,这些网络在之后对片段特征图进行late fusion。TSM[1]使用了early fusion,它沿着时间坐标移动了一部分通道,在支持在线推理的同时提高了准确率。
对于计算复杂的视频网络,寻找一个有效的架构是十分必要的, [2][3]探索了一些寻找架构的方法。在视频架构搜索方面,Tiny video networks[4]和AssembleNet[5]有较大贡献。
深度组合常被用于提升CNN的性能,图像分类的近期研究表明[6]对小型的深度组合可能比单个大模型更加有效,作者将该发现扩展并应用于视频分类。
在设计用于在线流视频推理的stream buffer的时候,作者受到了因果卷积[7]的启发。
二. NAS
作者通过NAS探索了如何融合时空操作来寻找最佳特征组合以权衡效率与精度。
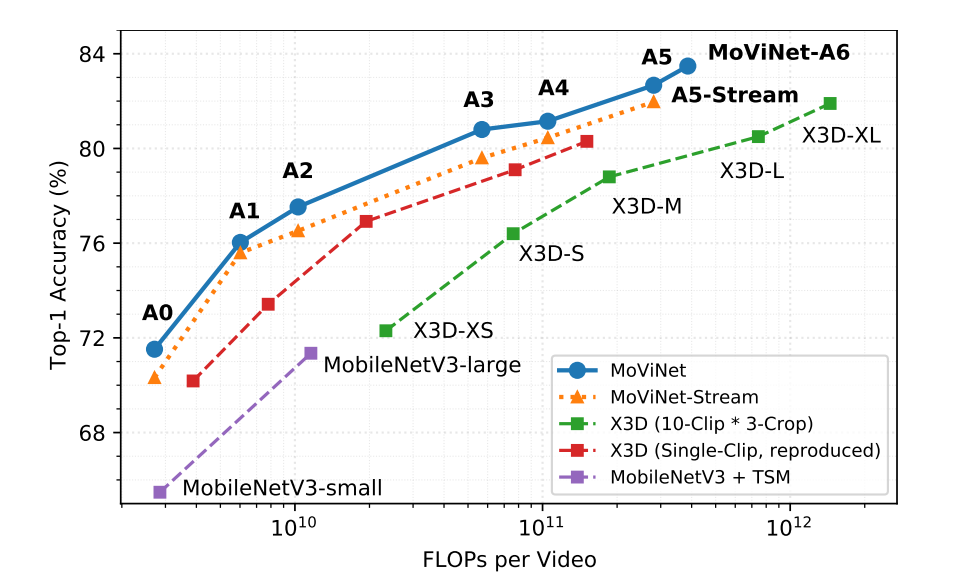
从图中可看出对于movinetA0在与mobilenetlarge+TSM达到相似准确率的情况下,浮点数运算减少了近75%。movinetA6达到了83.5%的精度,比X3D精度高了1.6%,浮点数操作减少了近60%。

在2D 移动网络搜索的研究基础上,作者以TuNAS框架为起始,并对它略作修改使之适用于3D网络。Movinet搜索空间的基准是MobileNetV3,上图是对搜索空间的总体描述。对于网络中的每个block,NAS搜索了基准filter width,和每个块中的层数。作者将乘子{0.75,1,1.25}应用在特征图通道。作者设置了5个block,并在每个block的第一个层使用空间降采样。对于时间维度,每层的过滤器大小在如下的范围中选择:{1x3x3, 1x5x5, 1x7x7, 5x1x1,7x1x1, 3x3x3, 5x3x3} 。这些选择使得层关注并聚合不同的维度表示方法,在最适宜的方向扩展网络的感受野,并减少其他维度的计算量。每个层之后有$111
二. Stream Buffering
原理:流缓冲通过缓存子剪辑边界处的特征图将时间依赖在连续非重叠子剪辑的进行传递。它在流缓冲中加入了无向因果操作如因果卷积,累计池化和带位置编码的因果SE操作,使得时间感受野只查看过去帧,允许我们在线上推理时递增地处理流视频。因果操作在kinetics数据集上仅仅损失了1%的精度。
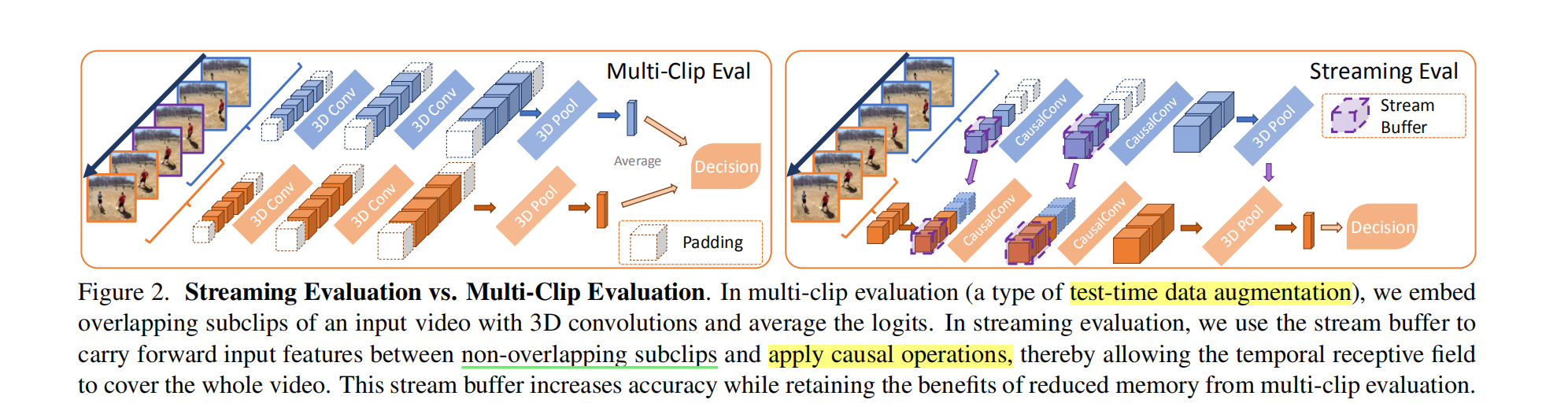
上图对比了流评估和多剪辑评估方法,左图的多剪辑评估也是一种有效减少内存的解决方法:模型在测试时对n个相互重叠的子剪辑进行平均预测,这种方法将内存消耗降低到
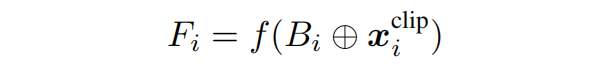
上面的公式将缓冲B与当前子剪辑xi沿时间维度进行拼接,并将得到的张量通过3D卷积进行处理,得到了特征图Fi。
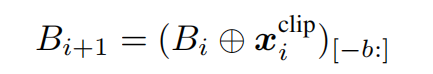
当处理下一个剪辑时,我们需要对buffer进行更新,公式如上图所示。作者在拼接后的张量中选择最新的b个帧来更新该buffer。因此,流缓冲技术的内存复杂度为
在流缓冲中,作者强制使用了因果关系,即任何特征不能从未来特征计算得出。它有很多好处,包括将子剪辑降低到单帧但不会影响激活和预测,从而使得3D网络能够对流视频进行在线推理。在因果卷积中加入CasualSE可以使得精度进一步提高。作者在实验中发现,将帧位置编码向量与CGAP(累积的全局平均池化)输出相加得到的输出来继续进行SE投影效果比不使用位置编码效果好。
在训练时作者使用了循环训练策略来降低内存需求。作者不会对buffer进行反向传播,所以之前的子剪辑可以被释放掉,以空出内存。相反,它计算相邻clips之间的损失并累积计算的梯度(与batch梯度累积类似)。在线上推理时,我们经常将剪辑长度设为1来最大化内存效率,设置较小的剪辑长度同样降低了帧之间的延迟,使得模型能够输出单帧预测。
三. 时序组装
作者独立地训练了两个具有相同浮点运算数地stream movinets。它们的帧率均为先前的一半,但其中一个网络相对于另一个有一帧的偏移,作者在使用softmax之前先对它们的输出进行算数平均。该方法的计算量与训练一个大模型的计算量相同,但将两个小模型结合起来可以实现更高的精度。
四. 不带流缓冲的movinet
文章对7个不同计算复杂度的模型进行了实验,每个模型主要与X3D进行比对。

从图中可以看出,movinet在达到state of arts的同时模型的效率也是最高的。
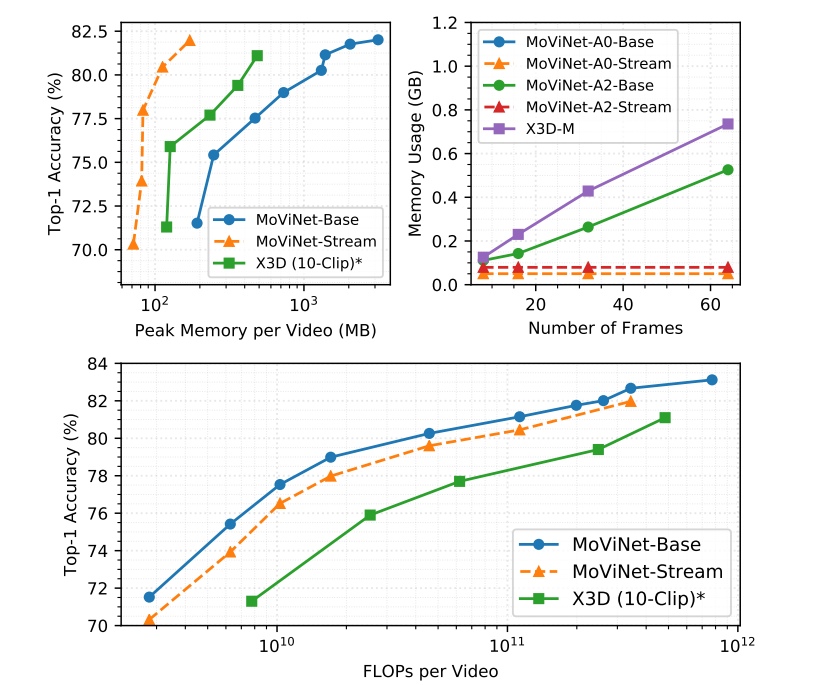
从图中可以看出,带stream buffer的网络相较base网络仅有1%的下降但是随着输入帧数的增加器内存使用是常数的。
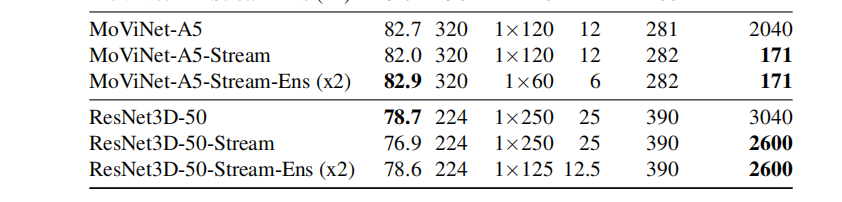
有趣的是,在对ResNet3D使用stream buffer方法时,削减的内存并不显著,这可能是因为depthwise卷积和3D全卷积之间的差别。
[1] Progressive neural architecture search. ECCV 2018
[2] Progressive neural architecture search. ECCV 2018
[3] Effificient neural architecture search via parameter sharing. 2018
[4] Tiny video networks: Architecture search for effificient video models. 2020
[5] Assemblenet: Searching for multi-stream neural connectivity in video architectures. 2019
[6] When ensembling smaller models is more effificient than single large models. 2020
[7] Massively parallel video networks. 2018
- Post title:论文阅读笔记:“MoViNets: Mobile Video Networks for Effificient Video Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_011/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.