论文阅读笔记:“X3D:Expanding Architectures for Effificient Video Recognition”

X3D: Expanding Architectures for Effificient Video Recognition
一. 主要思想
该模型基于“mobile-regime”系列模型MobileNet, 对原模型稍作修改,令乘加运算数少了近10倍,之后将模型从2D空间扩展到3D时空域
为了探索计算高效的架构,MobileNet和ShuffleNet探索了channel-wise separable convolutions and expanded bottlenecks.
MnasNet是通过采样近8000个模型来获得的(采用EfficientNet的grid search方法),作为对比,作者提出的方法每一个step仅需训练6个模型
二. 扩展方法
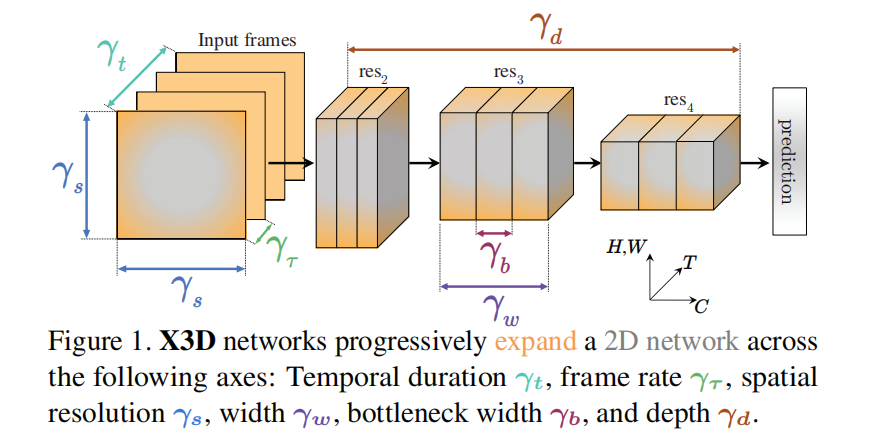
- mobile-net 核心思想:channel-wise separable convolutions
- 沿以下的轴进行扩展:历时,帧率,空间分辨率,网络宽度,瓶颈宽度及网络深度
- 递进地增加计算量:每次只扩展一个轴,训练并验证结果架构,选择能够实现最佳复杂度,准确率权衡的扩展。重复该过程直到满足预期的复杂度预算
- 该扩展方法可以被解释为坐标下降算法在超参数空间的应用

三. 实验
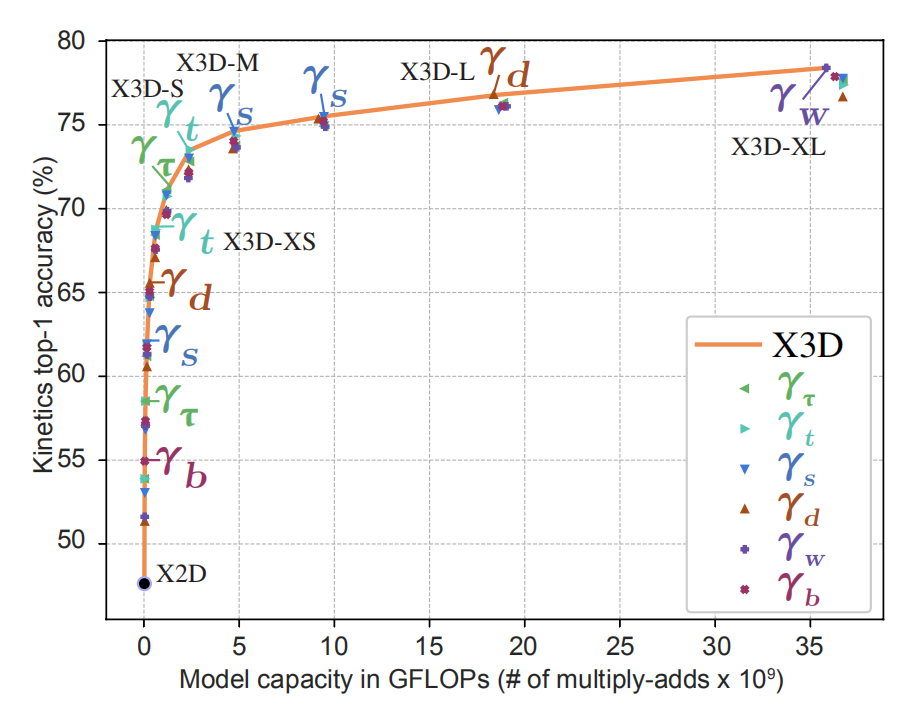
上图反映了top1准确率与模型容量之间的关系,作者将每一个step选择的维度都在曲线上进行了标注,从中我们可以得到一定的启示。

上表展示了根据目标模型复杂度(FLOPs)来划分的6个不同大小的模型
- Post title:论文阅读笔记:“X3D:Expanding Architectures for Effificient Video Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_012/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments