论文阅读笔记:“Is Space-Time Attention All You Need for Video Understanding”

Is Space-Time Attention All You Need for Video Understanding?
一. 主要思想
这篇文章所提出的模型仅使用了自注意力来实现视频分类。该模型将用于图像分类的ViT模型进行扩展,将空间从2D图像空间扩展为3D时空体。文章研究了不同的自注意力模式,提出了可分离式自注意力。
之所以将NLP中的transform模型引入视频分类,是因为它们具有高层次的关联性:
- 都是序列化的
- 情景信息(上下文)对理解原子动作(词语)的语义十分重要
当前的视频理解领域,大部分模型依旧采用2D或3D卷积作为核心操作,尽管有一些模型采用了自注意力机制,但也只是发现将其应用在卷积层之上精度会有一定回报。
作者认为只使用自注意力来搭建视频理解架构也是可行的:
- 归纳偏好(局部连接和平移不变性)限制了CNN的表达能力
- 卷积核的设计使得模型难以对感受野之外的依赖进行建模
- CNN的参数量大且训练较为困难
二. 遇到的困难
标准的transformer需要对每一对tokens进行相似度测量,因为一个视频中的patches数量很多,在这个情景下,其计算复杂度是很高的。为了解决这些问题,文章研究了不同的自注意力模式,其中可分离式自注意力效果最好。
为了解决这个问题,其他论文采用了诸多方案降低复杂度:
- 局部近邻(限制自注意力范围)
- 全局自注意力(下采样的图像)
- 稀疏键值采样
- 分为时间自注意力和空间自注意力(本文采用的方法)
三. TimeSformer模型
线性嵌入
首先论文将clip分解为patches,用x来表示每一个patch,公式1进行了线性嵌入得到嵌入向量z,其中E和e都是可以学习的参数,e代表对每个patch的时空位置进行编码的位置嵌入向量。
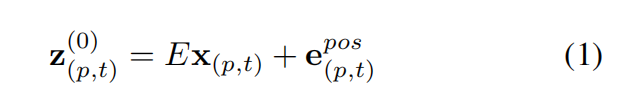
查询键值计算
模型包含了L个编码块,在每个块中,为每一个patch的表示(由上一个块编码得到)中计算查询/键/值向量。其中LN()代表LayerNorm;a = 1,…,A,其中A为多头注意力的数量,其中每个注意力头的隐维度数量为Dh = D/A
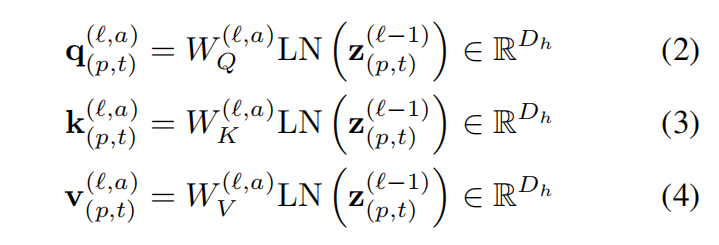
自注意力计算
自注意力权重可以按照如下的公式进行计算:
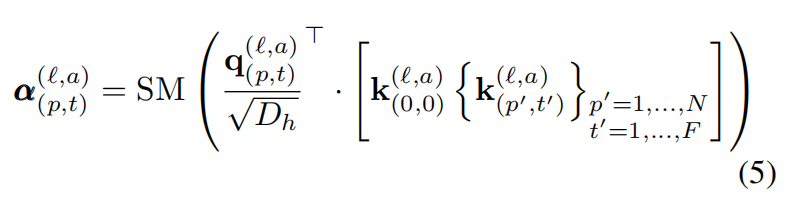
SM()代表softmax激活函数,自注意力仅在p(空间维度)或t(时间维度)上进行计算所以计算量被显著地降低了。
编码过程
第l个块的patch编码z可以通过:
- 先计算值向量的加权和,公式如下:
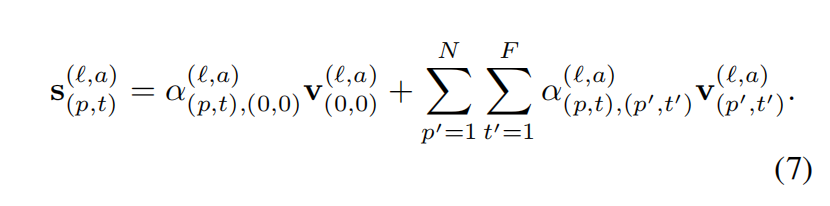
- 将这些向量沿HEAD维度进行连接,再传入多层感知机即可得到最终编码向量(注,在每一个操作中还使用了残差连接):
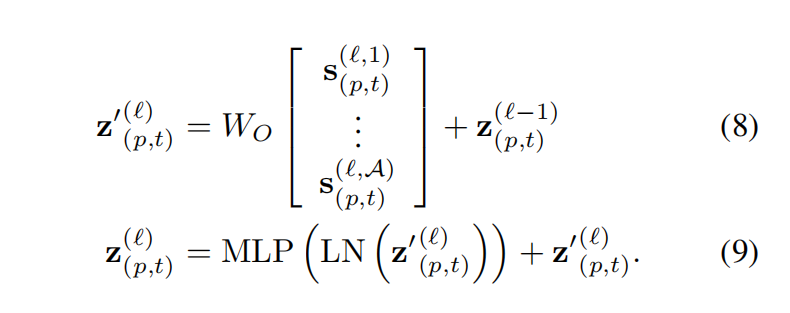
- Post title:论文阅读笔记:“Is Space-Time Attention All You Need for Video Understanding”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_013/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments