
论文阅读笔记:MobileNets系列论文浅析:mobilenet v1
参考原论文
参考B站视频
hint: 为了去寻找一个最优的网络架构,有哪些思考模式是可以借鉴的
核心亮点
depth-wise separable convolution
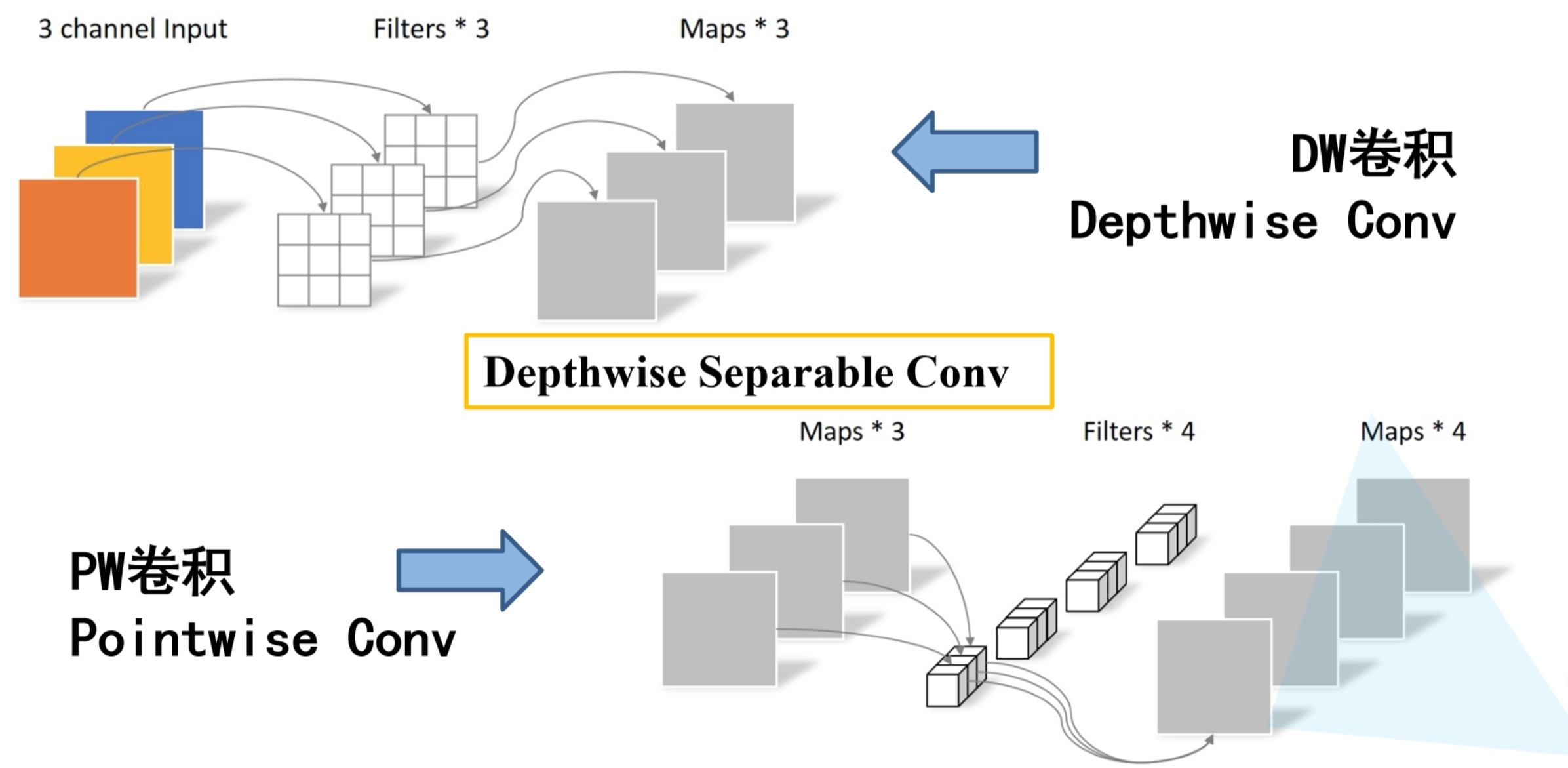
深度可分离卷积是分解卷积的一种,如图它包含了DW卷积和PW卷积。DW卷积(depth-wise conv)也叫 channel-wise 卷积,实际上是分组卷积的特例,它处理长宽方向的信息。而PW卷积是卷积核大小为1的普通卷积,其目的是将depthwise convolution的输出进行结合,处理跨通道的信息。普通卷积在一步里同时完成了过滤(filter)和组合(求和combination)的操作,而深度可分离卷积将filter和combination分为了两步,每一步由一个单独的layer来负责。
引入新超参:Width Multiplier&&Resolution Multiplier
- 目的:让模型更小,更快
- 引入Width Multiplier的计算量:
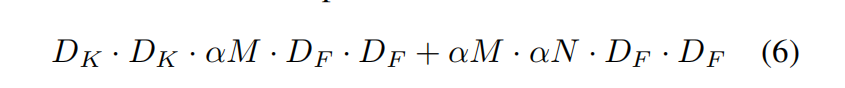
- 再引入Resolution Multiplier的计算量:
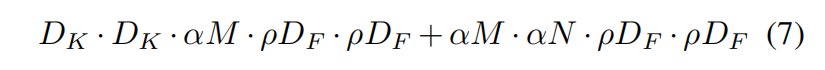
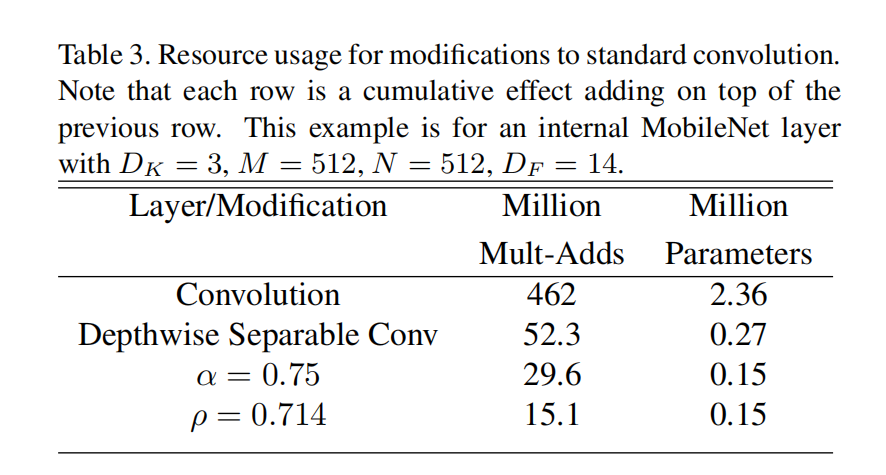
效果如下图所示:(计算量减少了近30倍)
亮点思考
为什么使用深度可分离卷积可以减少计算量?
| 普通卷积 | dw卷积 | pw卷积 | |
|---|---|---|---|
| 参数量 | $MD_KD_K*N$ | $D_KD_KM$ | |
| 计算量 | $D_KD_KMND_F*D_F$ | $D_KD_KMD_FD_F$ | $MD_FD_F*N$ |
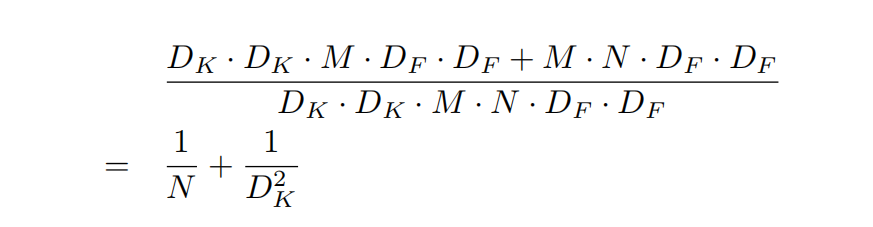
以卷积核大小为3为例,由上式可发现深度可分离卷积的计算量是普通卷积的
模型架构
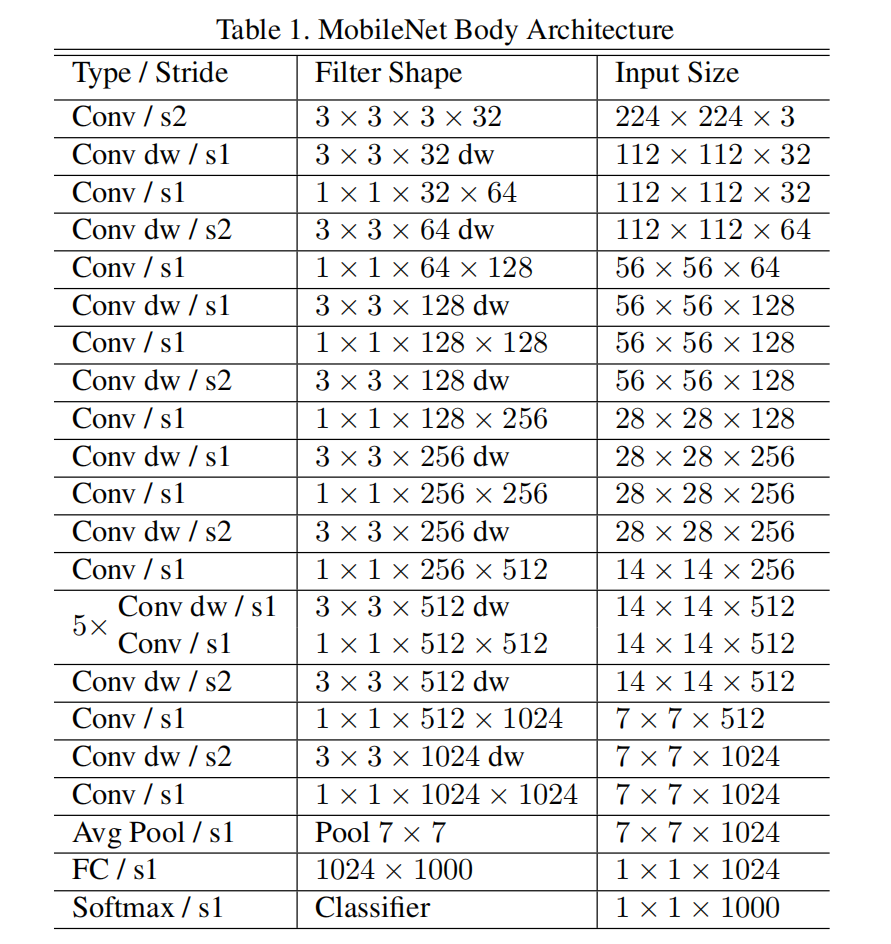
模型训练
与大模型相比,该模型仅有28层,因此论文用了更少的数据增强与正则化方法(小模型不容易过拟合),且未用到side heads 或是 label smoothing。实验发现,在dw卷积上使用较小或是不使用l2正则会比较好,因为所含参数量较少。
有意思的实验
更浅的网络好还是更瘦的网路好?
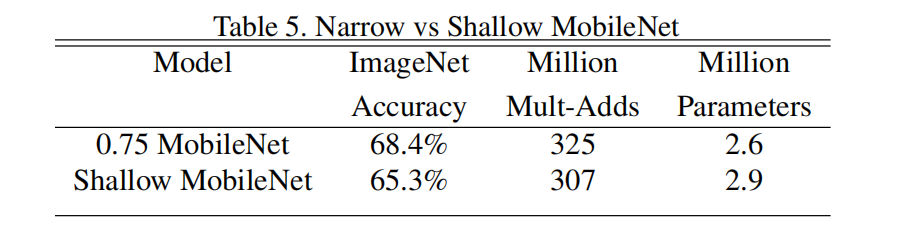
实验证明,参数量和计算量基本一致的情况下,更瘦的网络效果更好,高了近3个百分点。看系列第二篇笔记可以从理论上对这个结果进行解释。
trade-offs: 精度与计算量的平衡
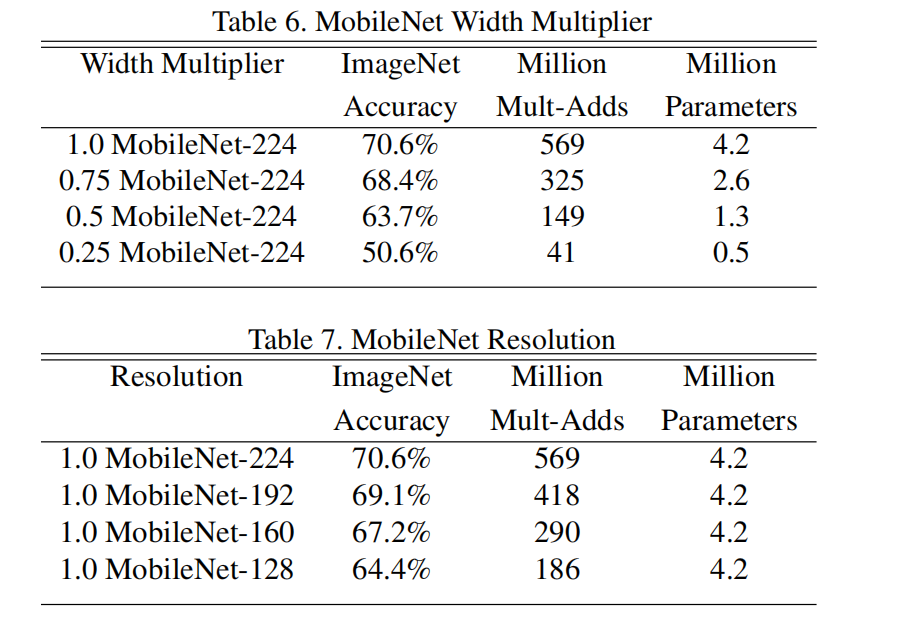
- 精度vs计算量:
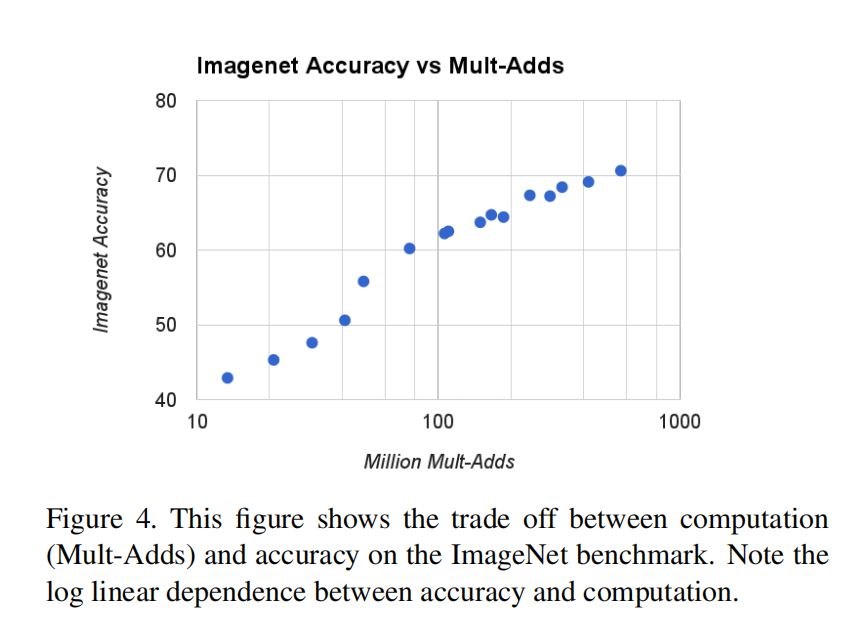
- 精度vs参数:
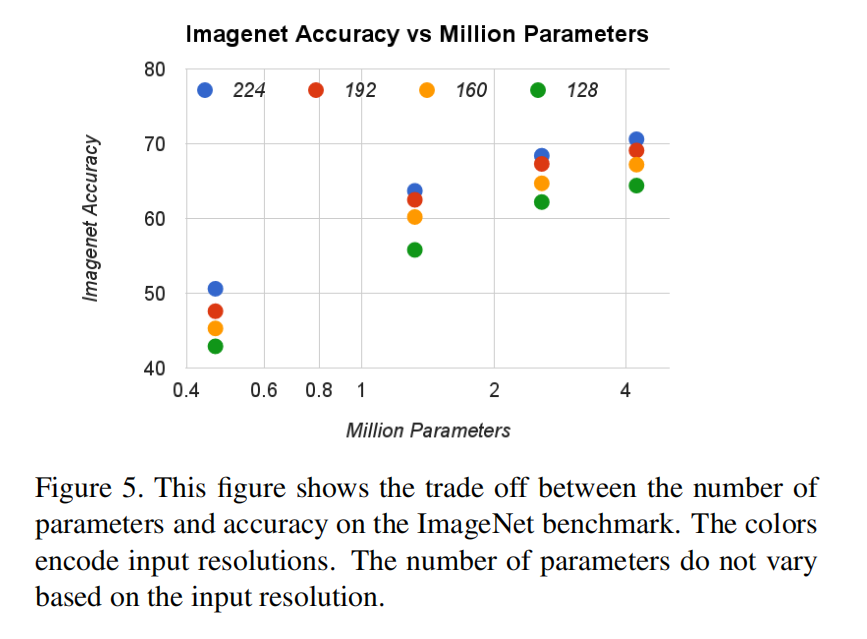
可以根据实际应用需求来调整,究竟是需要精度还是需要速度。
关键结论
可以考虑深度可分离卷积,和Width Multiplier&&Resolution Multiplier超参来降低模型复杂度
- Post title:论文阅读笔记:“MobileNets:Efficient Convolutional Neural Networks for Mobile Vision Applications”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_015/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.