
AssembleNet++: Assembling Modality Representations via Attention Connections
主要工作
为了学习原始输入模态和语义输入模态之间的交互关系,作者提出了一族可以显示地学习表观信息,运动特征和对象特定信息之间相互作用的模型AssembleNet++。为了对这种不同模态信息的相互作用进行建模,作者搜索了块间的同辈注意力连接性,引入了创新性的peer-attention模块。
网络结构
该模型采用了继承自AssembleNet的多流,多block的架构设计模式。
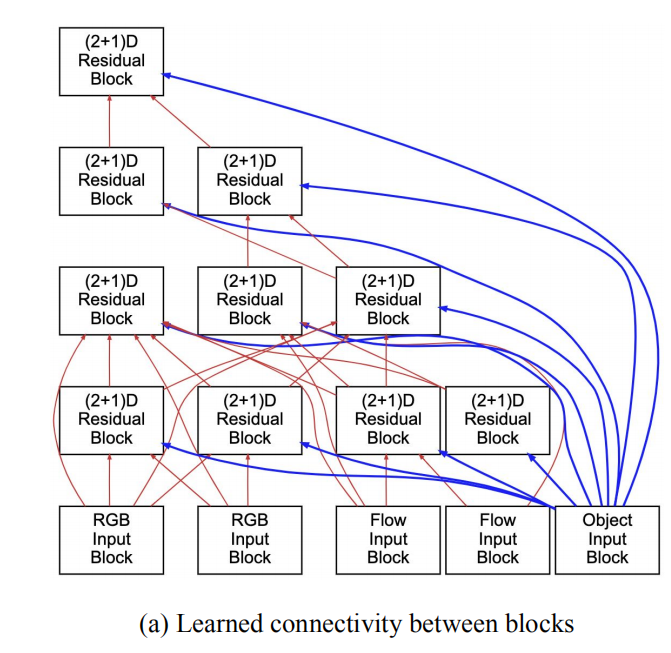
如图所示的连接图未加入注意力。可以看出输入block包括原始RGB,光流以及图中物体的信息多个模态。且图中的连接并非人为简单的设计,而是通过NAS方法搜索出来的,每个block都可以和其上层的多个block进行连接,也可以跳层连接,如图中最右侧的Object Input Block。每个Block又是R(2+1)D的residual block,包含1D的时间卷积,2D的空间卷积层还有一个1*1的conv层。
核心亮点
object information
物体以及他们的位置可以提供丰富的语义信息来对视频中的行为进行有效理解,从搜索得到的网络结构也可看出,语义信息包含在了整个架构中,所以可以和其他模态以及从中得到的中间特征进行交互,而且每一个学习到的物体连接的权重都大于0.7,可见该输入block的有用性。
weighted connections
任和一个块的输入都可以由其下层的一个或多个块的输出进行加权和来得到:
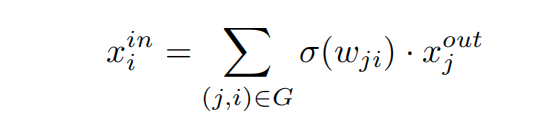
模型考虑了所有满足条件的connection(j,i):只要block j 所在的层数小于i所在的层数。思想即通过设置权重来允许学习连接的大小。
peer-attention(channel-wise attention)
同辈注意力连接性
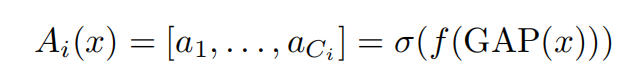
对于每个连接,上面的公式可以计算大小为Ci的权重向量。它首先对张量x进行全局平均池化,之后通过一个全连接层映射为大小为Ci的向量。
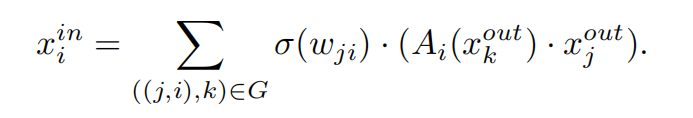
假设我们已经知道block k对connection(j,i)有影响,那么通过考虑来自块k的注意力,结合所有连接(j,i),我们就可以得到块i的输入,如果xj == xk,那么这种注意力就等价于经典的SE注意力。
one-shot differentiable architecture search
one of NAS approaches
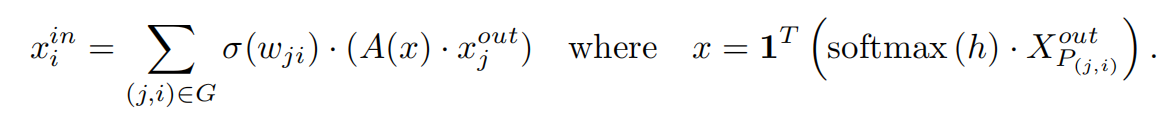
思想与weighted connections近似,通过设置每个peer block的weights,令weights是可学习的。通过训练,模型对每一个block会软选择(soft select)一个最好的peer block,这个peer会最大化识别的效果。从公式可以看出,x为所有peer block的加权和,公式的其他部分与前面的类似。
实验结论
物体信息的重要性
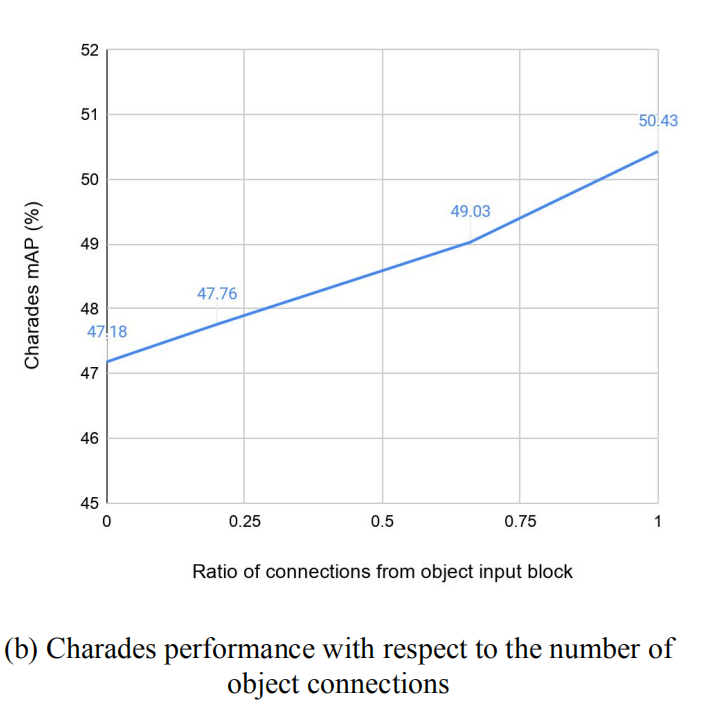
从实验可以看出,物体连接数量越多,数据集的mAP指标成比例的升高。
peer attention的有效性
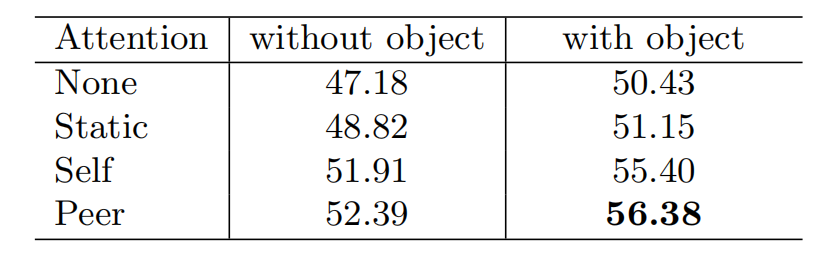
从图中可以看出,带有peer attention的mAP较无attention的网络提升了近6个百分点。
对其他架构具有通用性

- Post title:论文阅读笔记:“ AssembleNet++: Assembling Modality Representations via Attention Connections”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_017/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.