论文阅读笔记:“MobileNetV3:Searching for MobileNetV3”

论文阅读笔记:MobileNets系列论文浅析:mobilenet v3
核心亮点
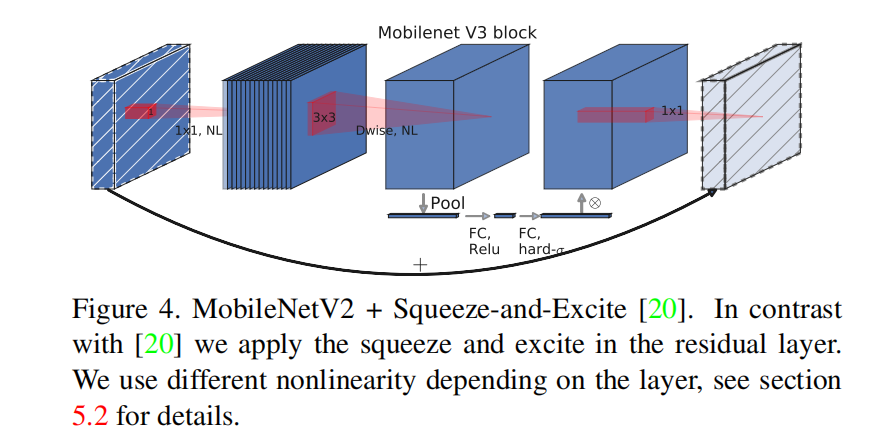
SE注意力的集成位置
为了让注意力可以在更大的特征表达上进行应用,所以该论文改变了SE模块的集成位置:
网络搜索network search
- platform-aware NAS
对于大模型,文章的实验结果与[1]一致,因此作者直接使用了 MnasNet-A1作为初始模型,然后在其上对齐进行优化。但是对于小模型,原先的奖励设计并没有为小模型进行优化,作者发现对于小模型,在给定延迟的情况下,精确率的变化极为剧烈,因此调整了权重因子对其进行补偿。
- NetAdapt algorithm
作者采用了NetAdapt[2]的技术并将其应用到了mobilenet架构搜索中。
在每个步骤中:
- 生成新的proposals的集合,每个proposal代表了一种架构的修改,它比前一步的延迟至少减少了
- 对于每一个proposal,我们使用从前一步得到的预训练模型,并将其移植到我们的新架构,对于缺失的权重可以进行随机初始化。对每个proposal进行T步的调优可以得到对精度的粗略估计。
- 根据指标metrics选择最好的proposal
不断循环上述步骤直到达到目标延迟。
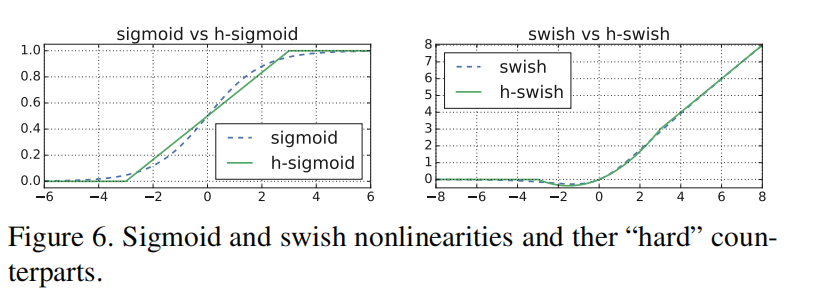
新的nonlinearities: hard swish
原先的swish的计算公式为:
但是sigmoid函数在移动设备上的cost较为昂贵,因此论文类比它提出了新的非线性激活函数:
下图为两个hard-soft函数的直观比较:
网络结构
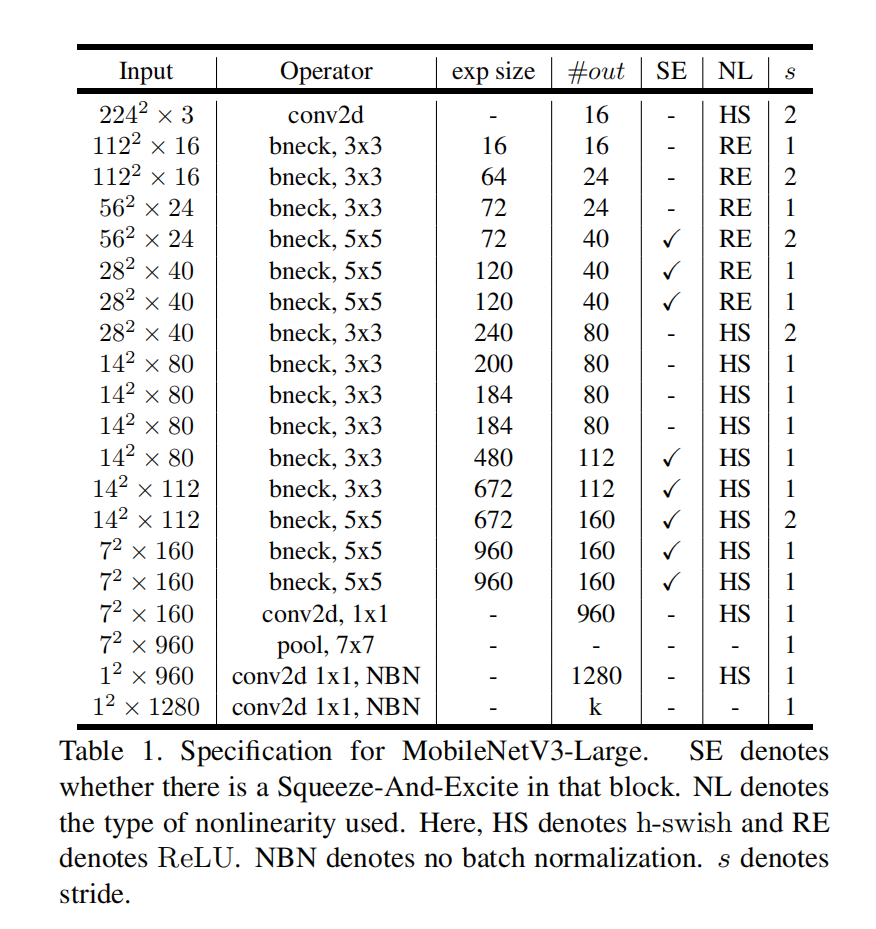
相较于mobilev2,v3将第一 个conv层的卷积核数量减少为了16(原先为32)
相较于mobilev2,v3对最后几层进行了如下的优化:
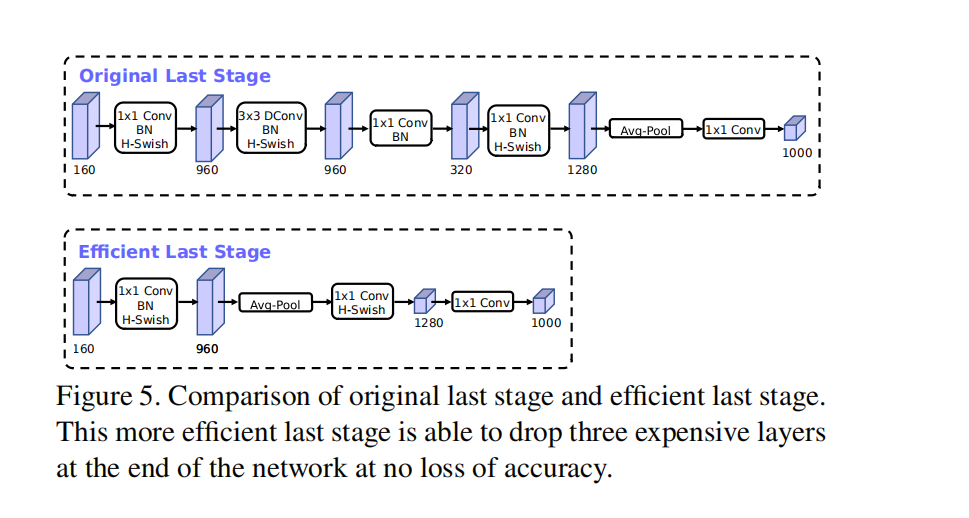
网路优化roadmap
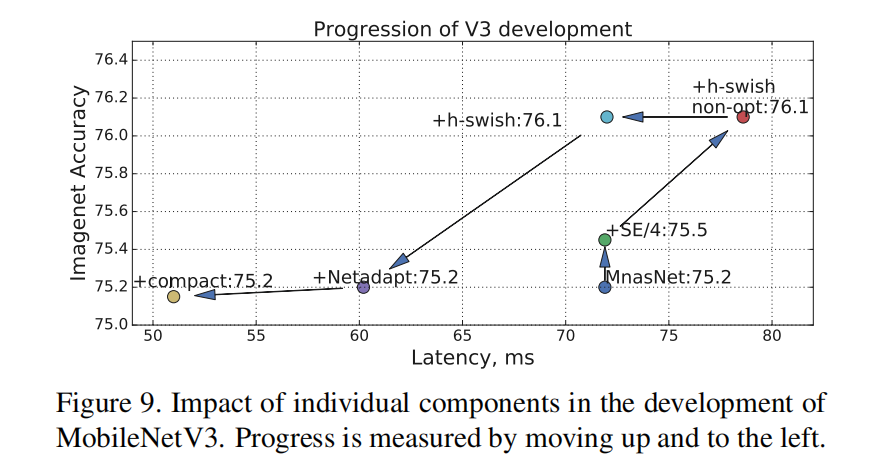
训练细节
- 优化器:RMSProp with 0.9 momentum
- batch size: 4096
- learning rate decay rate of 0.01 every 3 epochs.
- dropout of 0.8
- l2 weight decay 1e-5
- batch-normalization layers with average decay of 0.99
实验结果
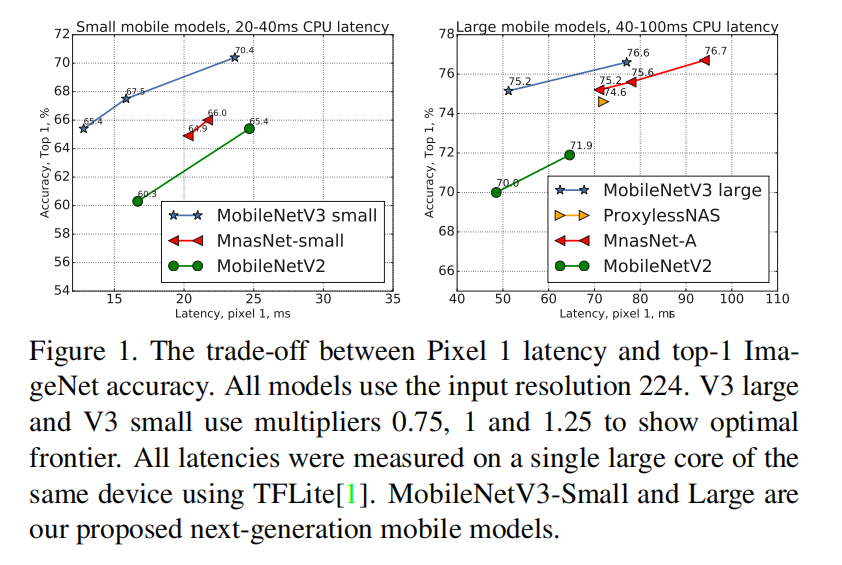
可以从精度-性能对比曲线中看出mobilenetv3优于之前提出的模型。
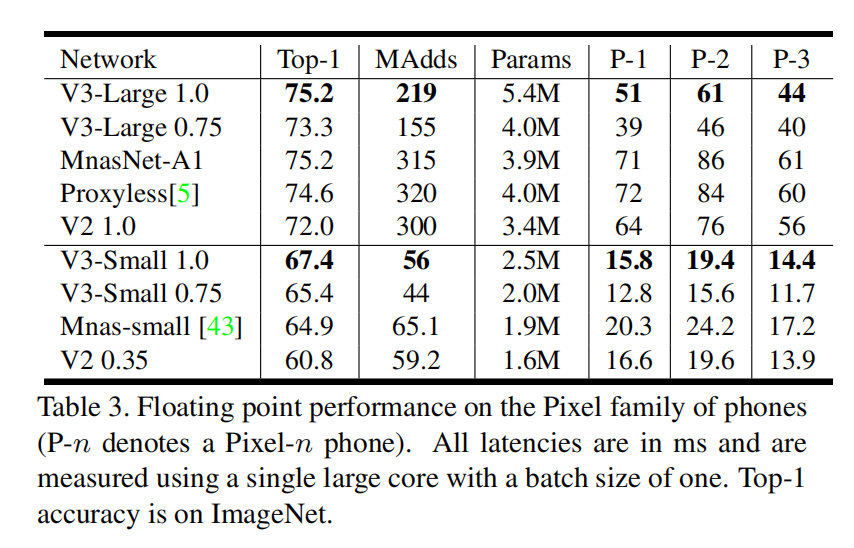
具体的精度,计算量,参数量以及延迟的数据如上表所示。
参考文献
[1] Mnasnet: Platform-aware neural architecture search for mobile. CoRR 2018
[2] Netadapt: Platform-aware neural network adaptation for mobile applications. ECCV 2018.
- Post title:论文阅读笔记:“MobileNetV3:Searching for MobileNetV3”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_018/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments