
3D Convolutional Neural Networks for Human Action Recognition(TPAMI 2013)
读这篇文章的原因,是因为他是整个3D model的开山之作。虽然,它所提出的模型远没有达到”Deep Learning”的深度,一些模块的设计也有明显hand-craft—手工的影子,但不可否认的是,其创新性的3D卷积核的思想对后面的网络有较为深远的影响,同时这篇文章将传统方法中hardcoded的参数消除,令模型参数都是可以在data上训练得到,这种端到端的训练思想从这篇文章就可窥见一般。
核心亮点
3Dfilters
3D卷积的数学形式化描述如下:
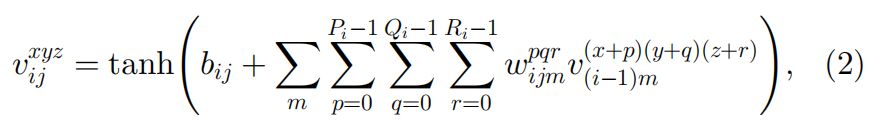
3D卷积的输出特征图是一个体素,相比起3维的2D卷积,4维的3D卷积相对较难理解一些(这里的三维和四维指的是计算时的维度,加上了通道维度),图形化解释可见下图:
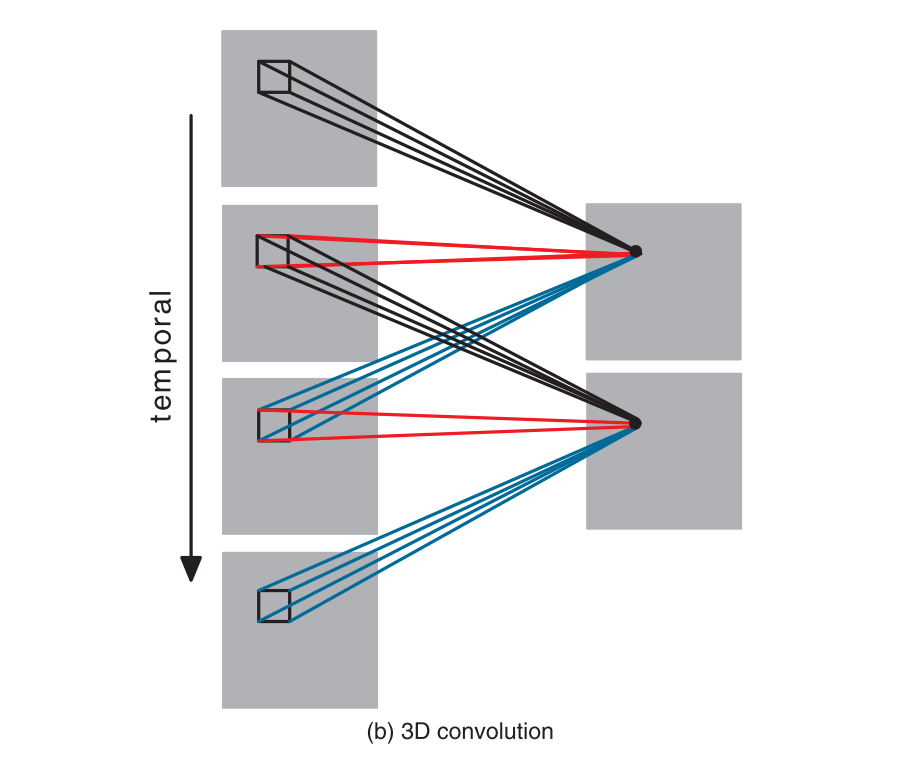
如图为时间维度的stride为1的,kernel size为3的3D卷积。3Dfilter在整个4D张量的各个位置去进行卷积,得到的结果是一个3D张量,与2D卷积核类似,使用多个3Dfilters可以将多个3D张量组合为新的4D张量。
分离式channel数据流+特征融合
论文使用了预先hardwired的kernels对原始输入进行处理,生成了多通道的信息:分别为灰度,x方向梯度,y方向梯度,x方向光流,y方向光流。文章将该层称为hardwired层,用来编码我们对于特征的先验知识。之后论文在每个channel(指的灰度,梯度,光流等)上分别进行3D卷积和降采样(注:只有两个3D卷积,很浅)。之后文章使用全连接和卷积对得到的特征进行融合,全连接层(linear classifier)充当了分类器的作用。
高层特征正则化
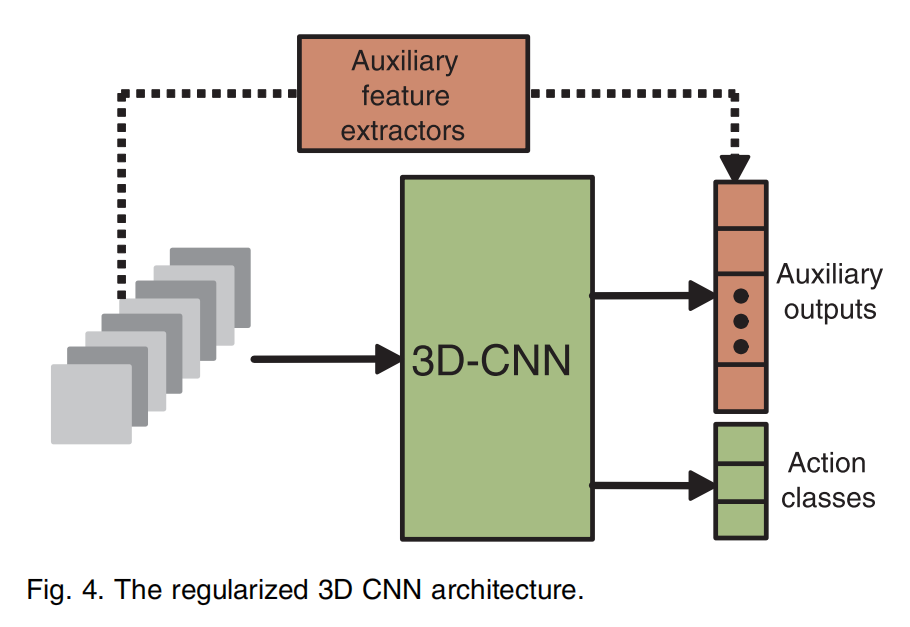
受限于当时的硬件,可输入的帧数较少,所以编码高层运动信息显得尤为重要。作者通过对大量的帧计算运动特征(长期),并将其作为正则化模型的辅助输出。作者希望模型可以学习到一个类似于辅助输出的特征向量
模型组合
作者认为,构建多个不同架构的CNN模型,能够捕获潜在的互补的信息。作者为此提出了3个可选的CNN架构
模型架构
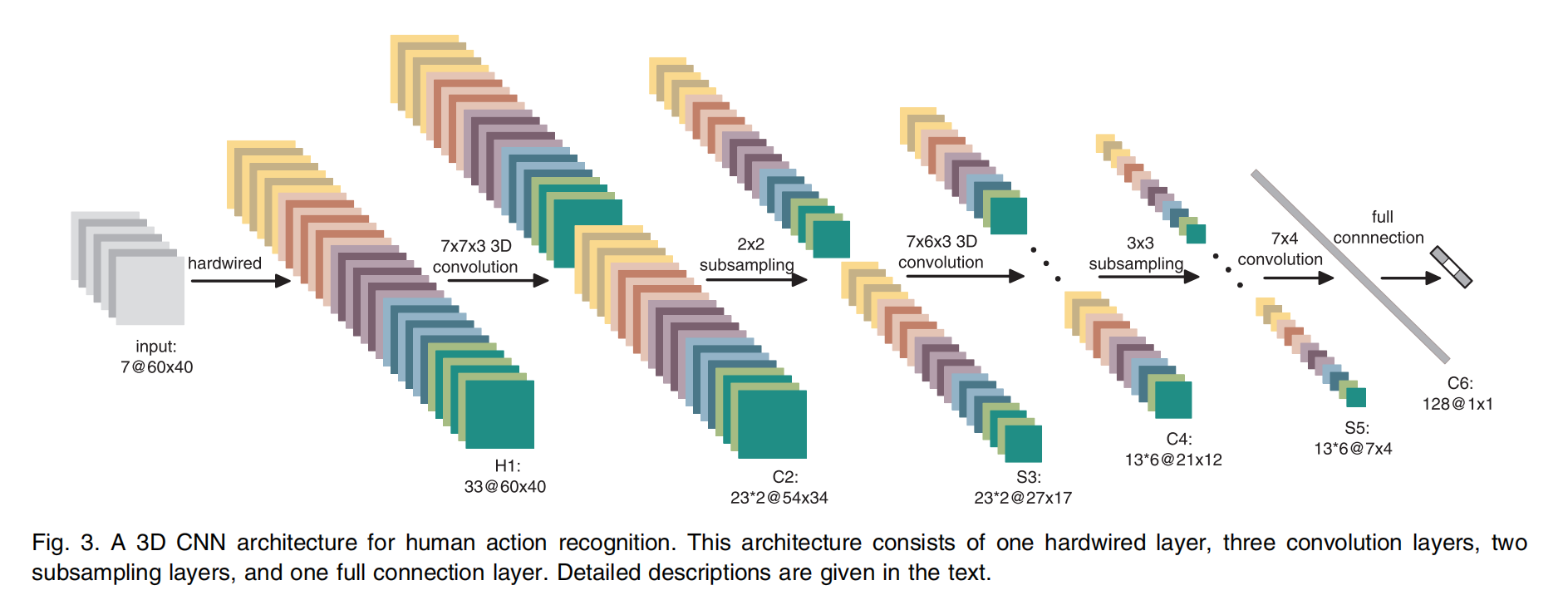
模型的架构虽然简单,但是作为一个可以扩展的基础baseline,为后续研究的深入奠定了基础。
- Post title:论文阅读笔记:“3D Convolutional Neural Networks for Human Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_019/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.