
Two-Stream Convolutional Networks for Action Recognition in Videos
之前虽然已经读过了一遍,但其中的经典思想依然是可以借鉴的,因此再细读一遍,希望能有新的理解
这篇文章提出了一个新的双流架构(空间和时间),之后通过late fusion进行融合
核心亮点
two stream 双流架构
空间流从静态视频帧中进行动作识别,而时间流从密集光流中学习。之所以将时间和空间分离,是为了有效利用imagenet进行预训练。从神经学的角度也可以得到一些解释:人脑视皮质(human visual cortex)包含两条通路,腹侧通路(ventral stream)执行目标识别,而背侧通路(dorsal stream)执行运动识别。
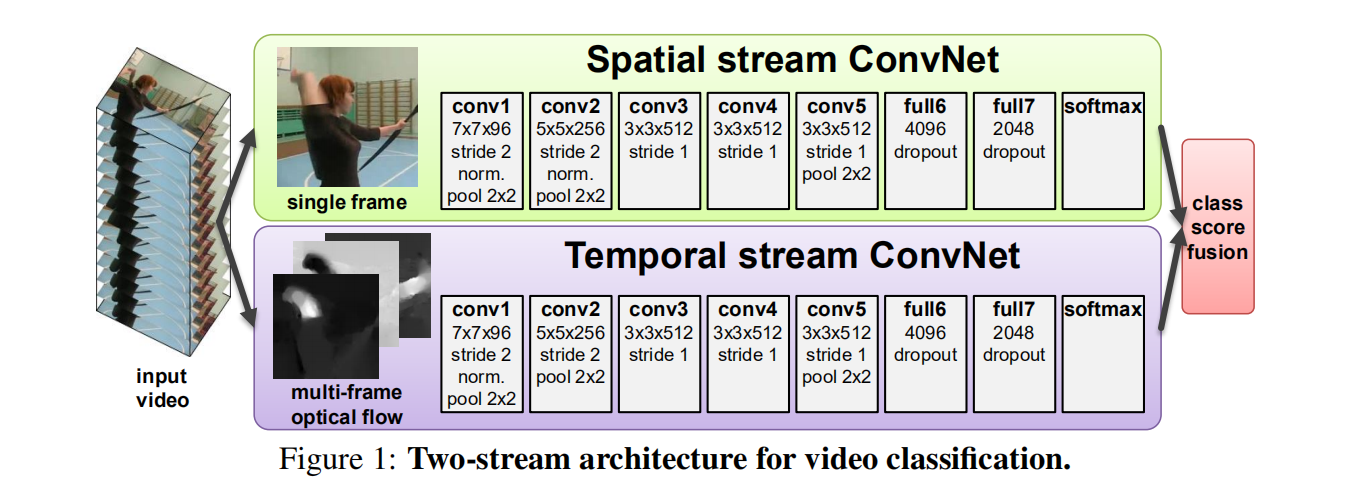
光流convnet
双流的主体在于光流convnet,其输入为堆叠的多个连续帧之间的光流位移场。如何去获取这个输入,文章提供了多种方法:
光流 stacking
轨迹 stacking
上述两种光流可见下图,更能直观描述:
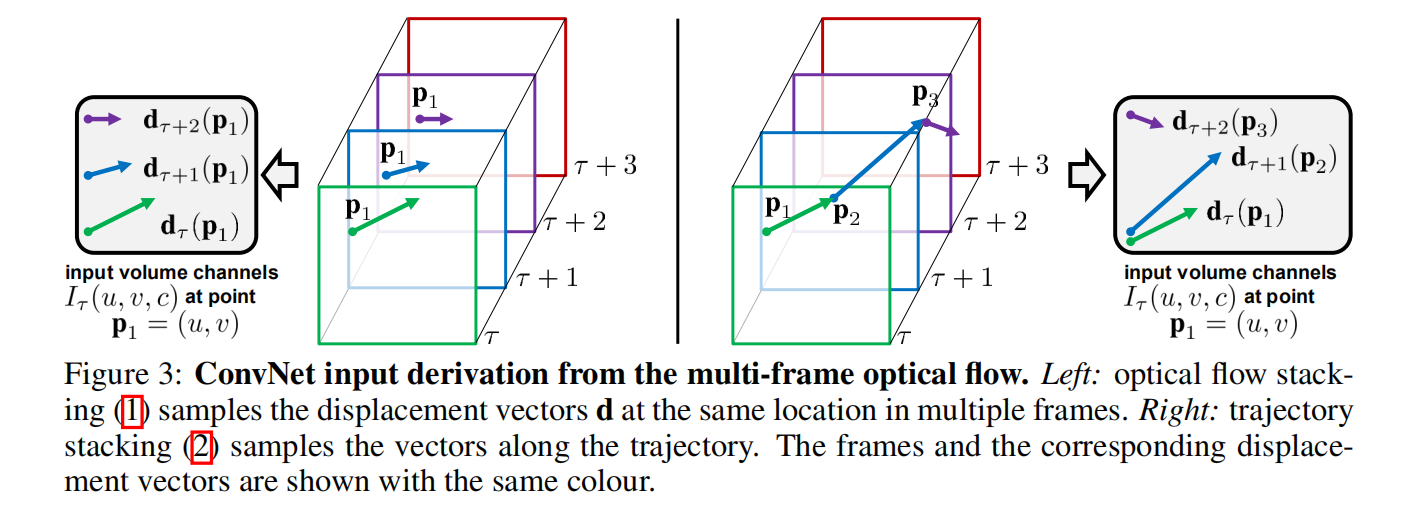
左图将同一位置的x-y方向光流进行堆叠,而右图将沿着轨迹方向的所有位置的位移向量进行堆叠,公式如下:
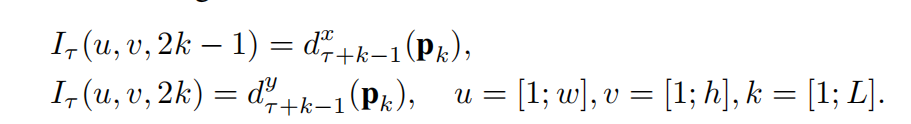
双向光流
上述的两种光流位移场都是单向的,可以将其拓展为双向的,通过堆叠从t到t+L/2的前向光流和从t-L/2到t的反向光流可以得到输入体。
去除平均光流
为了对相机运动进行补偿,论文通过对密集光流计算全局运动部分(均值向量),并将其从位移场减去。
Multitask Learning 多任务学习
因为当时的视频数据集大小较小,所以作者考虑将多个视频数据集进行合并,但是因为有些类别是重复的。基于多任务学习的方法可以有效结合多个数据集。额外的任务(数据集)就像是正则化器一样,能够有效利用额外数据集。在这个场景中,双流架构修改为拥有两个softmax分类层,一个计算 HMDB-51 分类分数,另一个计算UCF-101 分数,每一个分类层都有自己的损失函数。总体训练损失为两个独立任务的损失之和,通过反向传播即可找到权重导数。
fusion method 双流融合方法
经典实验
预训练的效果
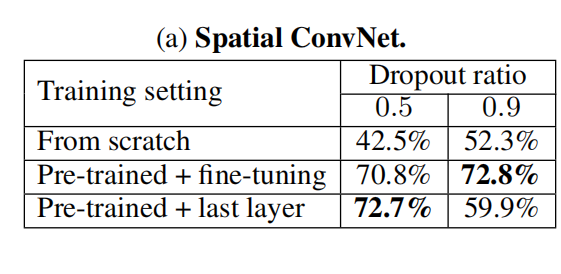
预训练带来的效果提升是巨大的,尽管数据集是图像数据集
不同光流输入的效果

有意思的是仅仅靠光流信息作为输入,他的效果就比spatial convnet效果好了,从一个侧面说明运动信息的重要性。还有个有意思的点,作者也实验了“slow fusion”网络,虽然比单帧效果好,但远没有光流效果好。但是这个实验侧面印证了多帧信息的重要性。
额外数据集的效果

可见,使用多任务学习的方法能够大幅提供hmdb-51数据集的精度。
对双流网络的整体实验
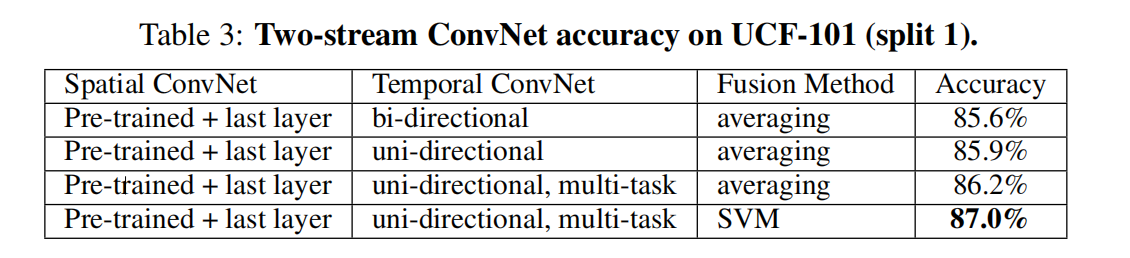
对于如何训练双流网络,作者提供了两种思路:在原网络的两个全连接层之后加一个全连接层,将两个网络的输出作以合并。或者融合两个网络的softmax分数(平均,或是线性softmax函数)。实验证明,svm作为融合方法是最佳的,且融合能大幅提高精度。
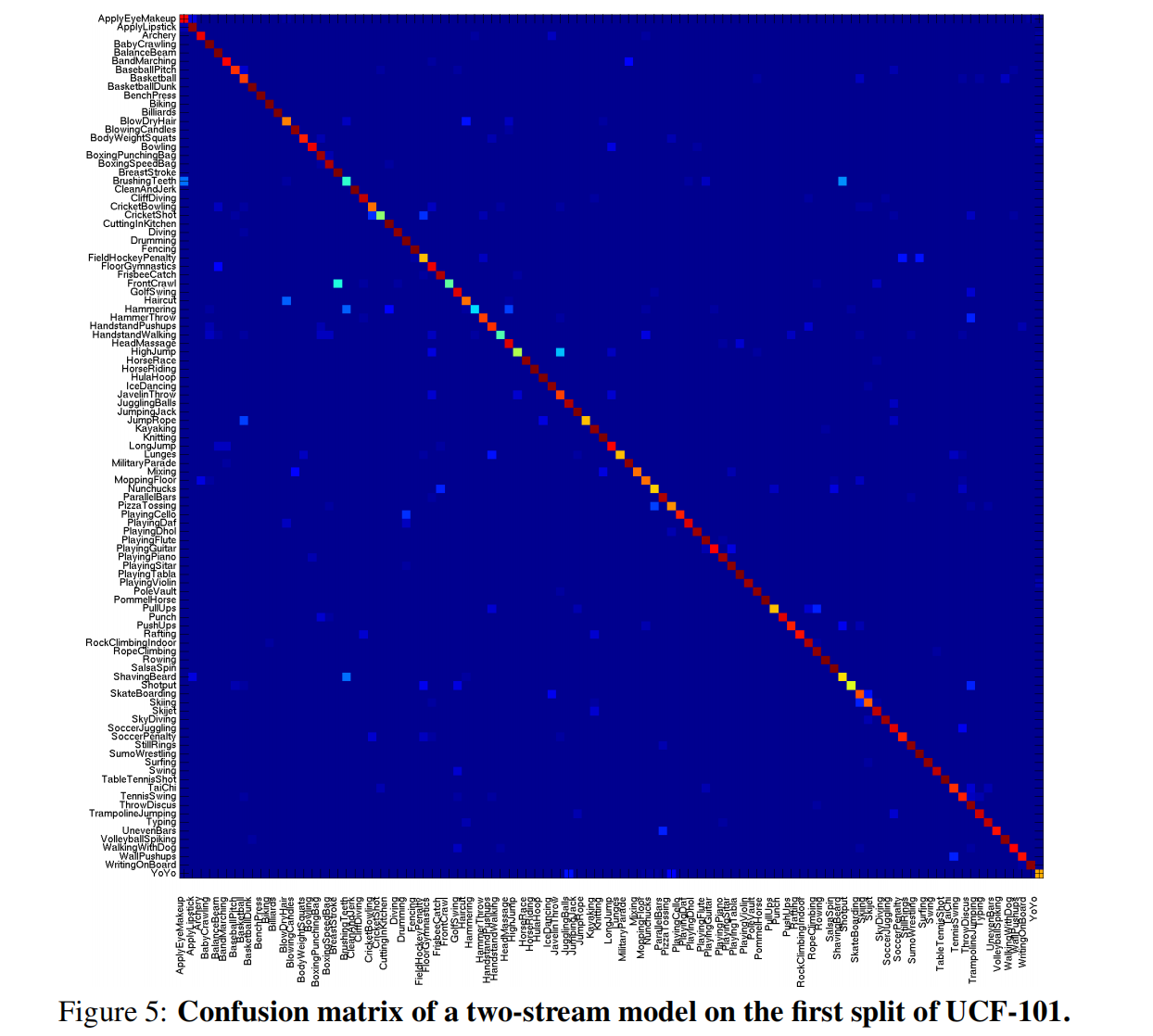
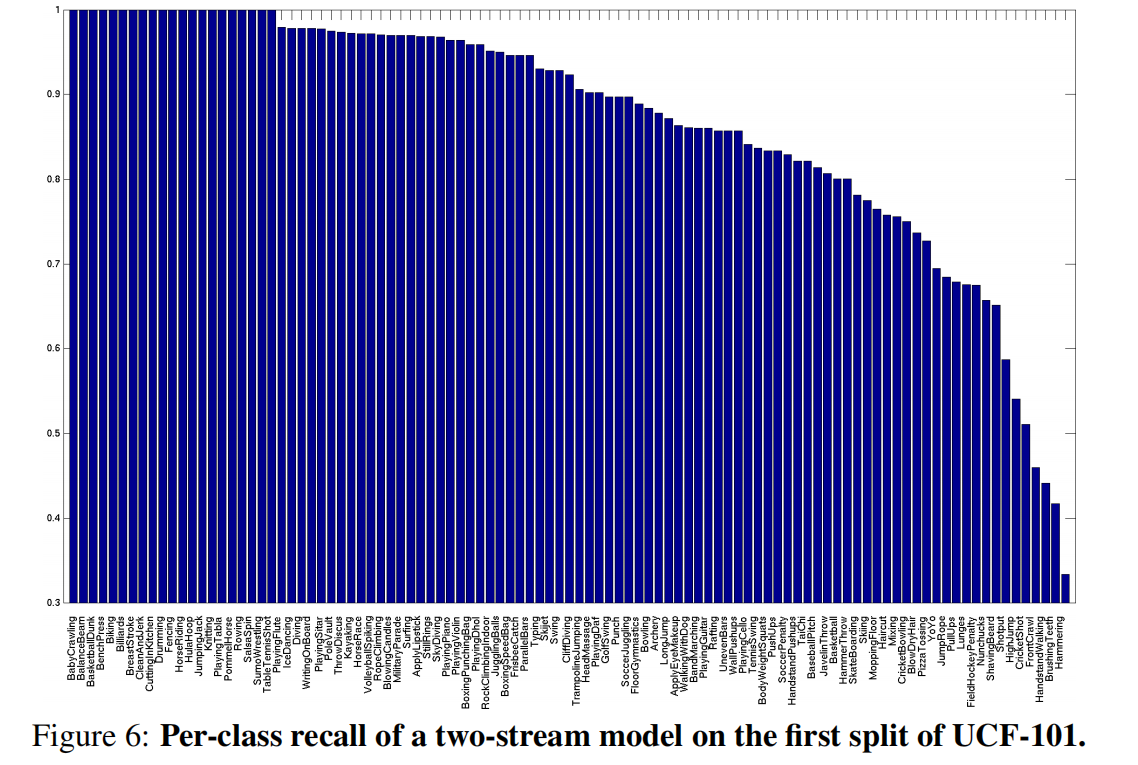
对分类结果的分析
混淆矩阵:
各类的回归率:
- Post title:论文阅读笔记:“Two-Stream Convolutional Networks for Action Recognition in Videos”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_020/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.