论文阅读笔记:“Dynamic Image Networks for Action Recognition”

Dynamic Image Networks for Action Recognition
这篇文章先后发表在了CVPR和TPAMI上,DI可以尝试作为新的输入模态来提高精度
核心思想
动态图像
它就是一个总结了表观和动态信息的标准RGB图像

构建的思想为将视频表示为一个针对它的帧(
从每一个单独的帧It中提取的特征向量表示为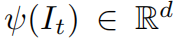 ,用Vt表示直到时间t这些特征的一个时序均值,表示为
,用Vt表示直到时间t这些特征的一个时序均值,表示为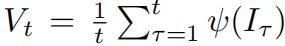 ,排名函数为每一个时间关联了一个分数
,排名函数为每一个时间关联了一个分数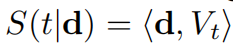 ,这个d就是需要学习的参数,它反映了视频中帧的一个排名。而学习d是一个凸优化问题:
,这个d就是需要学习的参数,它反映了视频中帧的一个排名。而学习d是一个凸优化问题:
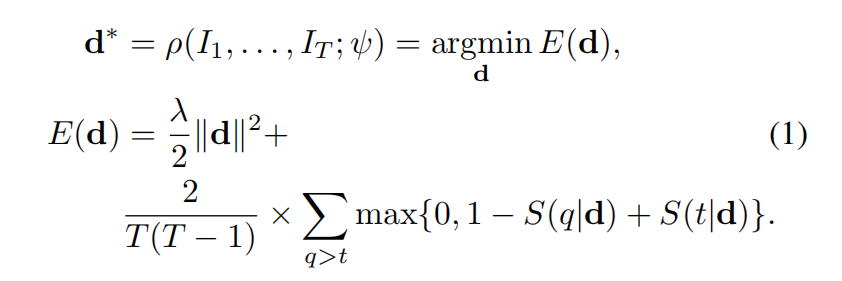
这个公式的本身意义很清楚:越往后的帧会被赋予更大的得分,公式中通过折页loss来表示,但要想在深度学习模型中使用,作者提出了一种近似方法。
作者不像之前论文中对局部特征的fisher vector编码去进行一个排名池化,而是之前应用于像素。于是提取的特征向量表示即为图像中每一个pixel每一个RGB通道的堆叠后的一个大向量。学习得到的参数d*与普通的单帧具有相同数量的元素,并且可以被解释为一个标准RGB图像。动态图片实际上就是通过对整个视频中像素强度沿时间维度进行集成和重排序。
动态特征图
对动态图像的拓展,即我们可以对中间特征图进行rank pooling并得到动态特征图:
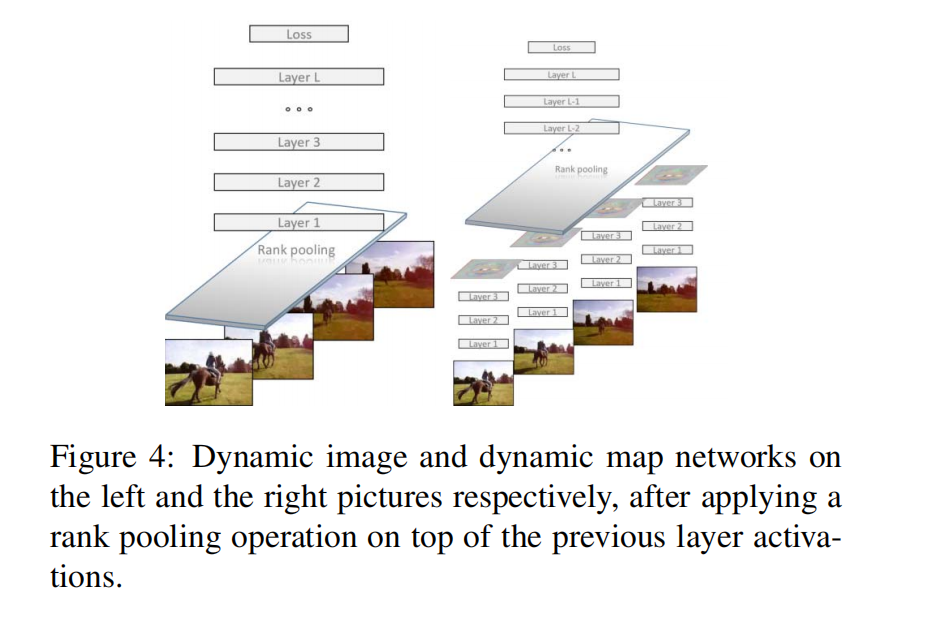
近似排名池化 approximated rank pooling
作者提出了的近似排名池化方法可以插入到CNN网络的中间层,并允许反向传播,提高了rank pooling的泛用性:

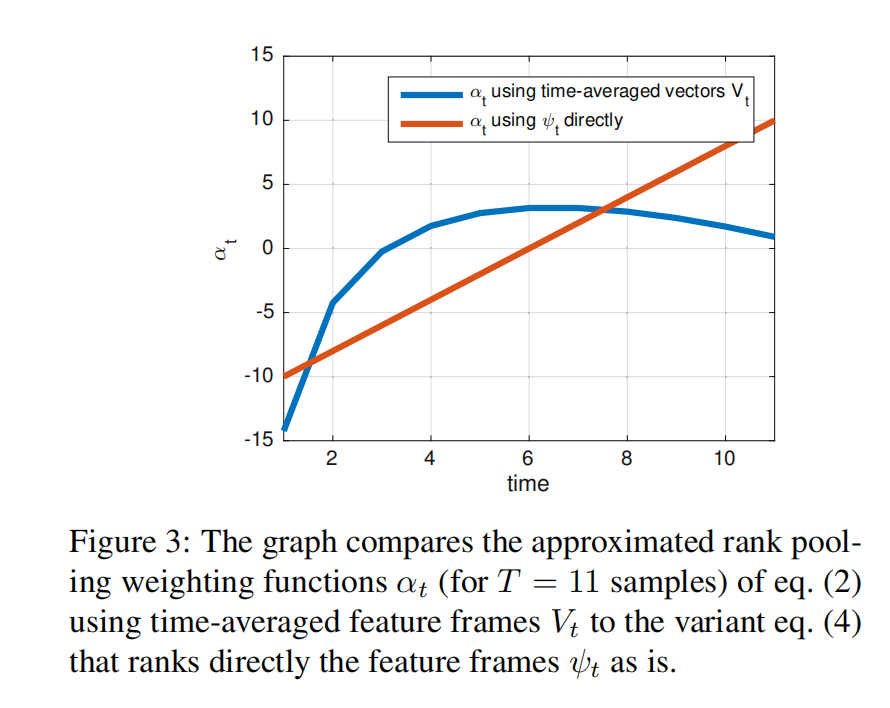
文章还提出了一种线性计算权重系数的方式:
实验效果
ResNeXt-50消融实验
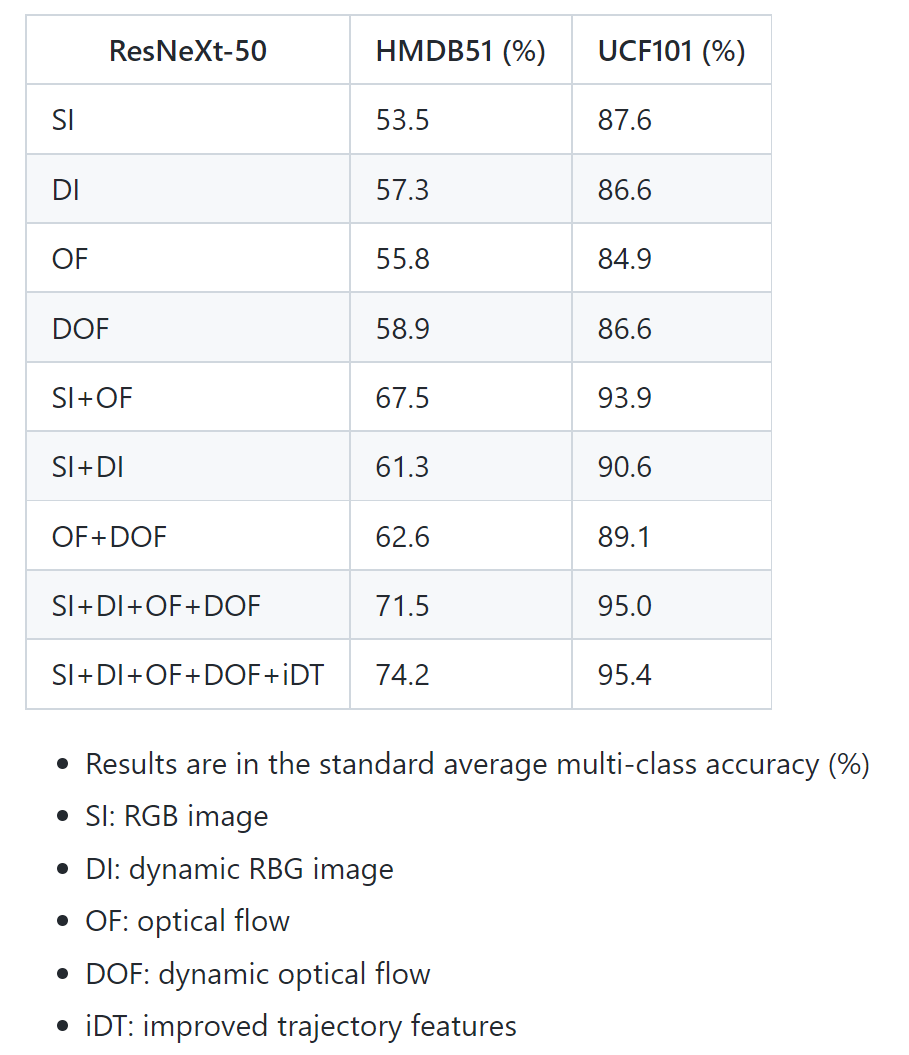
动态图像较视频序列均值图像等优越性
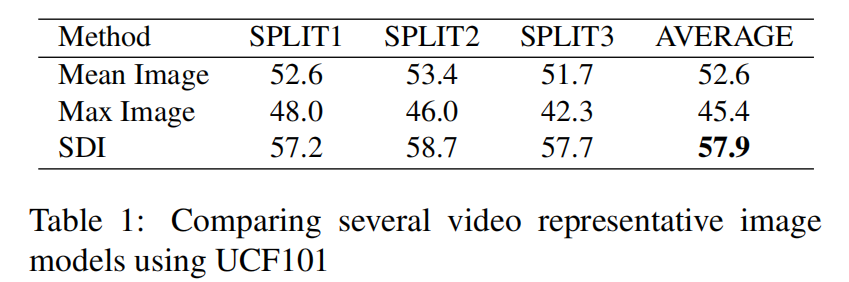
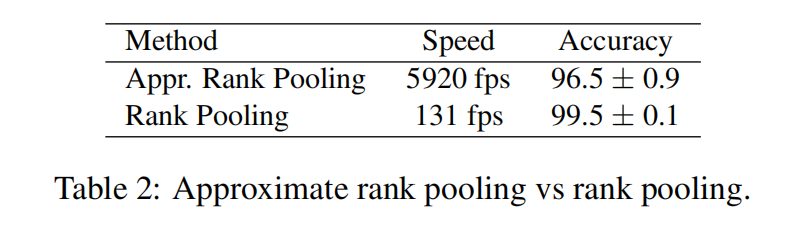
近似排名池化与排名池化的对比
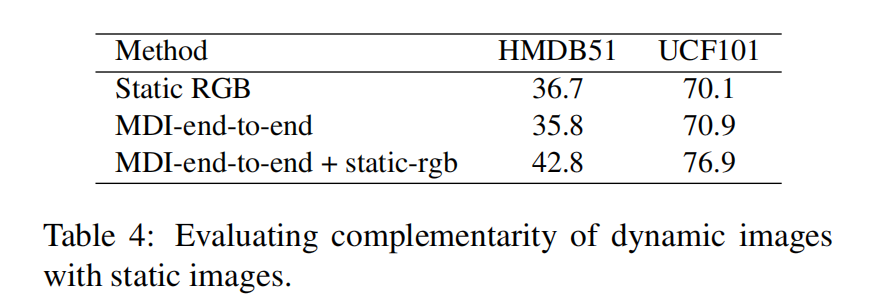
动态图像是对静态图像的补充
- Post title:论文阅读笔记:“Dynamic Image Networks for Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_023/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments