论文阅读笔记:“Convolutional Two-Stream Network Fusion for Video Action Recognition”

Convolutional Two-Stream Network Fusion for Video Action Recognition
这篇文章贵在思路清晰,整篇文章的问题引入及脉络在引言就已经很精彩了,很值得学习借鉴
这篇文章引言其实就是再说,当前领域比起image领域并没有较大成就,原因可能在于数据集过于noisy或者是模型能力不足(提出了一些猜想),之后说之前提出的双流架构还有诸多问题,一是无法将表观的位置线索同时间线索相互匹配,并且无法对这些线索沿时间的变化进行表示(或者说时间感受野太小)。然后作者就在下文依次探索了如何在考虑位置的情况下去融合两个网络,在哪里融合这两个网络以及如何在时间维度进行融合。
核心亮点
空间融合 Spatial fusion 方法搜索
加法融合
最大值融合
连接融合
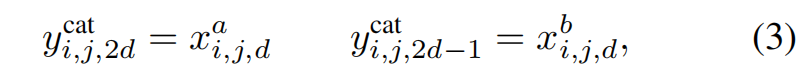
- 卷积融合
- 双线性融合
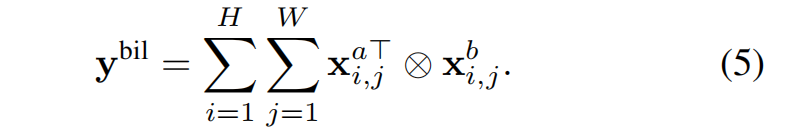
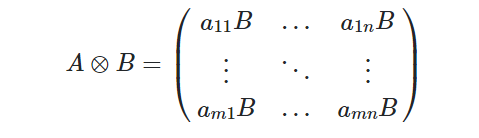
- 逐点乘积融合
这些方法都很直观,对比在下文的实验部分有讲到
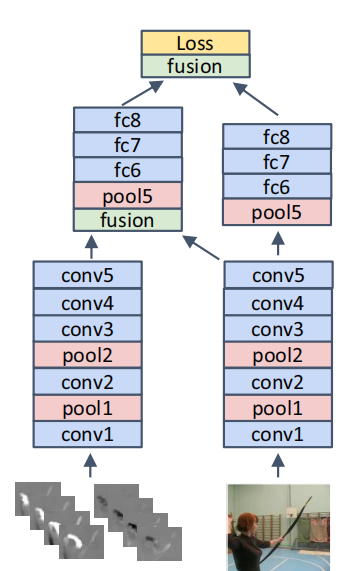
网络结构
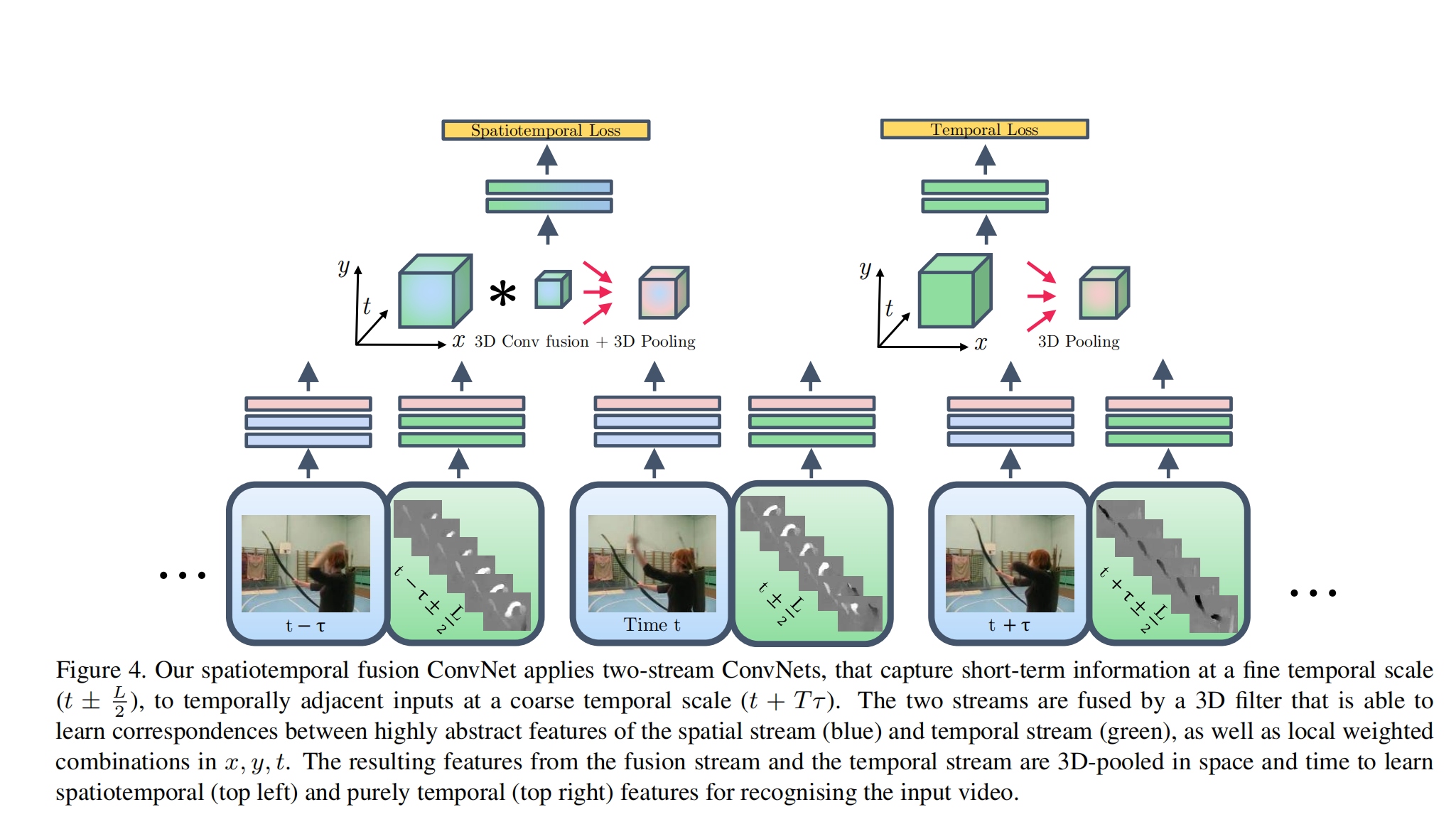
这个网络结构的输入为T个帧,帧间隔为t,时间感受野从之前的L=20扩展为现在的T*L。 融合这些特征图的方法为3D conv 加 3D pooling,但是融合后并不截取光流这一路,因为保留它的效果更好:
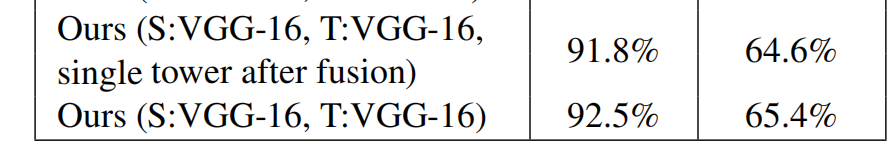
实验结论
不同融合方法的比较
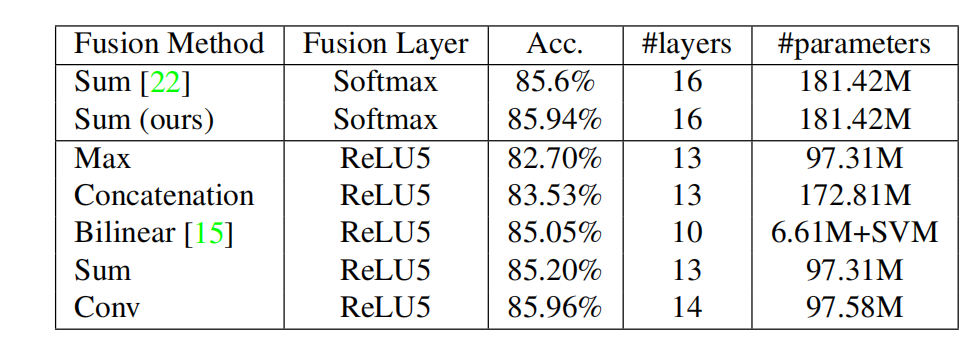
从图中可以看出,简单的sum进行融合效果就已经很不错了,使用conv来融合两个网络效果更好。
在哪个位置进行融合的比较
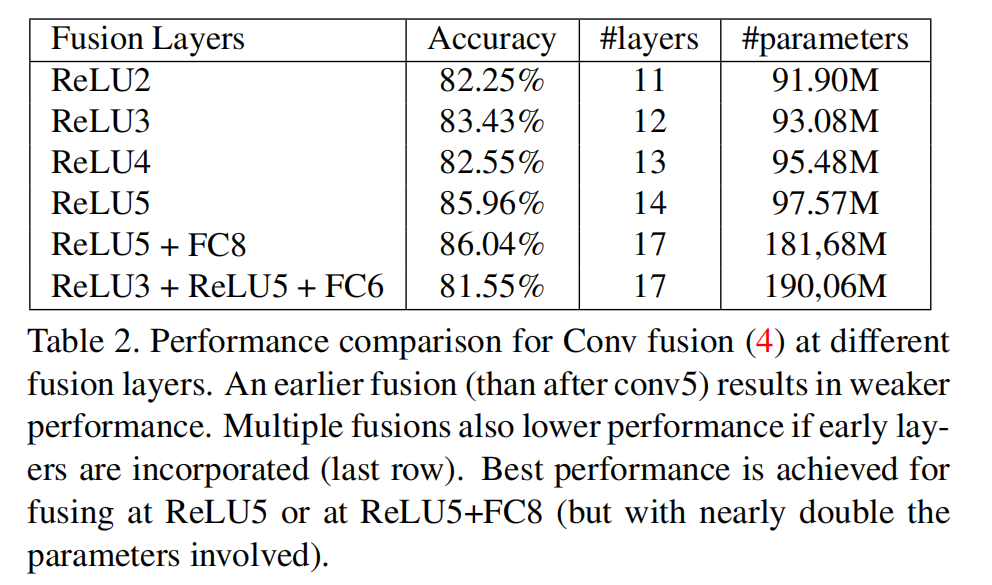
从图中可以看出,越晚融合效果越好,并且不涉及较早layer的多层融合的效果最好:
缺点是这种方法会近似增加一倍的参数量,有点得不偿失。
不同时序融合方法的比较
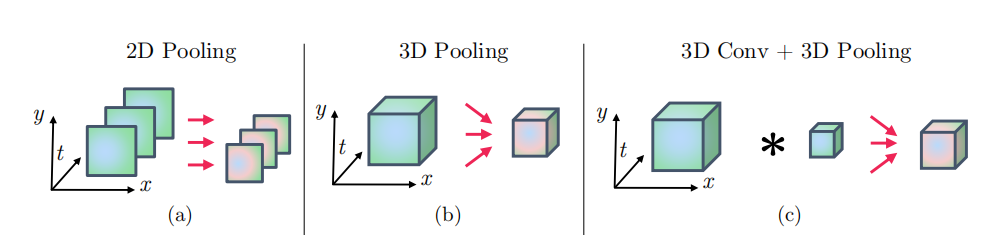
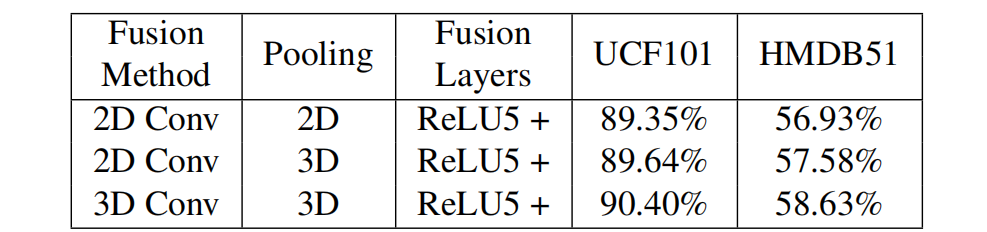
由表可得,3D卷积融合+ 3Dpooling效果最好。
- Post title:论文阅读笔记:“Convolutional Two-Stream Network Fusion for Video Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_024/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments