
Temporal Segment Networks: Towards Good Practices for Deep Action Recognition(ECCV 2016)
引言分析
先从引言开始分析,分析文章的写作思路,说不定对写论文有所裨益,但这篇毕竟较早,所以主要是学习做研究的思路和核心方法。
作者首先说明了如何去提取视频相关信息(表观和动态信息)并不简单,受:
- 规模变化
- 视角改变
- 相机移动
等因素影响。之后作者说明了现状:深度学习方法并不比传统方法好多少,并分析了卷积网络受阻的原因:
- 缺乏对长时序建模的架构
- 数据收集和标准较为困难,而卷积网络需要大量训练样本进行学习
因此,文章针对上述问题提出了对应的解决方案:
- 设计一个能够对长时序进行建模的有效且高效的视频级别的框架
- 如何在训练样本受限的情况下让卷积网络进行学习
作者认为,连续帧之间包含较多重复,因此密集时序采样是不必要的。因此作者采用了稀疏时序采样策略(所需的计算资源会相对较少),并设计了时序段网络(TSN)。对于数据量较少的问题,作者通过三种方式来解决:
- 跨模态预训练 cross-modality pretraining
- 正则化
- 加强了的数据增强
核心思想
short snippets sequence 小片段
从整个视频里稀疏采样的小片段,每个short snippets都会产生一个动作类别的预测。紧接着,段共识函数(求平均)将多个snippets的输出进行结合以得到一个关于类假设的共识。基于这个共识,预测函数(softmax)即可预测视频属于每一个行为类别的概率。
新的输入模态
- RGB difference
相邻两帧间的RGB difference可能与运动主导的区域相关。
- warped optical flow fields(扭曲光流场)
相机运动可能会对光流场造成影响
跨模态预训练技术
实际上是描述了怎么对于光流输入的temporal卷积网络的第一个卷积层进行初始化。
防止过拟合
- partial Batch Norm,固定除了第一个BN层外的所有BN层。
- dropout,加入BN-inception的全局池化层之后。
- data augmentation,包括随机裁剪,水平翻转,shape抖动,以及角裁剪。
网络结构
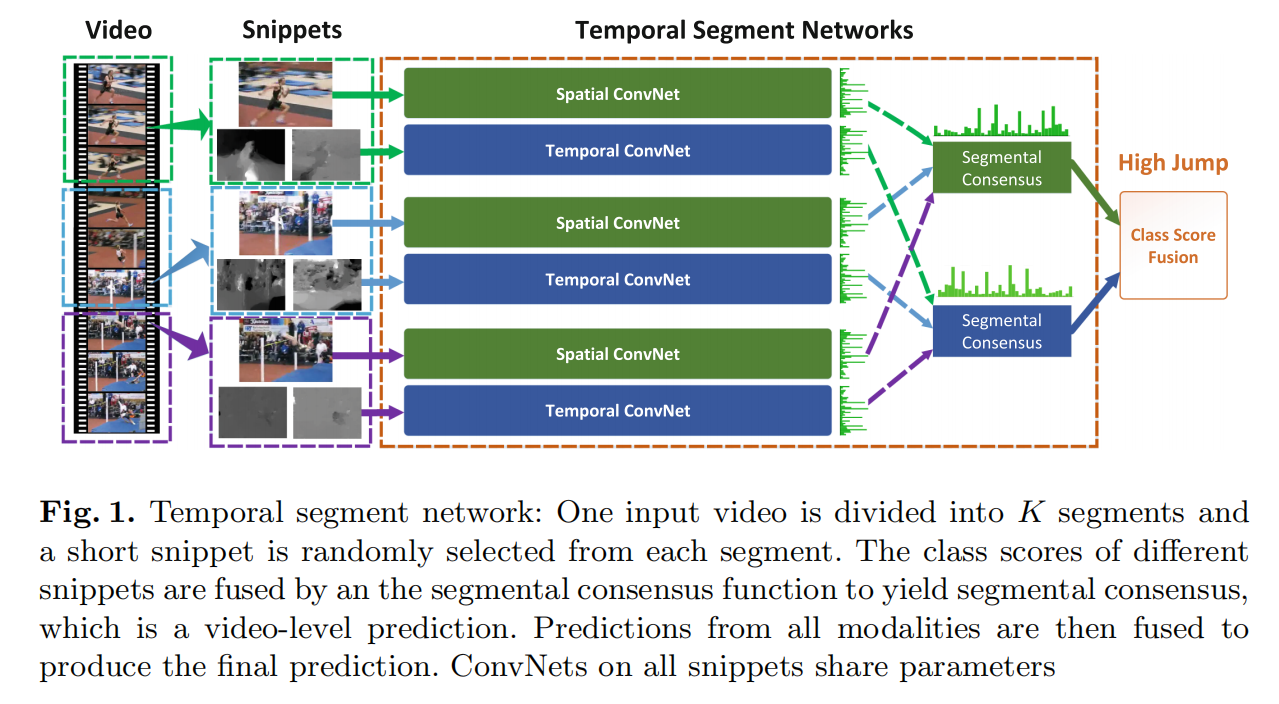
如图,该结构基于双流结构,本质上是2D模型。
实验结果
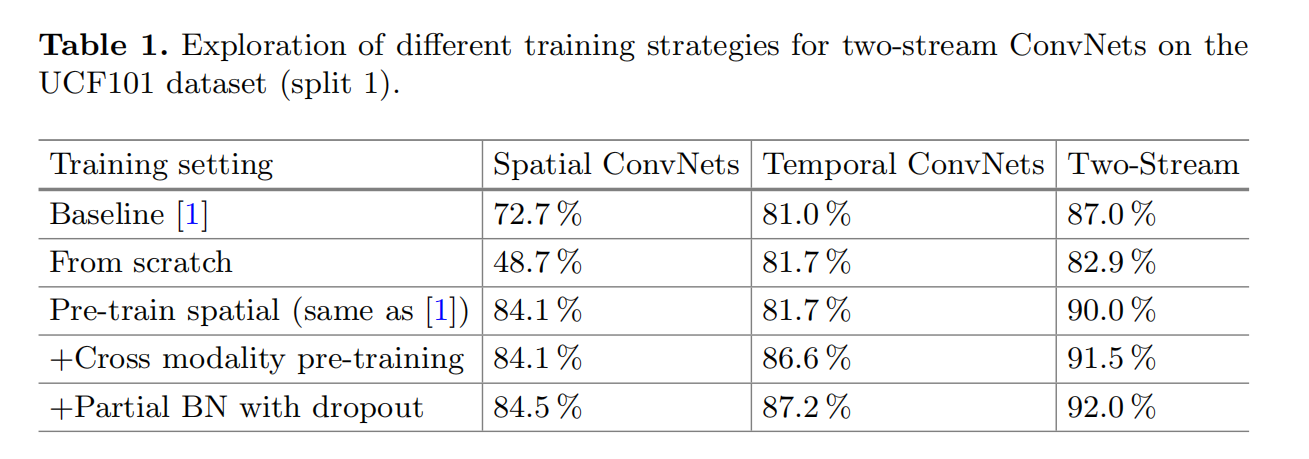
训练策略对于精度的影响
不同输入模态对于精度的影响
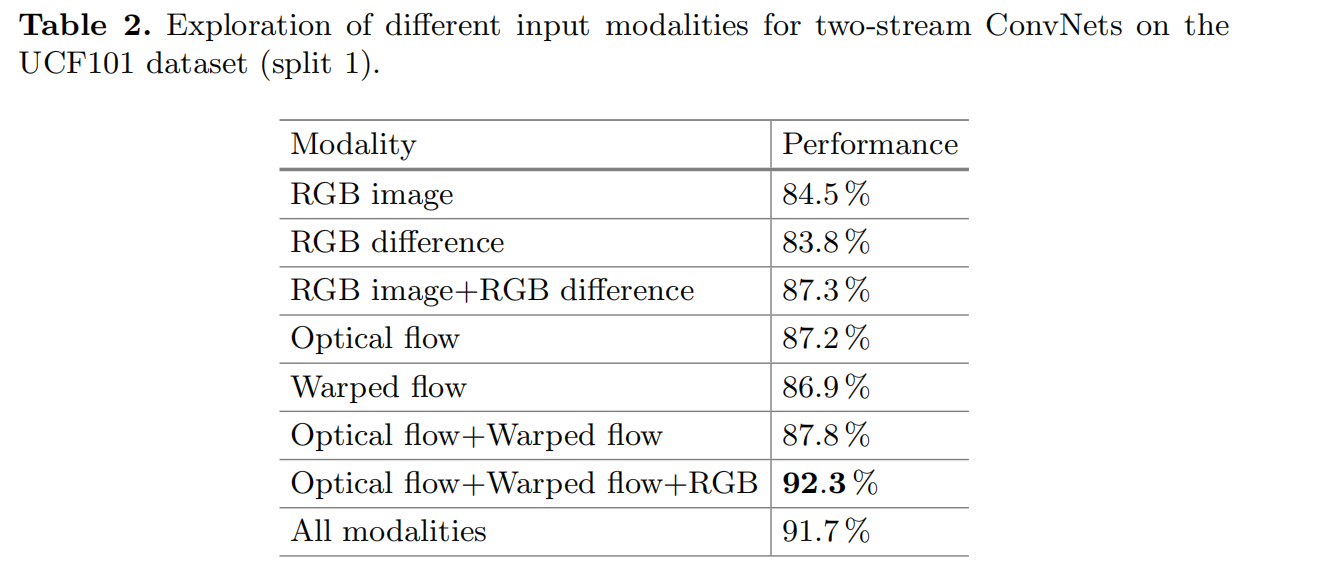
从图中可以看出,RGB difference有时不太稳定,所有模态数据在一起时反而会会降低精度。
不同段共识函数对精度的影响

不同深度网络架构对精度的影响
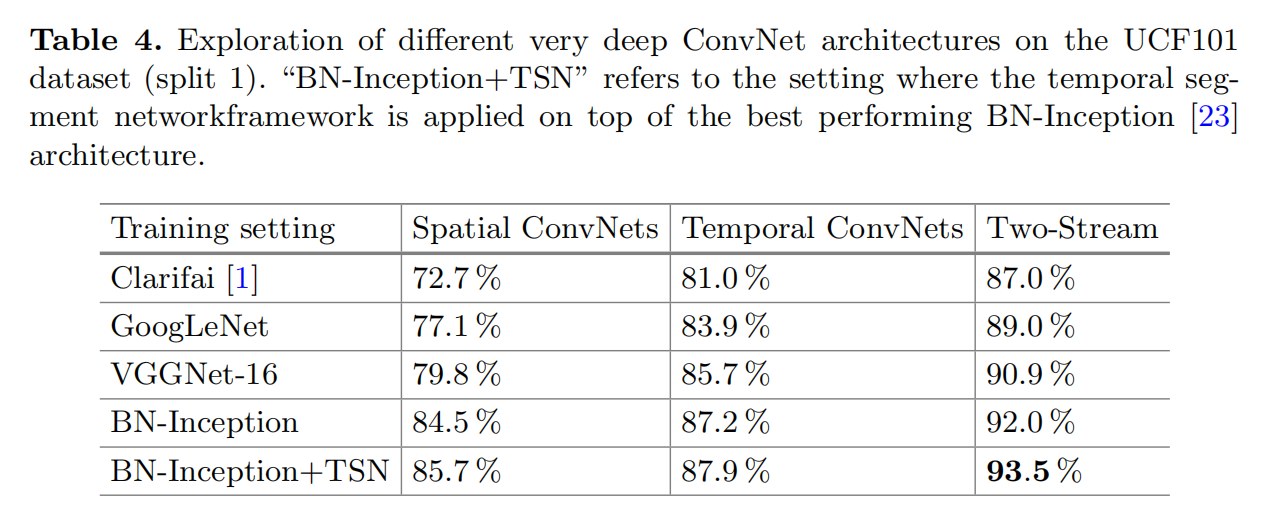
对于长时序进行建模的重要性

网络可视化
论文使用了DeepDraw [42] toolbox来对网络效果进行可视化

从图中可以看出,预训练对于捕获结构化视觉模式有一定帮助,同时对长时序进行建模也使得网络更关注运动的人而不是其他客体。
- Post title:论文阅读笔记:“Temporal Segment Networks: Towards Good Practices for Deep Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_025/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.