
Real-world Anomaly Detection in Surveillance Videos
这篇文章写得巨好,看完有种“原来是这样”的感觉,不愧是顶刊的文章。之所以看视频异常检测的文章,一方面是想深挖行为识别方向的具体应用,让研究方向变得更细一些。另一方面是群体行为检测和异常行为检测之间有着密切联系,希望能够触类旁通,将这两个任务结合起来。
核心亮点
多实例学习 Multiple Instance Learning(弱监督学习)
这篇文章的写作手法真的很循序渐进,首先向我们介绍了标准的有监督分类任务的SVM优化函数:
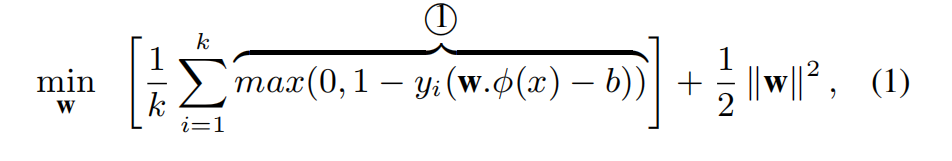
但是在有监督异常检测的情景下,分类器需要视频中每一个段的标注,但是对这种视频进行标注真的很浪费时间和人力。所以提出了MIL,它可以放宽对标注的要求,只需要对视频级别做标注即可,我们不需要知道异常行为的发生位置及时间点。因此我们可以将异常视频看作一个positive bag,视频的不同时序段组成了包中的个体实例。因为严格的正实例是未知的,所以我们可以选择scores最高的实例来对目标函数进行优化:
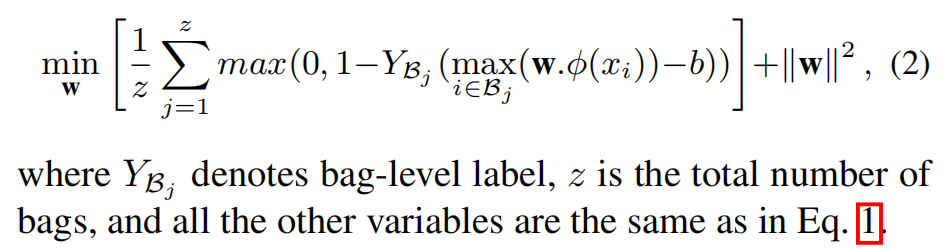
介绍了什么是多实例学习之后,作者使用了ranking的思想,将深度模型与MIL相结合,提出了 Deep MIL Ranking Model,如下图所示:
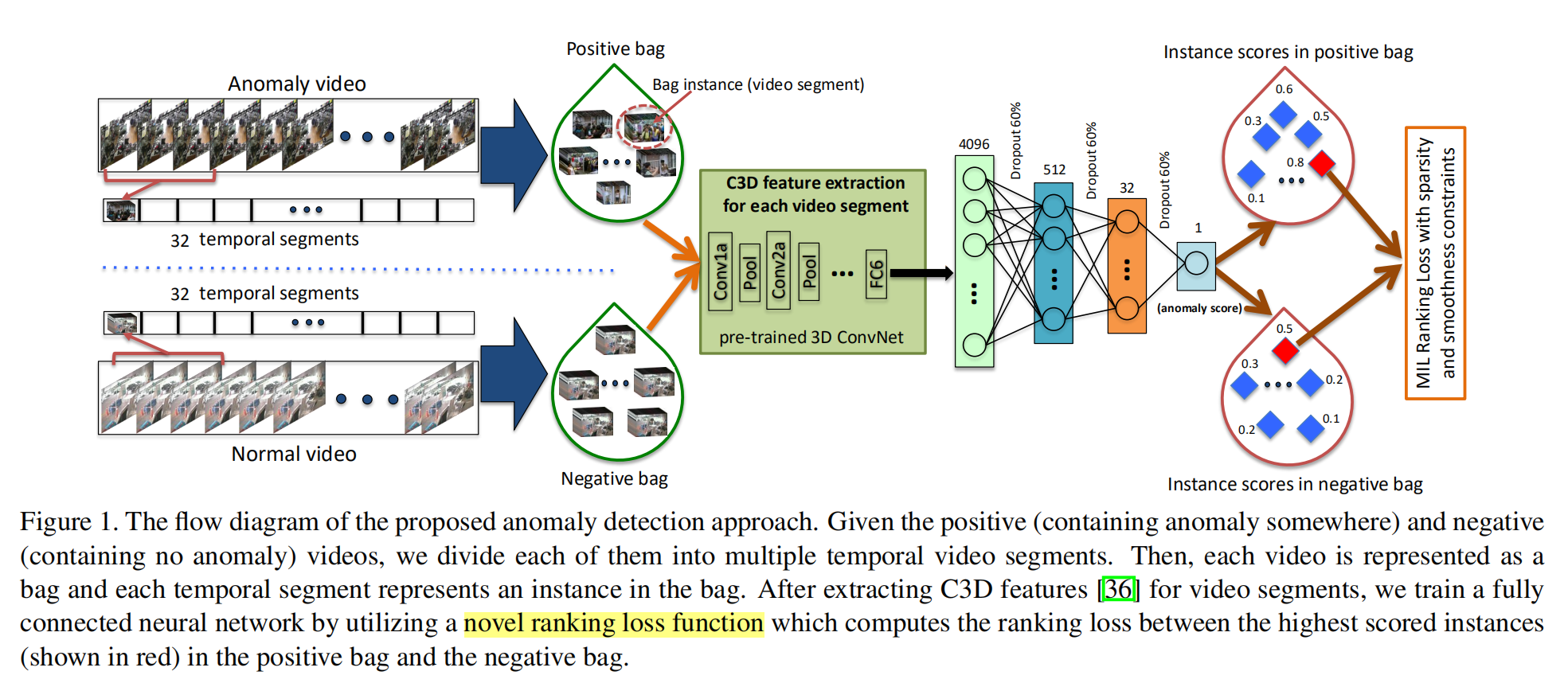
因为异常检测的模式检测可能性较小,因此作者将异常检测问题当作了回归问题,希望异常的视频片段比起正常片段具有较高的异常分数。使用一个排名损失函数(rank loss)可以鼓励异常行为片段具有更高的分数:
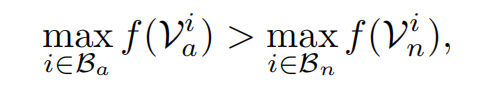
论文中只让正常和异常bag中包含的最大分数的实例进行排名,其实也很好理解。因此hing-loss的数学形式化表达如下:
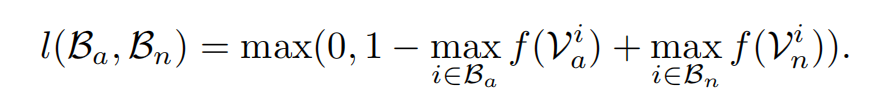
但是这种loss也有缺陷,它忽略了视频里的长范围的时序关系。首先,在异常视频中,异常往往只发生在一小段时间内,所以异常分数应当尽可能的稀疏,其次,视频中的段是连续的,因此异常分数在相邻段之间也应变化得较为平滑。对loss进行优化后,损失函数变为了:

最终完整得目标函数即为:
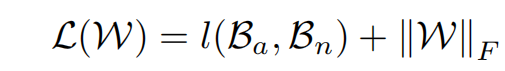
其中,W指的是模型权重。
提出新数据集
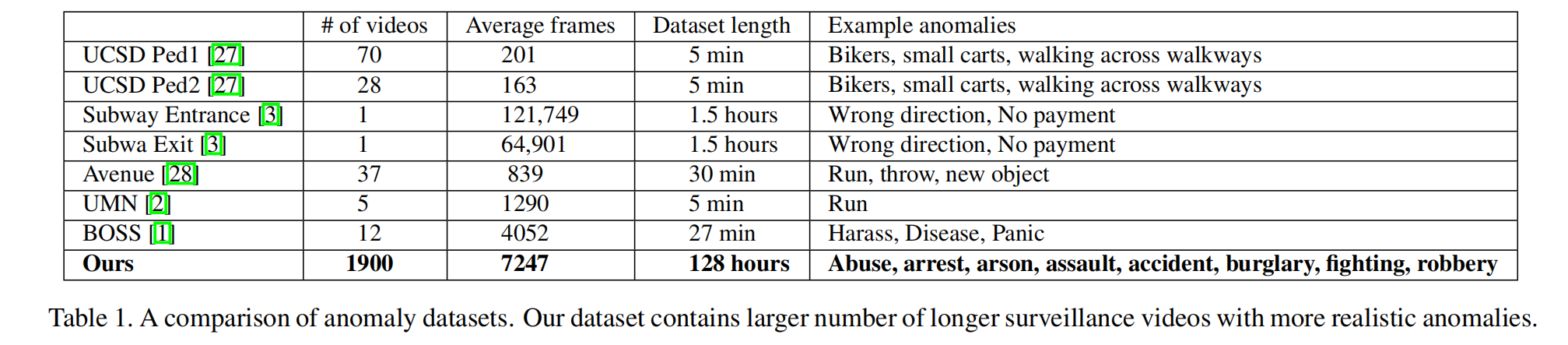
就算只是1900个视频,完成收集和标注也需要数人数月的努力。

各个异常类的视频数如上图所示。
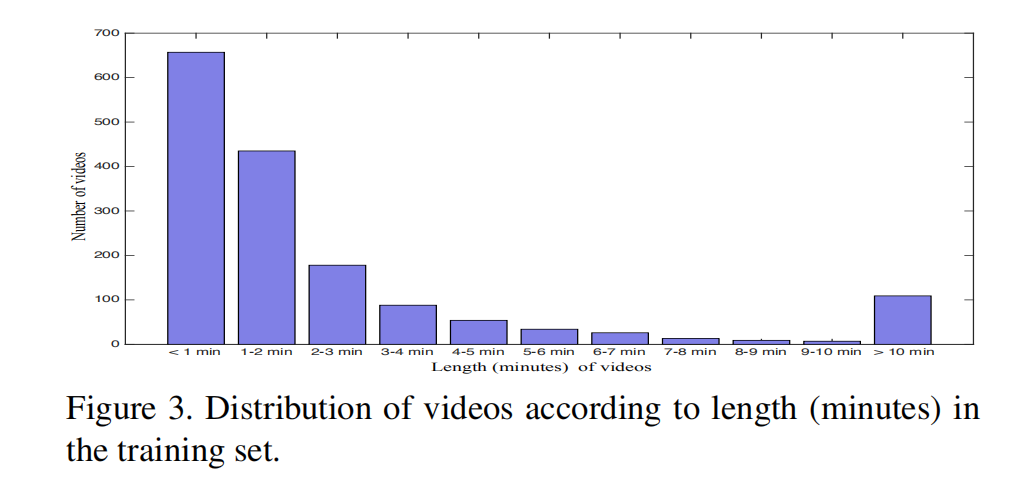
数据集关于时间的分布如上图所示。
实验结果
与state of arts方法的对比
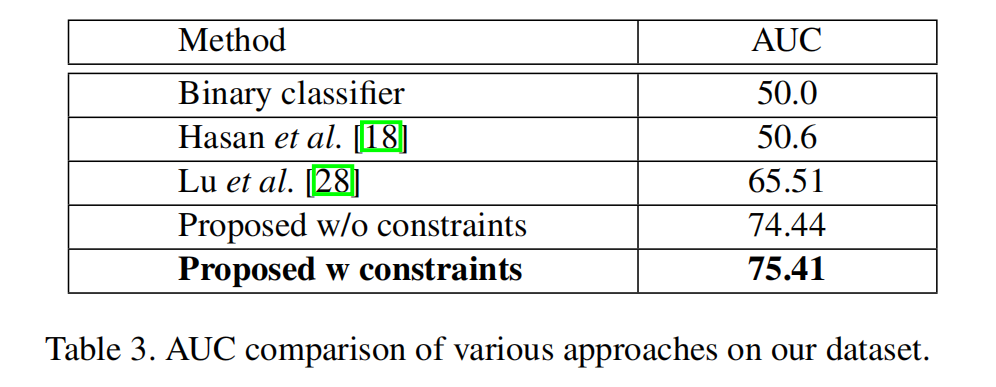
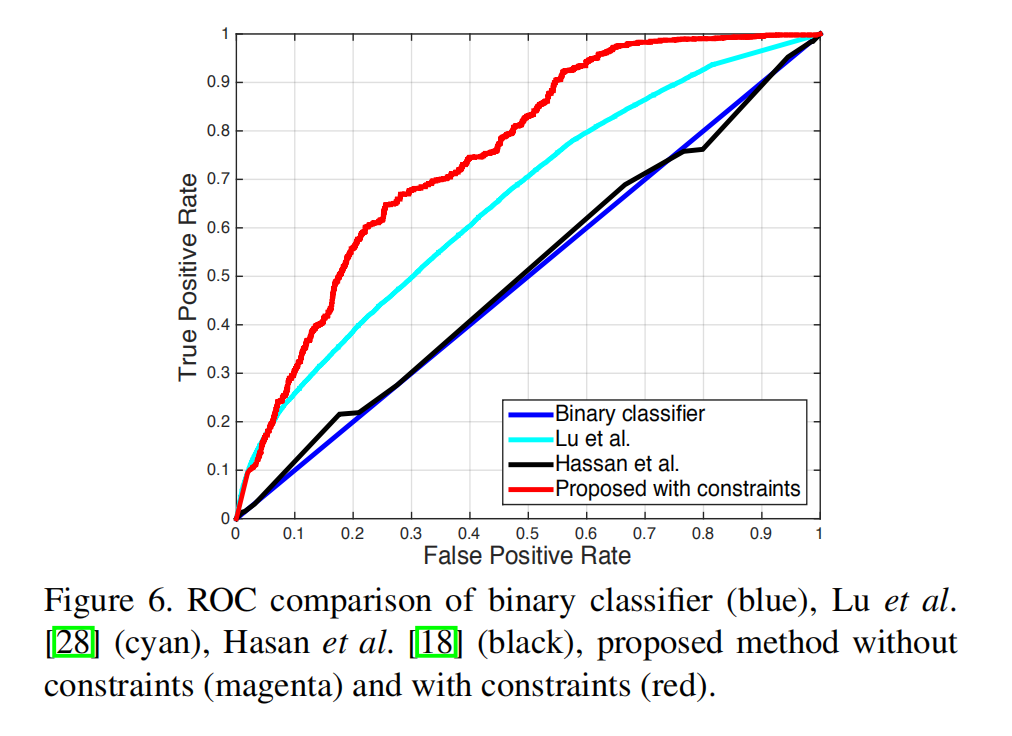
实验证明,提出的方法在更低假阳率的情况下具有更高的真阳率。而且传统的行为识别方法Binary classifier不能直接拿来用于异常检测,因为异常行为的持续时间相比起整个视频而讲很短。
对于提出方法的分析
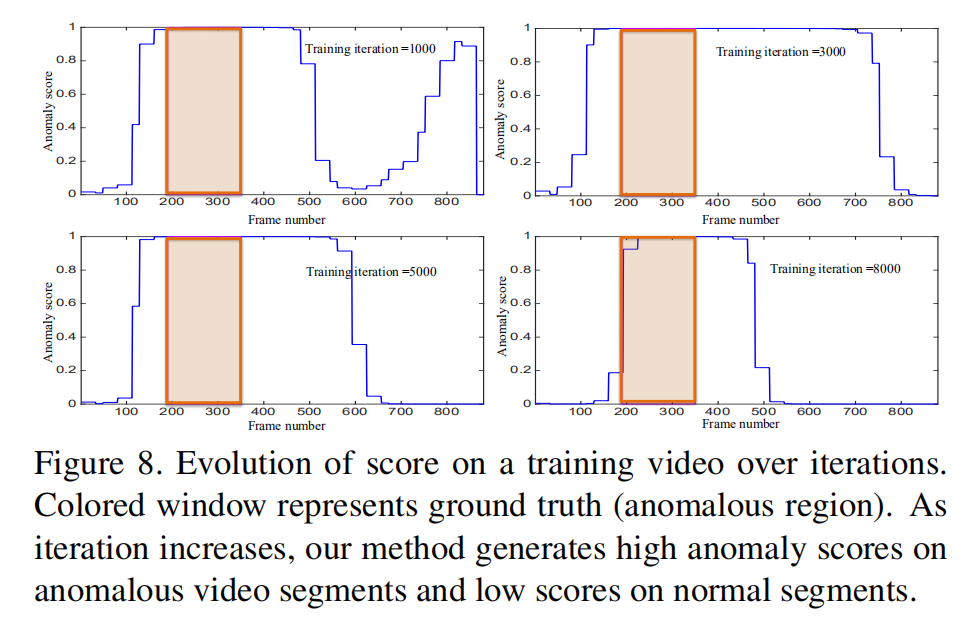
上图为随着训练迭代数的增加,异常得分的变化曲线,可见在未知段级别标注的情况下,网络依旧可以预测异常的发生时间。

从错误预警率也可看出该方法超越了state of arts方法。
扩展任务:异常行为识别
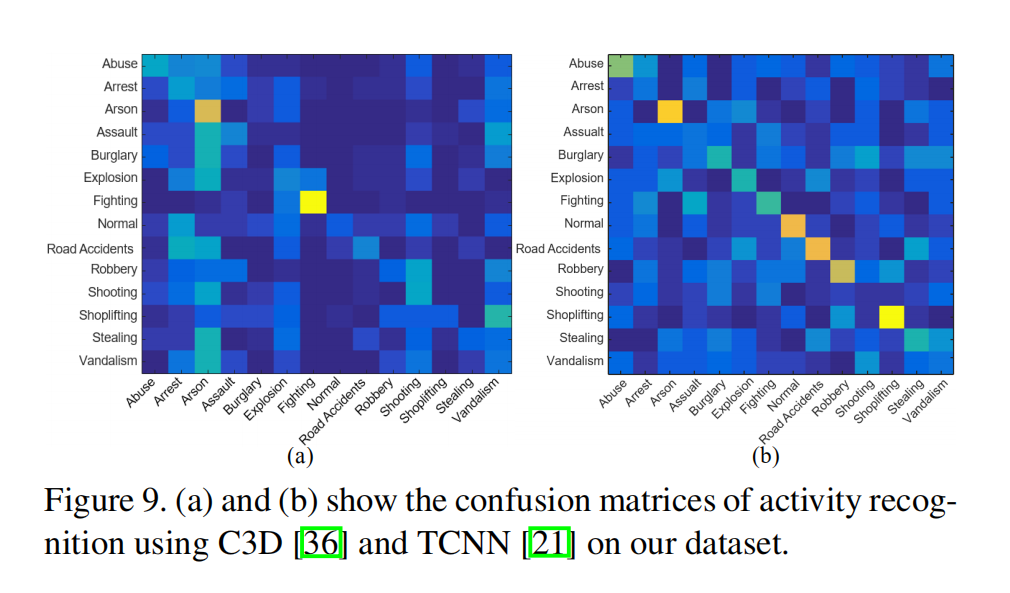
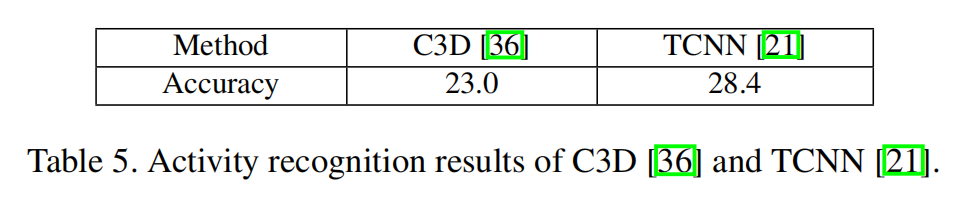
作者在提出的数据集上使用C3D和TCNN进行了实验。可以看出实验结果很差,原因可能是数据集较长未裁剪,并且分辨率较低,还有较大的相机视角移动以及光照,背景噪音所产生的较大类内差异。
- Post title:论文阅读笔记:“Real-world Anomaly Detection in Surveillance Videos”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_027/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.