
Hierarchical Relational Networks for Group Activity Recognition and Retrieval(ECCV 2018)
一句话概括
这篇文章的要点在于对场景内的人的结构化关系进行建模,提出了层次式的关系网络,并在监督和非监督的应用中使用了这个模型。
引言分析
首先文章将来人类行为识别有多么多么难,人群行为识别是在什么情境下产生的,现在这个方向面临着什么什么挑战。为了解决了这个问题,作者提出了一个多么多么牛逼的模型。
然后说,目前的人群行为识别基本都是两阶段模型,第一阶段首先得到每个人的特征表示,第二阶段就是将这些表示统统结合起来构建一个场景的最终特征表示,最后送入分类器进行分类。但是目前这些场景池化方法都不可避免地损失了重要信息:首先空间位置信息和关系信息被丢失,其次个人的特征(从某种程度上对人群行为而讲有巨大影响)也没有保持。因此,作者提出了层次式的关系网络,尝试对以上问题进行解决。
核心亮点
关系层 relational layer
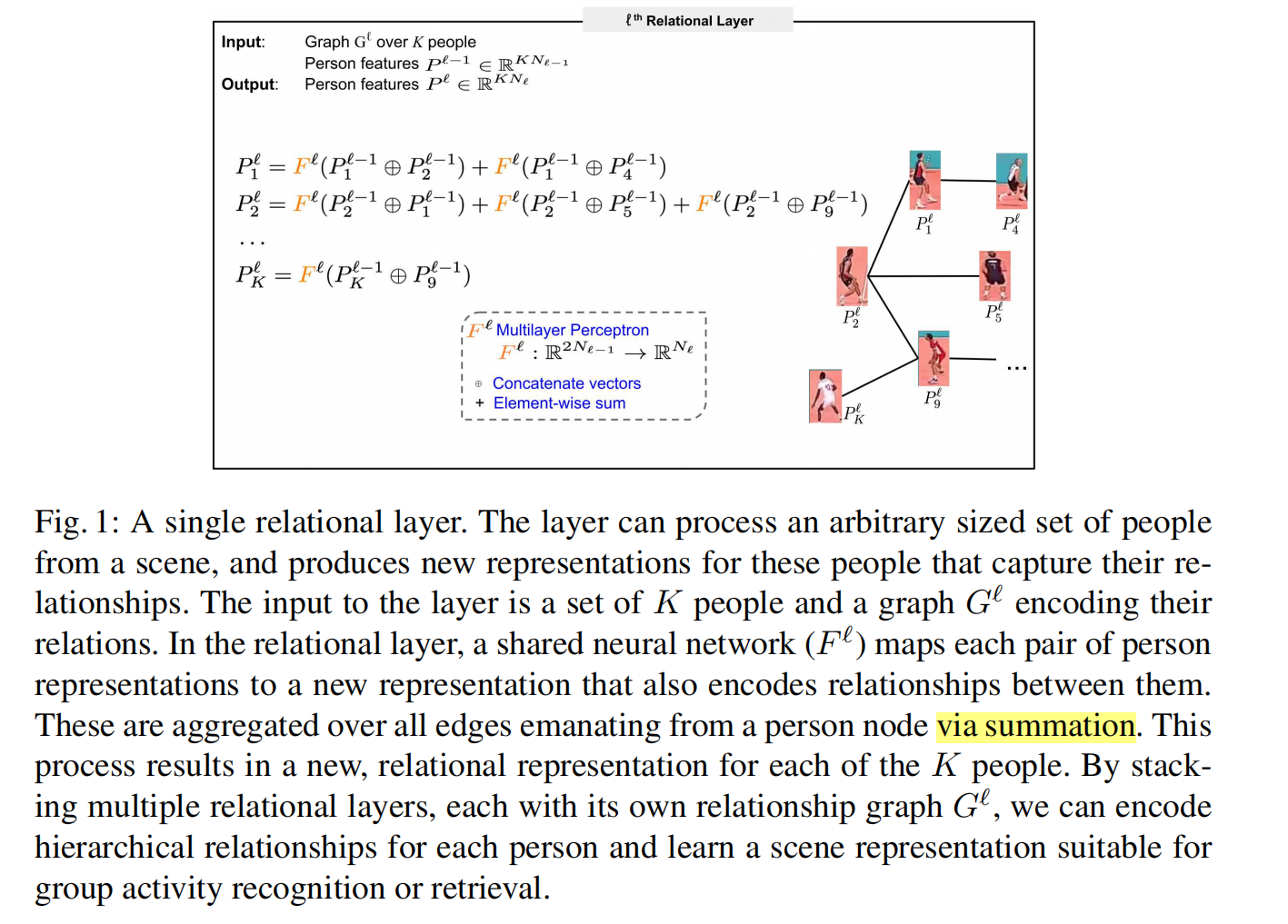
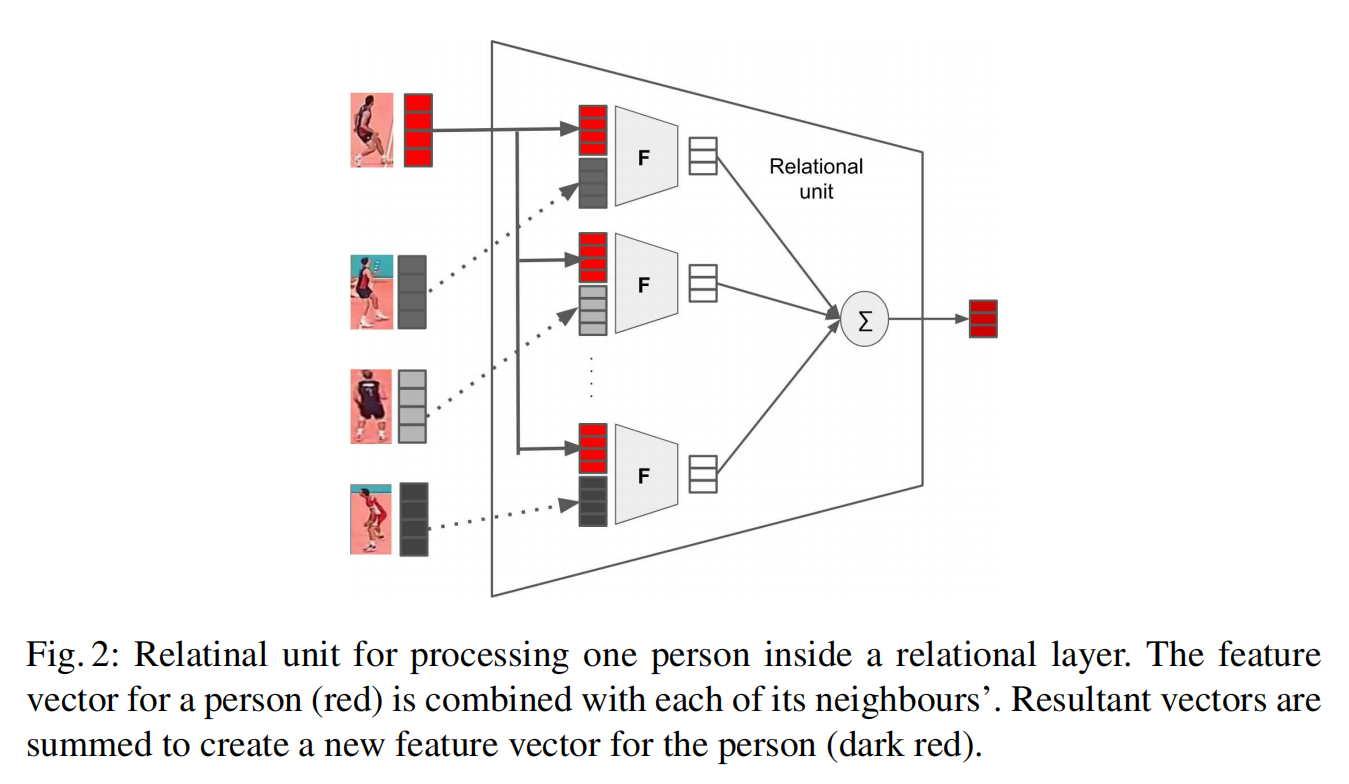
简而言之,对于每一个人,将其与和他相邻的所有结点(需要已知关系图结构)进行连接,并送入多层感知机进行处理,将处理得到的所有关系进行相加来聚合关系信息。关系层不仅可以编码关系信息,还可以压缩信息维度。下图清楚地解释了每一个人的处理过程:
对relational autoencoder进行去噪
若人检测器检测失败,相机移动,低相机分辨率等原因导致了某些人在场景中丢失了,论文提出了一种去噪方法,那就是在训练时丢掉K个特征向量中的某些个向量,实现即在输入层之后加一个dropout层即可。
网络结构
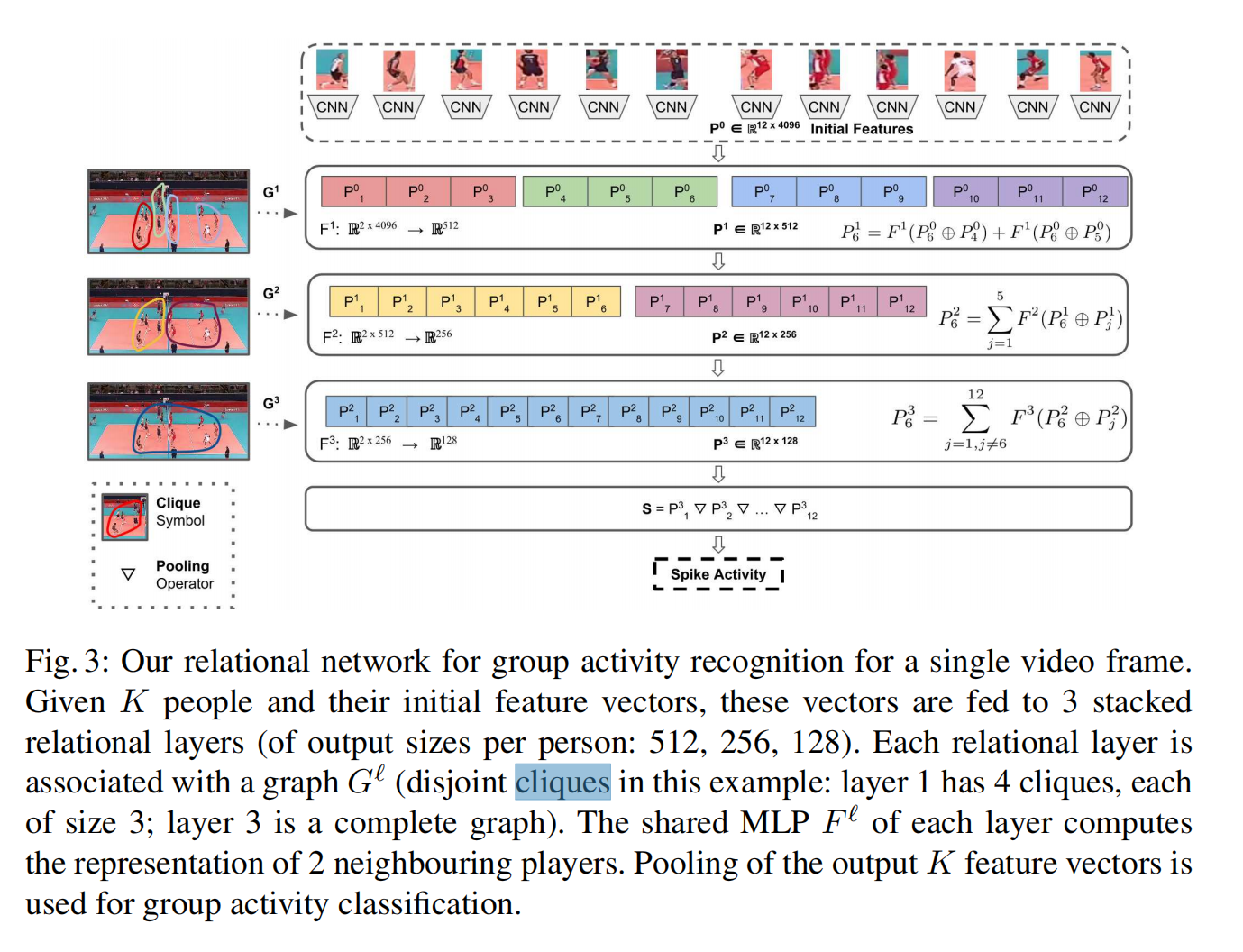
每一层相同颜色的特征向量为一个连通分量。如图所示,该网络结构堆叠了三个关系层,每层都将特征维度减少了一半,最后对最终的关系表示进行池化。每层每个人的特征计算形式化表示如下:
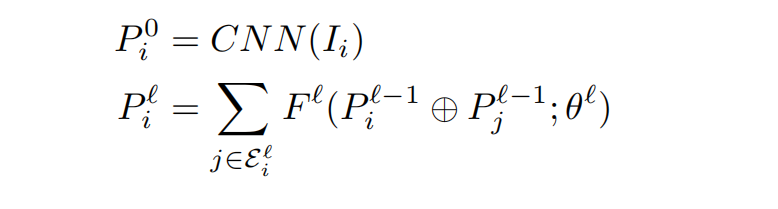
应用于人群行为识别方法
将每一帧的场景表示St送入LSTM层进行处理并将结果送入softmax层进行预测。但是池化的过程中,个人的信息被总体抹去了,所以LSTM的作用时间上是对于整个场景的时序进行建模。
从这里也可以看出这个方法的一个缺陷,那就是只对关系而没有对个人的时序进行建模,而且对于关系的建模我觉得只是concate+mlp其实有点粗略。
应用于行为检索方法
对每一个检测框进行标注及其浪费时间,作为替代,我们可以利用使用无监督的autoencoder机制来学习场景中人的特征表示。可以通过比较这些基于关系和情景的表示,我们即可对某个人的行为进行检索,或是对整个场景进行检索。
关系autoencoder模型如下图所示:
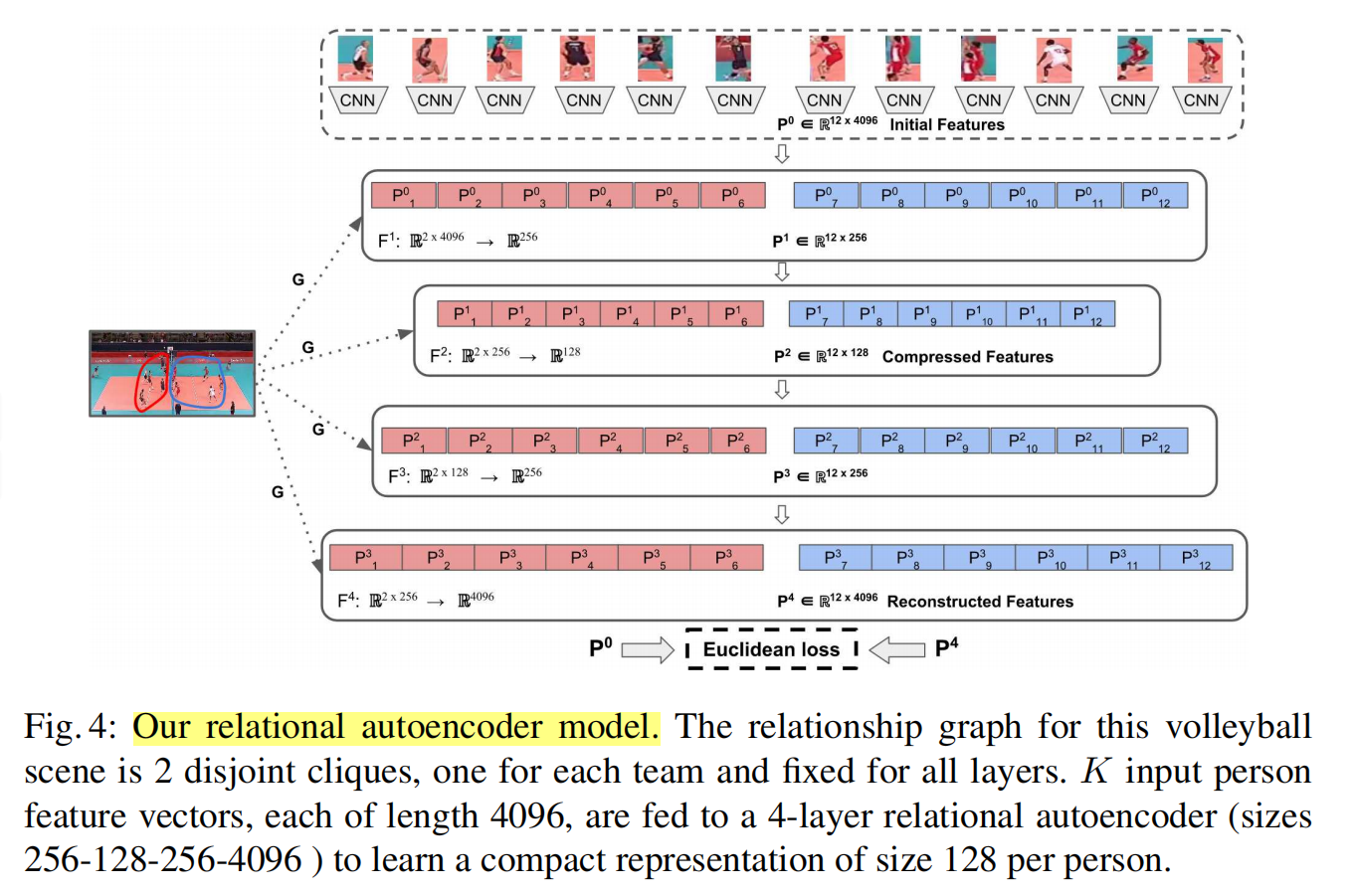
relational autoencoder模型首先使用了两个relation layer进行encode,接着使用了两个inverse relation layer进行decode。输入场景和重建后的场景特征的重建损失如下:
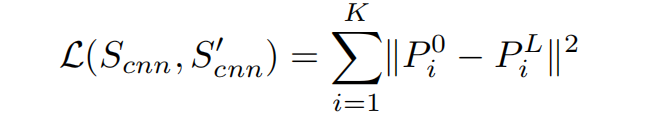
注意,这个行为检索的方式不是检索具有总体行为的场景,而是检索具有相同行为场景结构的场景。论文使用了KNN最近邻算法来检索行为视频数据库。
实验结果
群体行为分类消融实验
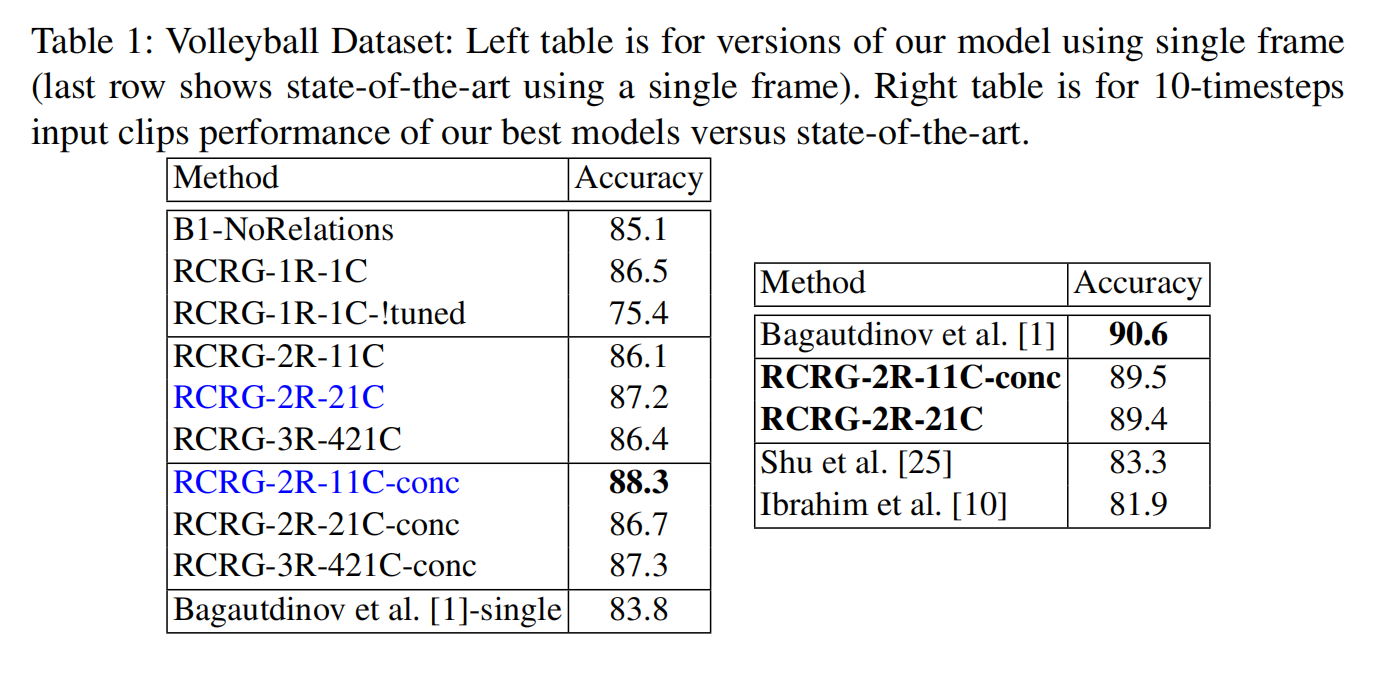
经过比较,推理关系表示对于精度的提升有一定作用,但是因为没有时序方面的信息,所以模型并没有state-of-arts的精度高。
行为和场景检索消融实验
指标:IoU(判断两个帧的类别分布是否匹配)

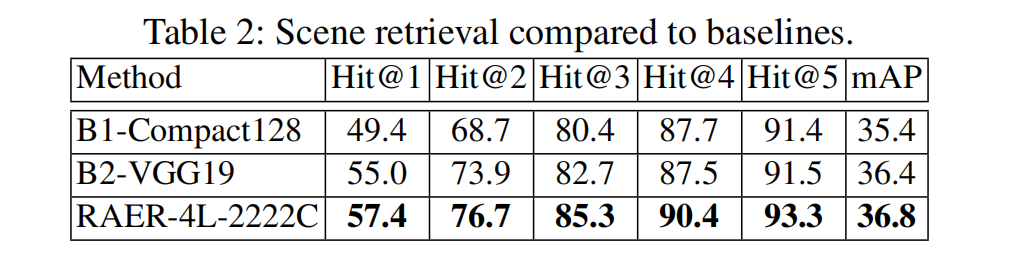
上表说明,relational或是context信息对于情景检索十分重要。
- Post title:论文阅读笔记:“Hierarchical Relational Networks for Group Activity Recognition and Retrieval”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_028/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.