论文阅读笔记:“A Closer Look at Spatiotemporal Convolutions for Action Recognition”

A Closer Look at Spatiotemporal Convolutions for Action Recognition
核心亮点
时空卷积 new form spatio-temporal convolution
- mixed convolution
3D卷积在网络的早些层,2D卷积在网络的后面的层
- (2+1)D 卷积块
与P3D类似,这篇文章也是将3D卷积分解为一个2D空间卷积和一个1D时间卷积。这样做的潜在好处为:
- 减少了参数量,更容易训练和优化
- 激活函数增加了一倍,网络更容易表示复杂的函数
与P3D的区别
R(2+1)D只使用了单一类型的块,并且并不包含瓶颈设计,但是通过对(分解)维度的仔细选择(P3D只说了分解,但没说怎么对维度分解),它较P3D 的精度提高了9.1%,并且相较于152层的P3D,R(2+1)D只有34层。
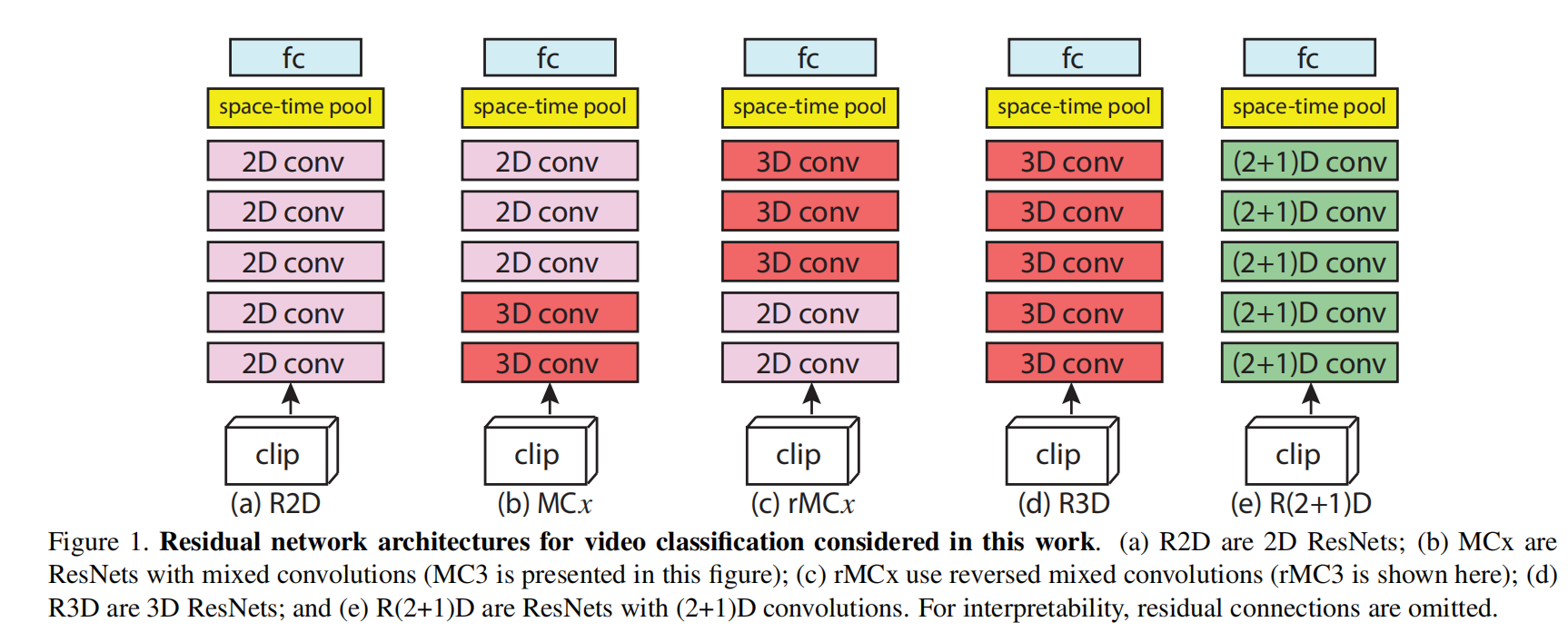
R(2+1)D卷积块
它将
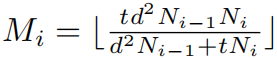
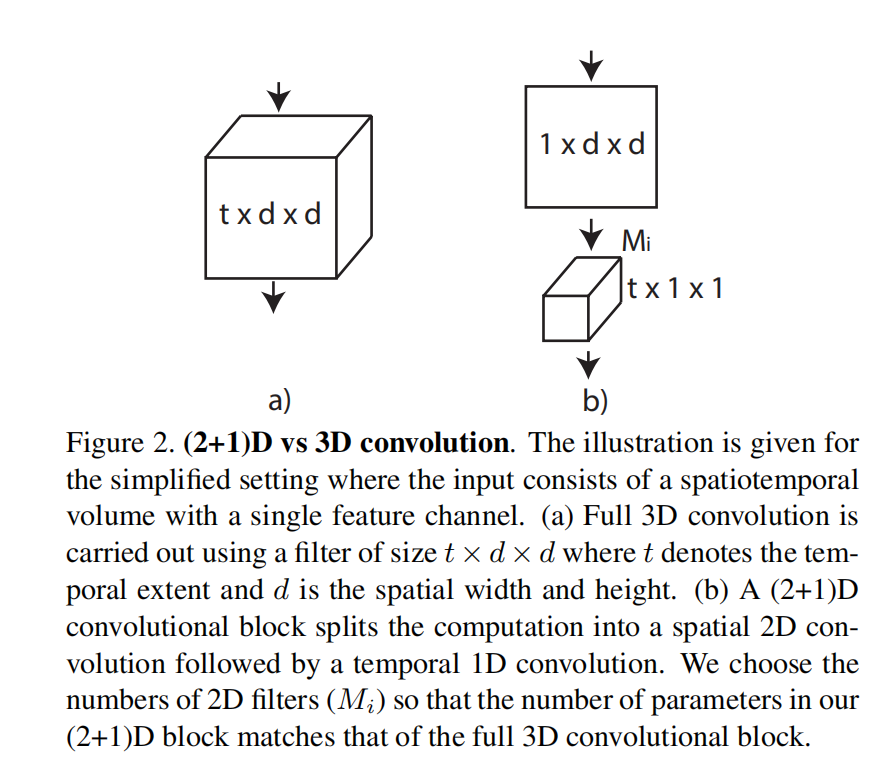
这样设计之后,参数数量是基本一致的,分解的过程如下图:
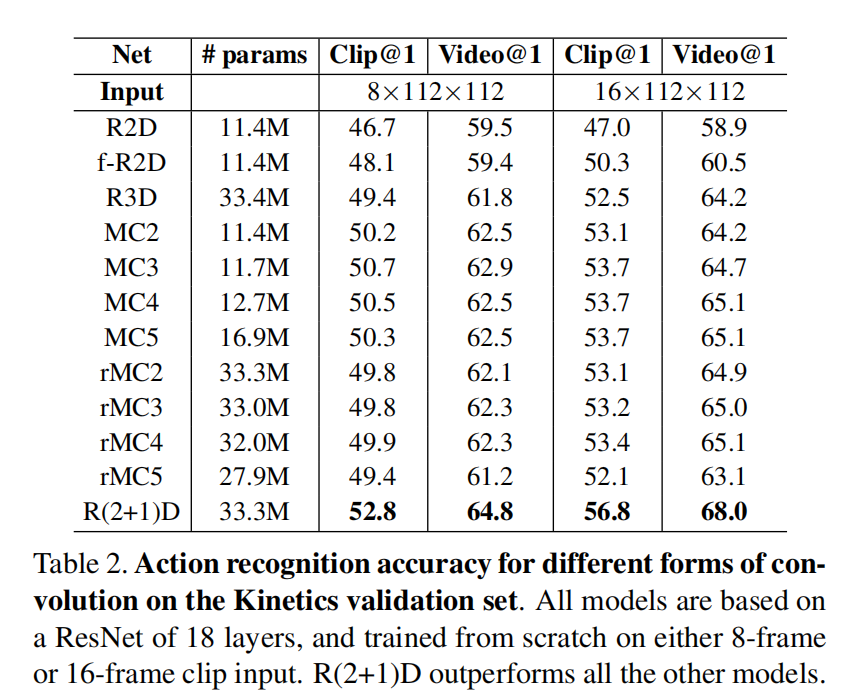
实验结果
对比多个不同的网络架构
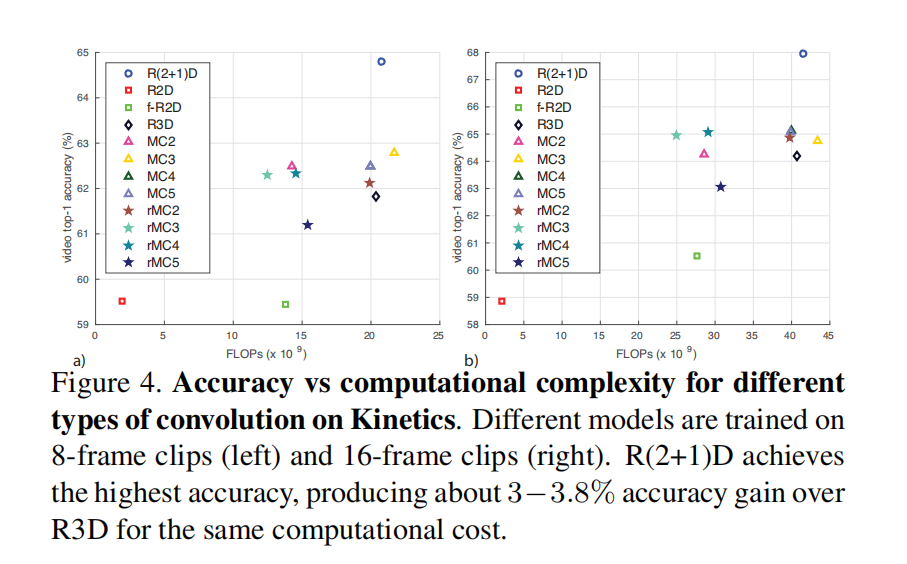
精度与模型复杂度的关系
精度与输入帧数的关系
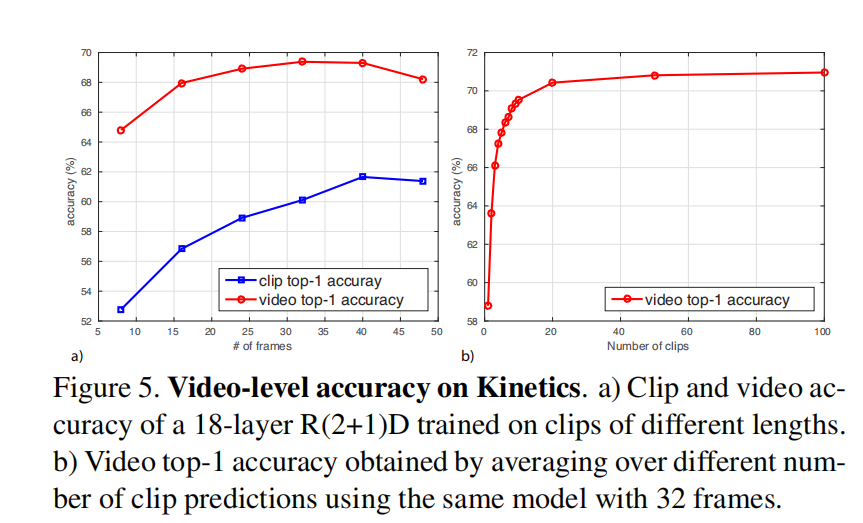
既然明确了精度和输入帧数之间存在trade-off,我们应该如何对其进行权衡呢?
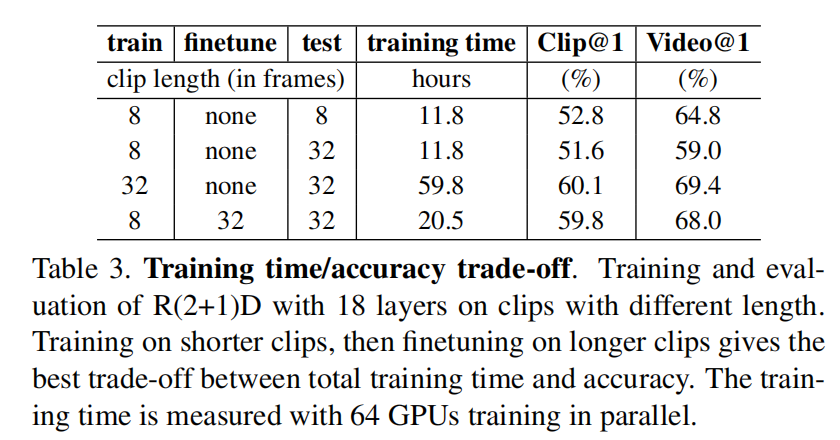
论文发现,在较短输入进行训练,再在较长帧上进行finetune会比较好。
使用64个gpu,真的说明目前的网络真的不好训练,并且还有值得优化的空间
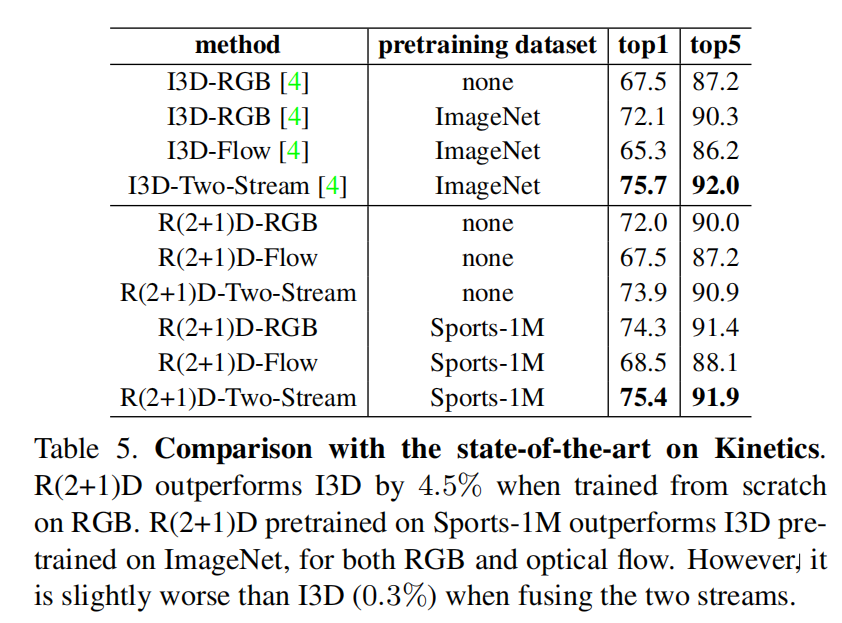
与state-of-arts的比较
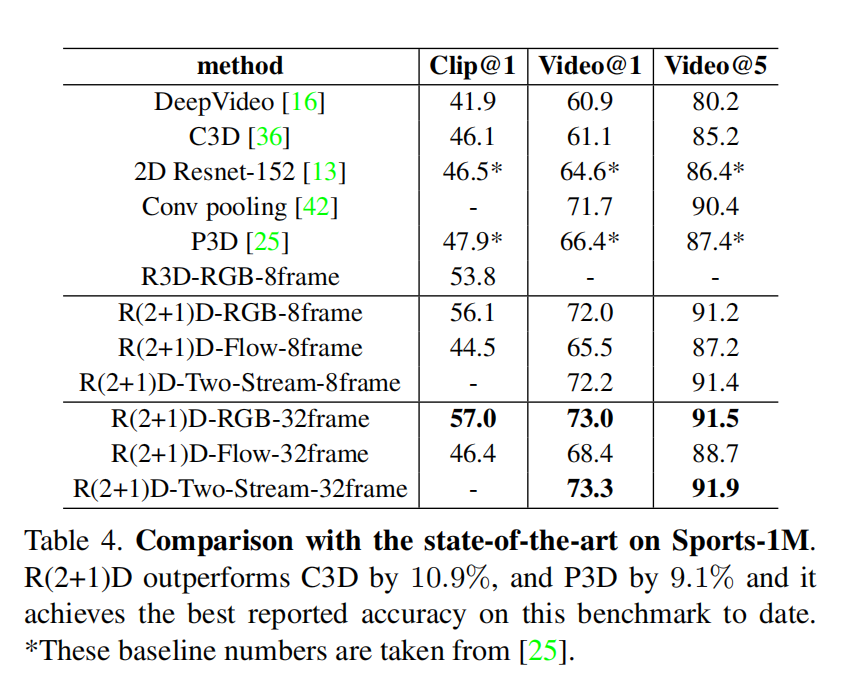
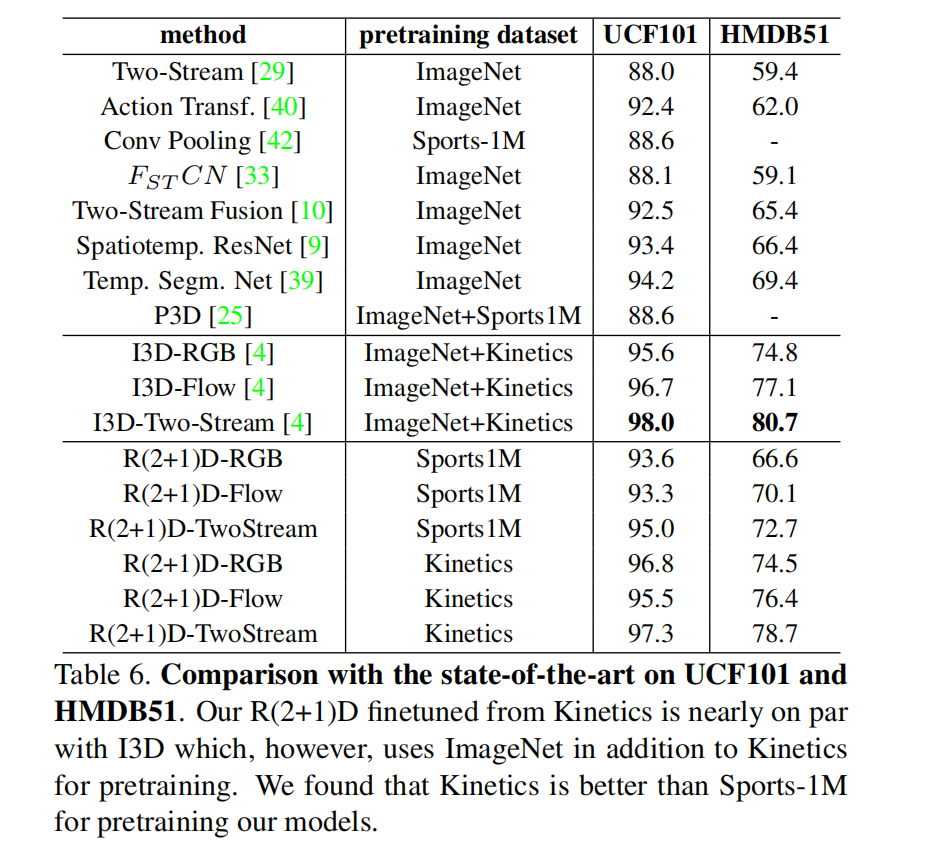
迁移学习
- Post title:论文阅读笔记:“A Closer Look at Spatiotemporal Convolutions for Action Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_031/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments