论文阅读笔记:“Attention Is All You Need”

Attention Is All You Need(2017)
阅读这篇文章的原因是之前读的两篇SE块和non-local块都使用到了自注意力机制,所以想通过这篇论文深入了解一些其中的原理,并与之前读的两篇进行比较和总结。
核心亮点
Scaled Dot-Product Attention 缩放点乘注意力
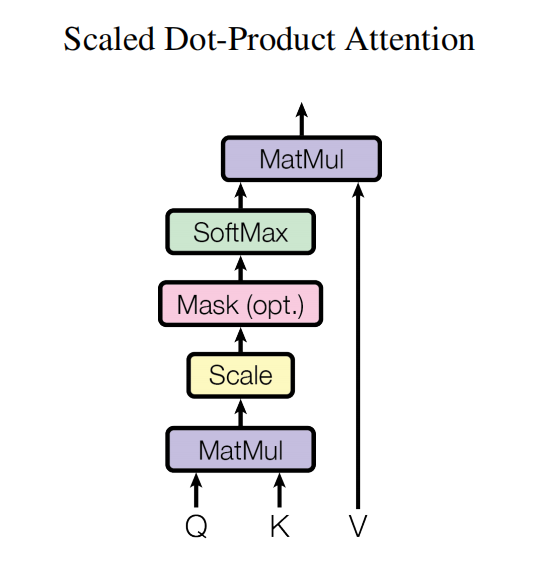
如图为注意力的流程模块图,形式化表达如下:
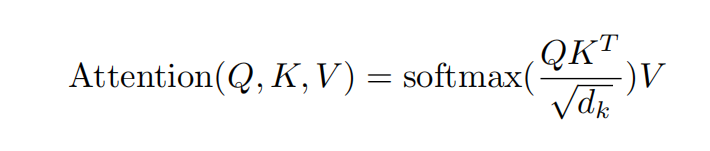
从图和公式可以看出,Q与K首先做了一个矩阵乘法,如果说两个位置的距离越接近,所得到的点积结果也会越大,所以这个
与SE模块的联系
这个思想与SE模块有着异曲同工之妙。SE模块是利用重标定的通道全局信息来对特征进行优化。上面的注意力形式正是利用全局信息的有效范例。
与non-local块的联系
从最终的主要形式上讲,non-local块和上面的attention机制就是同一个东西,只不过,non-local块对缩放点乘注意力进行了扩展,使之适用于任何大小,维数的输入。另外non-local块还增加了残差链接。
多头注意力
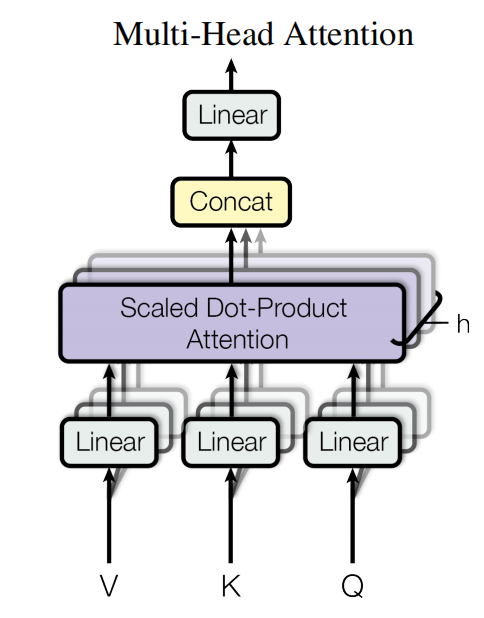
形式化描述如下:

使用多头注意力可以是模型注意到不同表示子空间不同位置的信息。其中concat是沿特征维度进行的,concat之后与W进行的矩阵乘法实际上是对不同head的信息进行聚合aggregate
网络结构
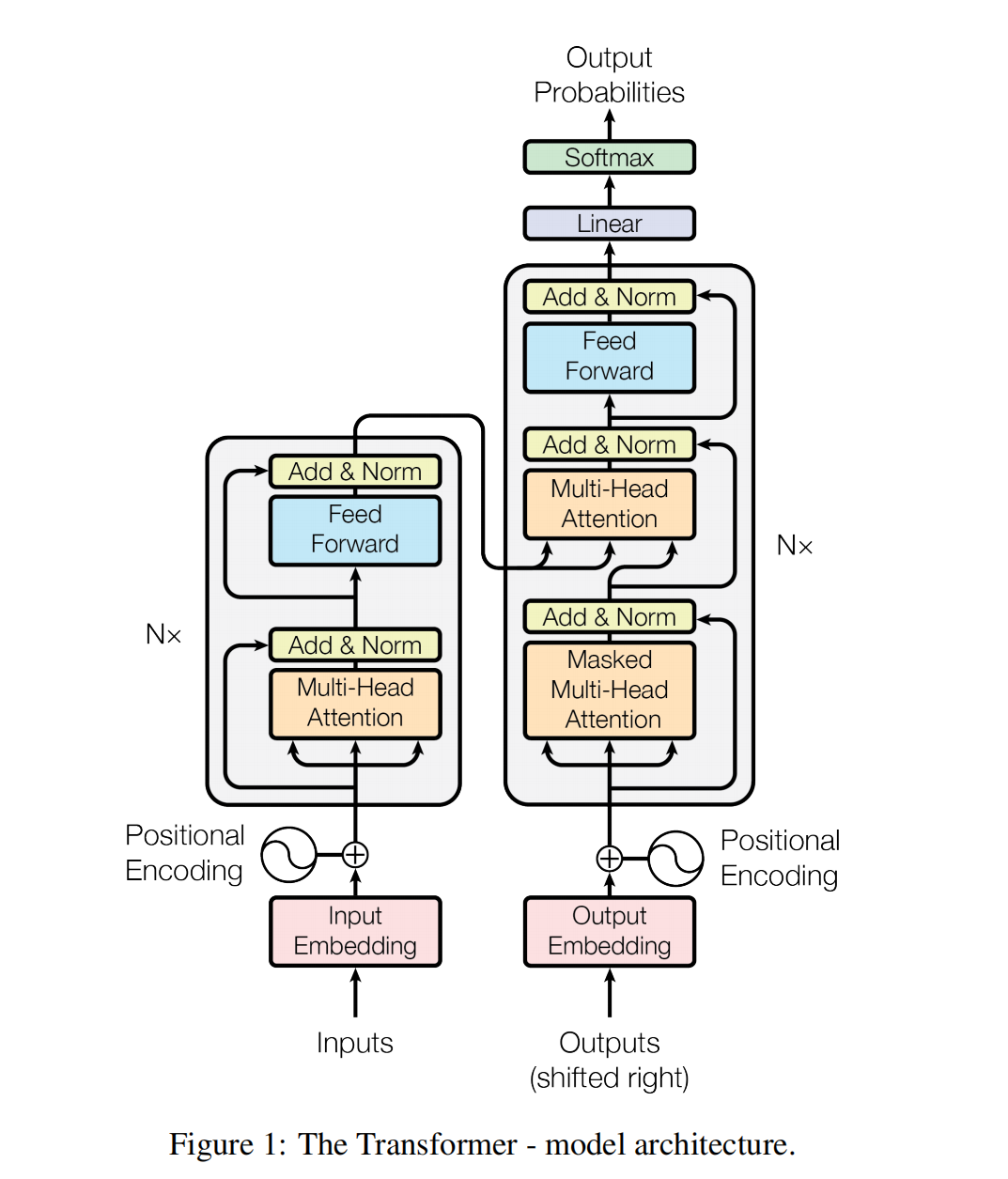
注意,解码器有两个attention层,第一个是进行自注意力的计算,需要mask未来信息;第二个attention层利用input的输出对output的特征进行优化。
- Post title:论文阅读笔记:“Attention Is All You Need”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_033/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments