论文阅读笔记:“Actor-Transformers for Group Activity Recognition”

Actor-Transformers for Group Activity Recognition(cvpr2020)
核心亮点
静态+动态特征表示
对于细化的行为类别,我们需要捕捉关节点的位置信息,以及他们的时序动态信息。因此作者使用了姿态估计模型HRNet来对关键关节点的位置进行预测,使用3D CNN来构建时空特征表示,这两个网络模型分别为静态分支和动态分支。对于动态分支,作者使用了RGB和光流这两种相互补充的输入。
自注意力机制
论文将transformer引入群体行为识别,从而无须进行显示的空间和时间建模。作者还研究了,将静态和动态角色相关的特征表示传入tranformer后,如何对得到的相互补充的特征进行有效融合。

网络结构
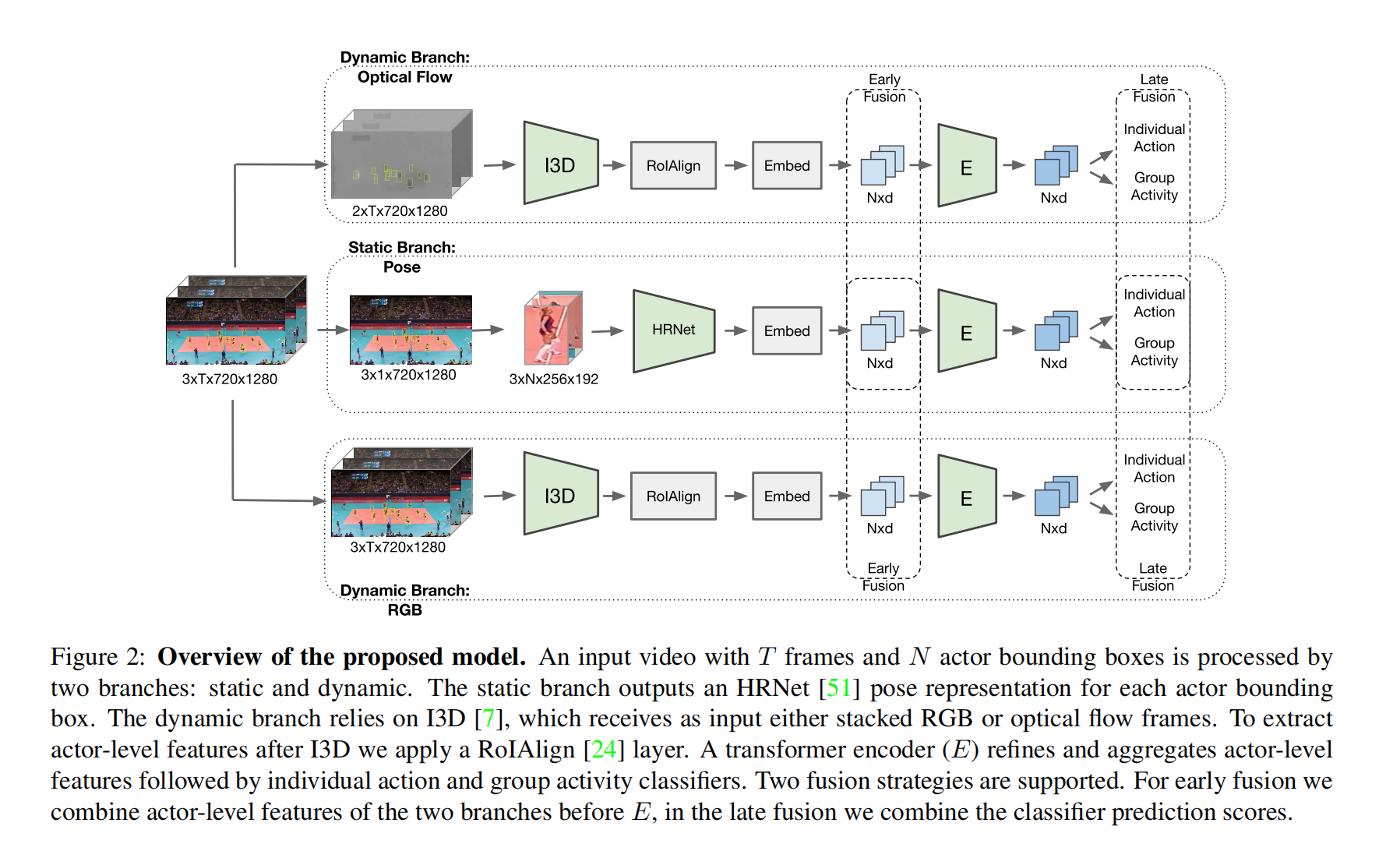
如上图,整个网络包含了3个阶段,第一个阶段是角色特征提取,经过特征提取网络以及embedding之后,得到的是每个角色的一维嵌入;在第二个阶段,使用transformer网络来对学习角色之间的关系,并选择性地提取对行为识别重要的信息;在最后一个阶段,作者分别在transformer之前和之后引入融合策略,来研究融合不同表示信息的有效性。
实验结果
融合策略
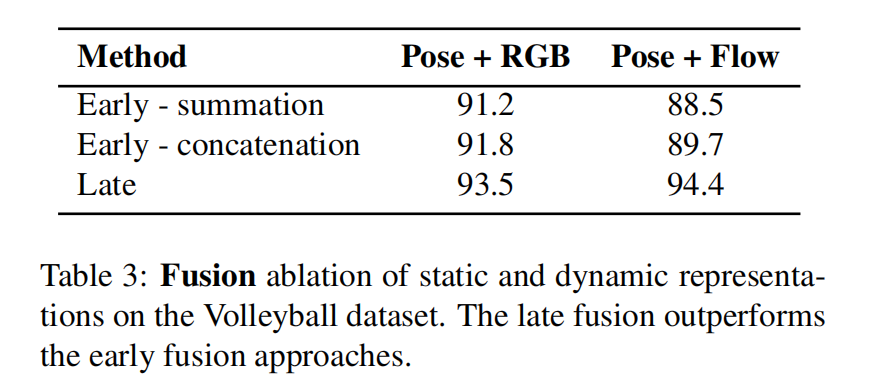
由图,令transformer网络专注于静态或动态特征再融合会有比较高的精度。
state-of-arts
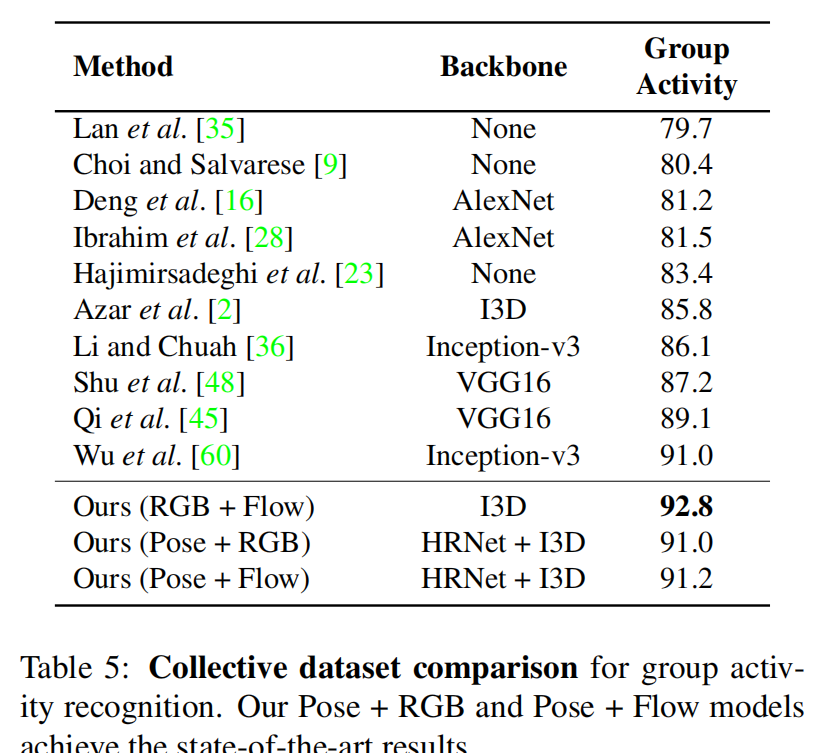
比较有意思的是,对于volleyball数据集,Pose+光流的组合远高于其他与rgb的组合,而对于collective数据集结果证明RGB+光流远好于其他与Pose的组合
- Post title:论文阅读笔记:“Actor-Transformers for Group Activity Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_037/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments