
Dual-AI: Dual-path Actor Interaction Learning for Group Activity Recognition(cvpr 2022)
引言分析
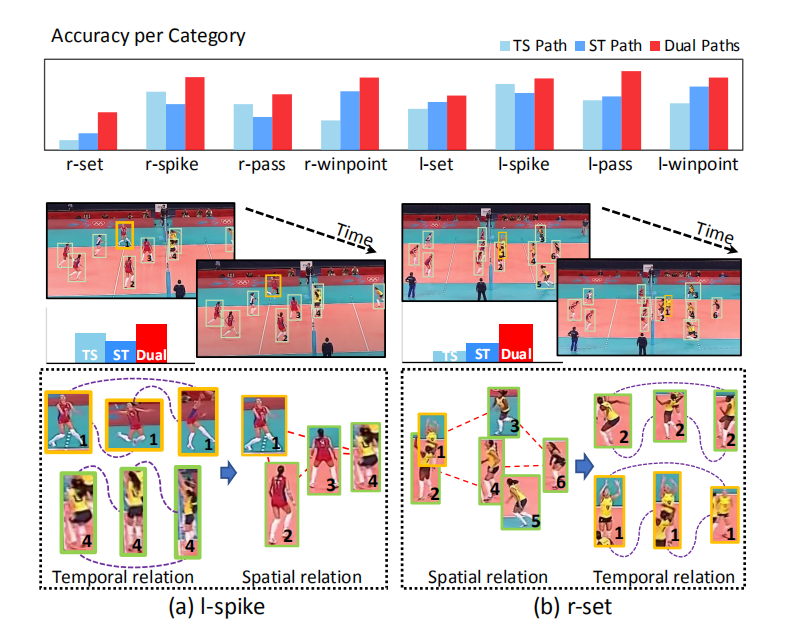
通常对于联合的空间和时序信息信息进行优化比较困难,因此目前GAR的方法往往对时空注意力进行解耦。如图所示,这篇文章提出解耦的顺序对于不同的分类类别影响较大。基于这个发现,作者针对GAR提出了独特的双路角色交互框架,它可以有效地对两种互补的时空观点进行集成,从而能够学习视频中复杂的角色关联。此外作者提出了一个创新的损失函数:MAC-Loss(多尺度角色对比损失)。它可以提供一个简洁但有效的自监督信号,以增强两个通路之间的角色一致性。
核心亮点
Dual-AI框架
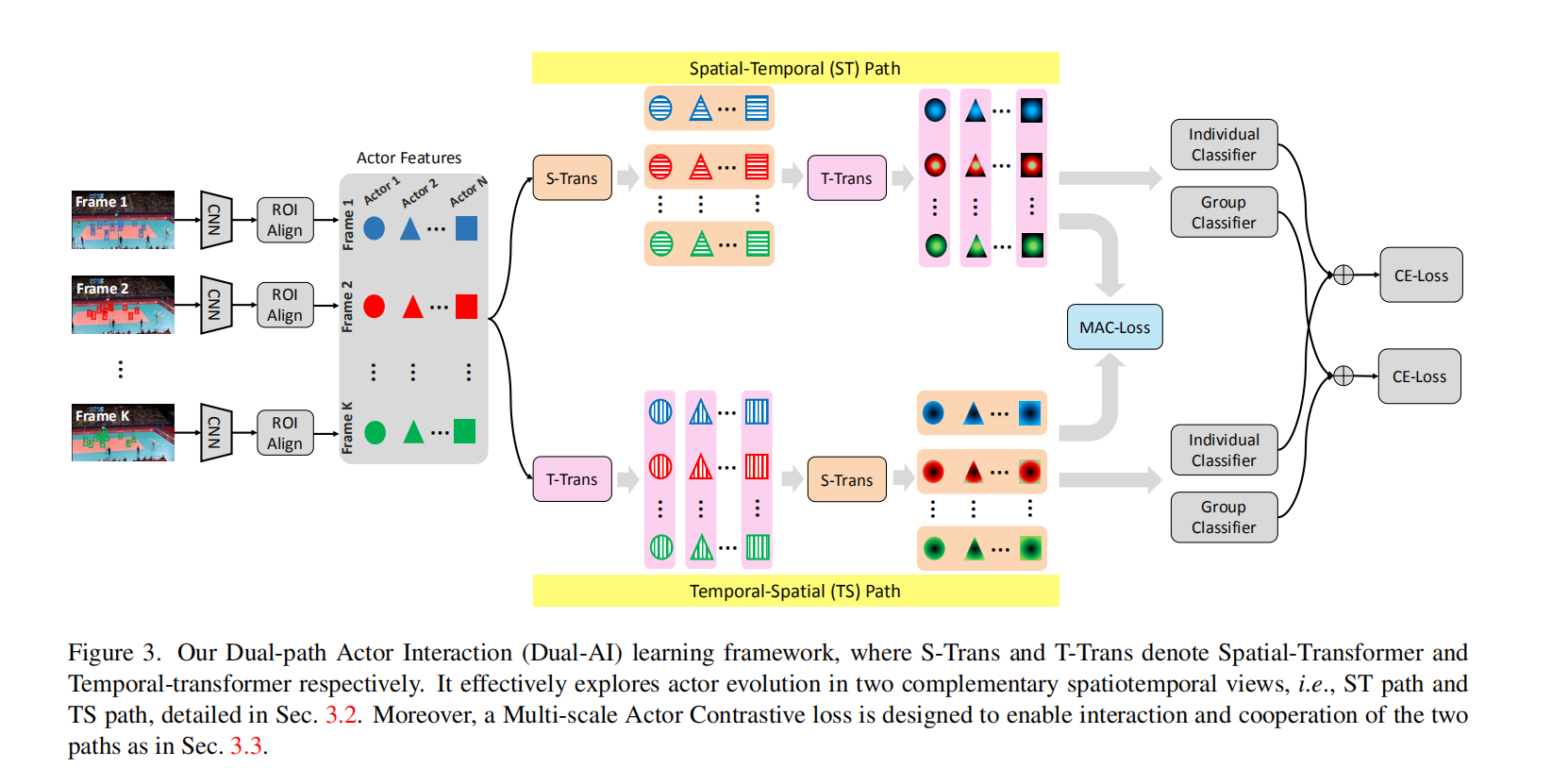
Dual-AI包含了时间空间交互通路(TS)和空间时间交互通路(ST)。其中的基本单元(spatial actor transformer & temporal actor transformer)可以用来描述空间和时间联系。
- spatial actor transformer
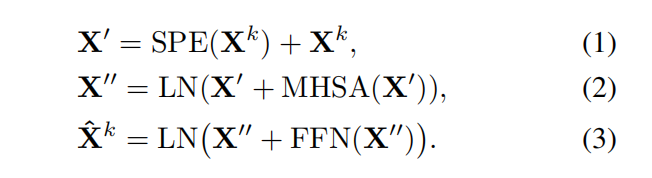
第一个式子加入了空间位置编码,以加入场景中角色的空间结构信息。第二个式子使用了多头自注意力机制(MHSA)来对场景中的角色位置信息的交互进行推理。第三个式子加入了前馈网络来进一步增加计算单元的学习能力。
- temporal actor transformer
与空间不同,时间trans的输入是
有了这些基本单元,我们就可以用他们来构造角色演变的时空表示,构造方法如下:
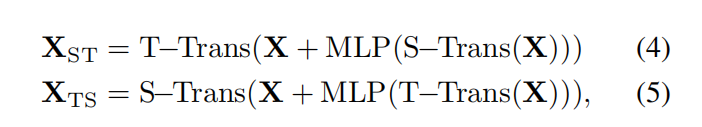
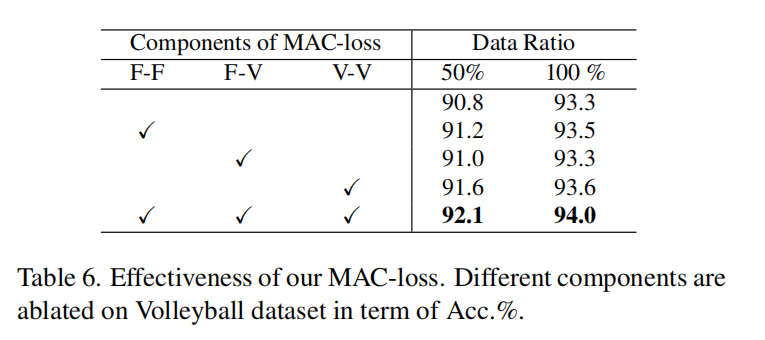
MAC-Loss
MAC-Loss可以通过帧-帧、帧-视频、视频-视频三个级别的角色一致性来有效增强特征辨别能力。它可以将两个相对独立的通路之间的合作进行增强
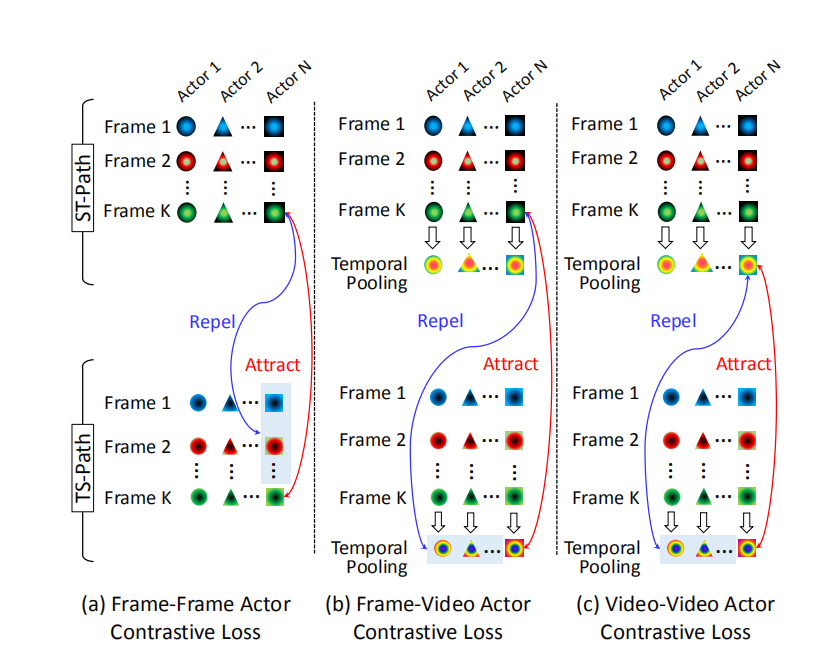
- 帧-帧角色对比损失
对于一个通路上的帧表示,它应该与另一条通路上的帧表示相类似,但是与那条通路上的其他帧表示相区别。
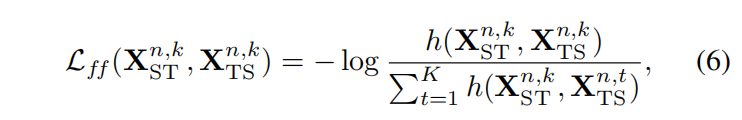
- 帧-视频角色对比损失
对于一个通路上的帧表示,它应该与另一个通路上的对应角色的视频表示相一致,与那条通路上其他角色视频表示相区别
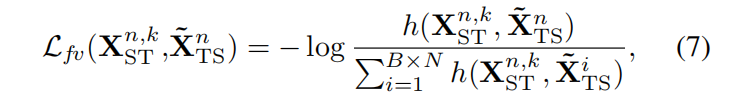
- 视频-视频角色对比损失:
- 最终的MAC-Loss为:
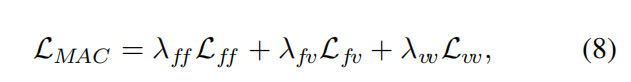
训练目标:
该框架可以端到端地对个体行为和组行为进行预测,通过结合交叉熵损失,最终的分类损失为:
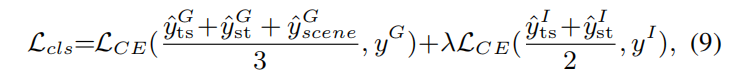
最终作者结合所有的损失来训练他们的Dual-AI框架:
实验结果
SOTA对比
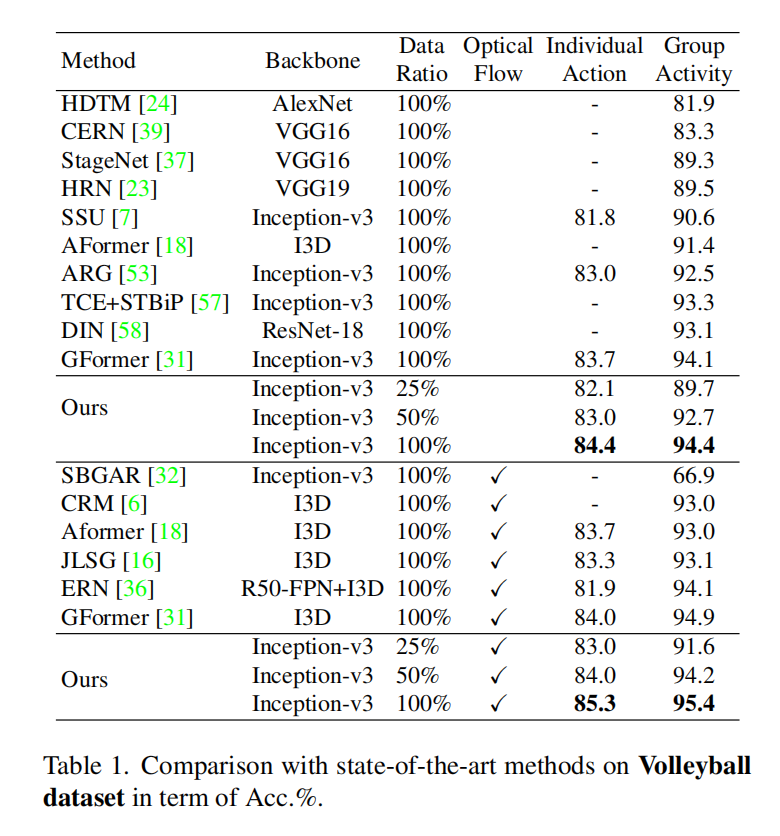
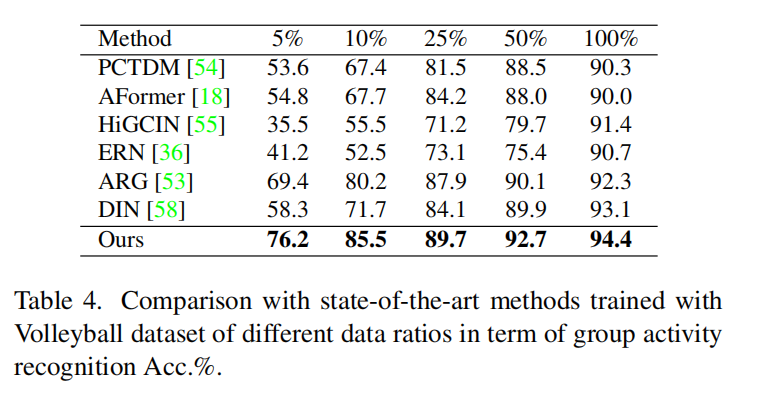
- volleyball数据集
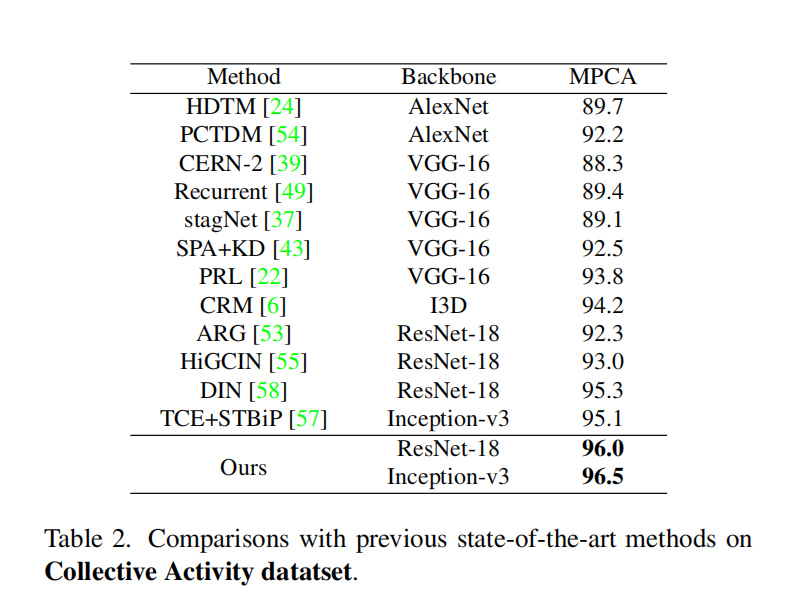
- collective数据集
弱监督场景
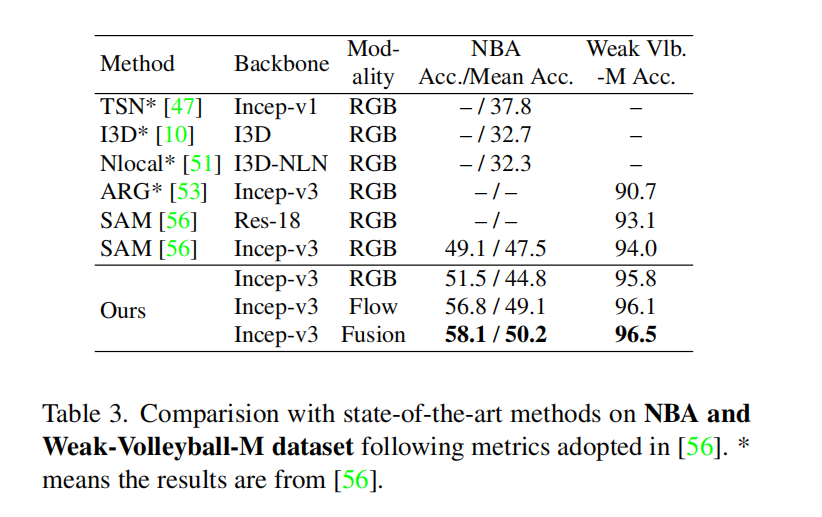
少样本场景
消融实验
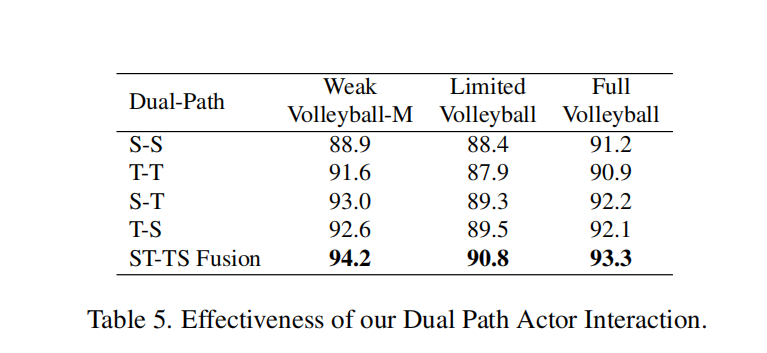
- 双通路设置
- MAC-Loss
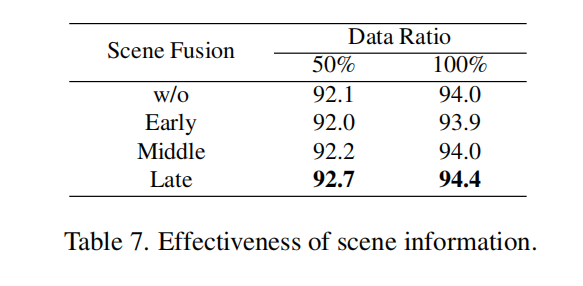
- 场景信息
可视化
- 组特征可视化
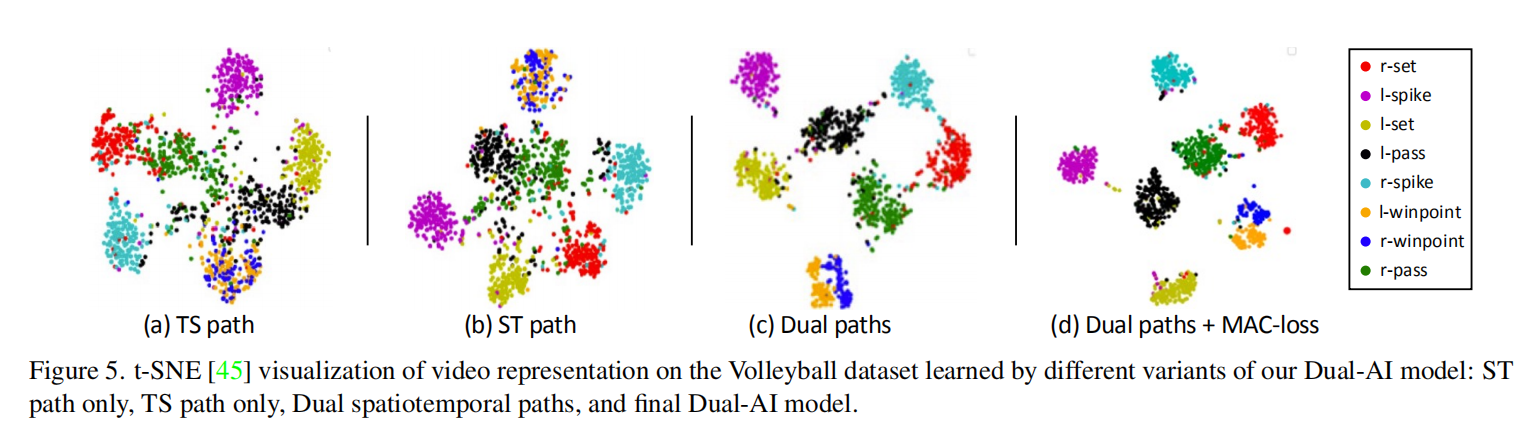
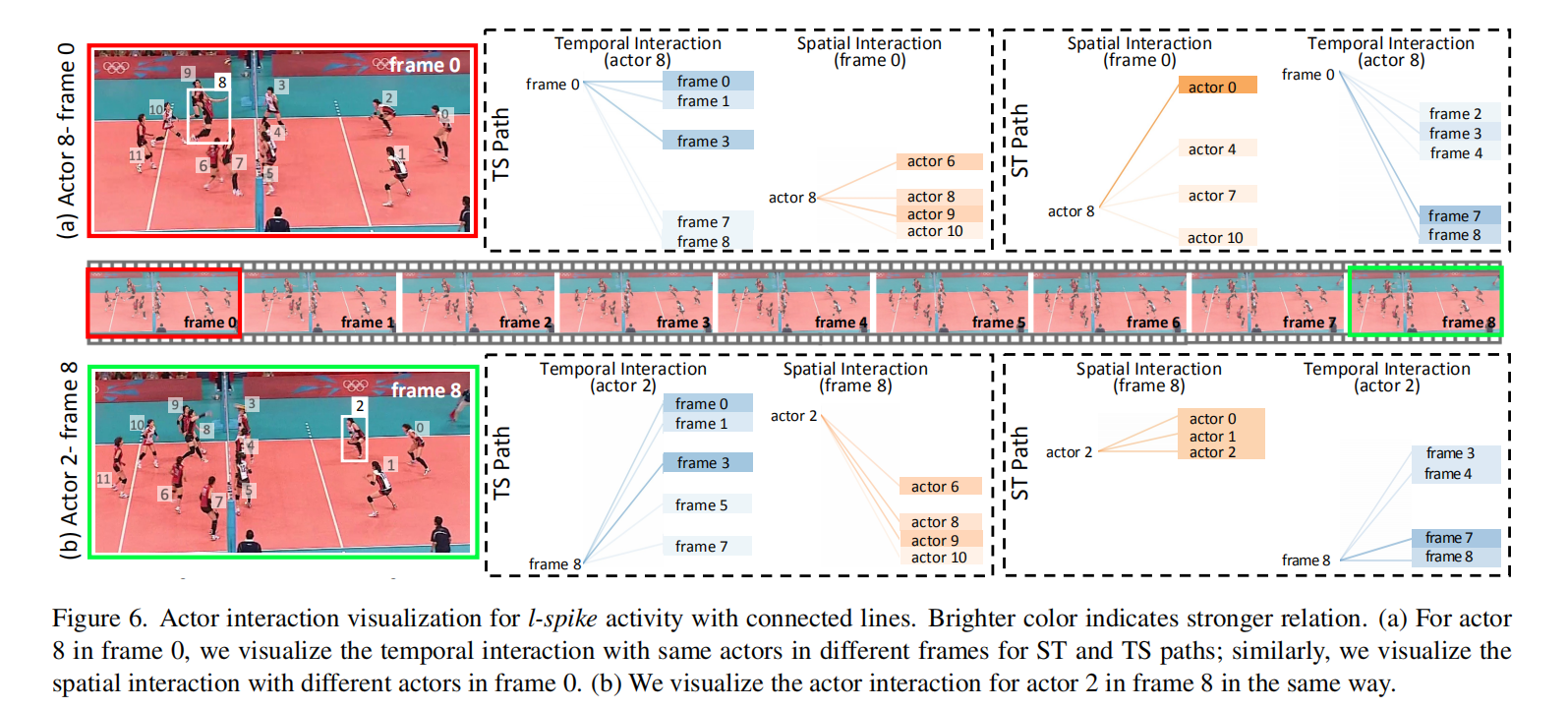
- 时空角色注意力可视化
- Post title:论文阅读笔记:“Dual-AI: Dual-path Actor Interaction Learning for Group Activity Recognition”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_038/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.