论文阅读笔记:“Detecting events and key actors in multi-person videos”

Detecting events and key actors in multi-person videos(2016)
这篇论文算是该领域开创性的一篇论文
引言分析
组行为识别问题,往往只涉及一些关键角色,他们主导或决定了整个行为事件。但是确定哪些角色对于该事件较为重要,这种标注首先很昂贵,并且往往设计不需要这种具体标注的模型。所以该论文提出了一个新的视角,即对关键角色行为识别的一个弱监督问题。该论文进一步在群体行为识别中应用了注意力机制
核心亮点
NCAA Basketball Dataset

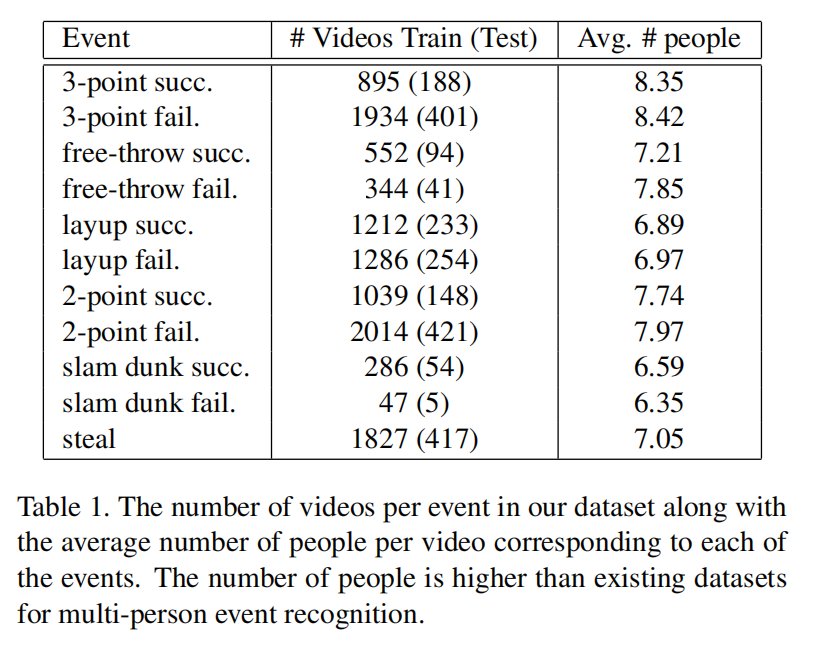
事件检测
每个视频帧都可以表示为1024维的特征向量ft,对于帧中的每一个角色都可以计算2805维的特征向量
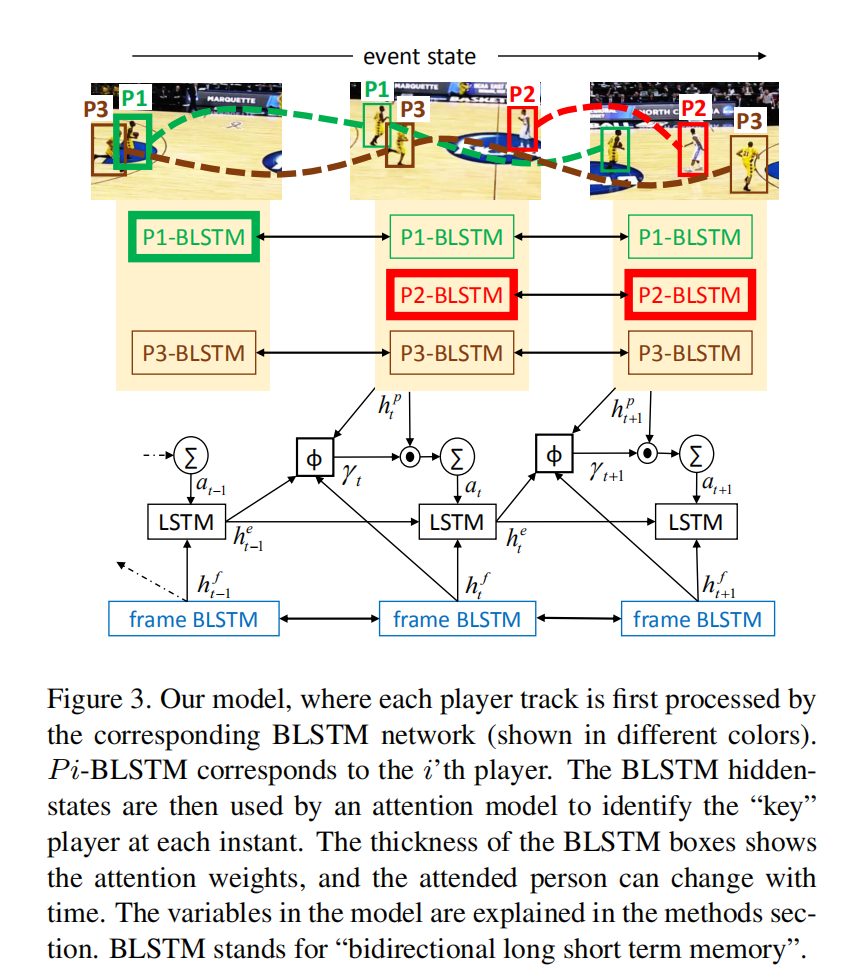
首先可以计算每帧的全局场景特征
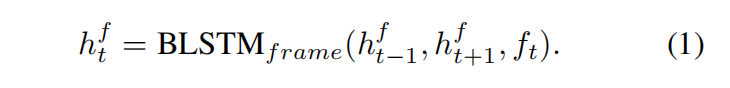
然后使用单向LSTM来表示某事件在时刻t时的状态
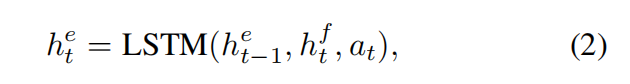
之后,我们就可以使用
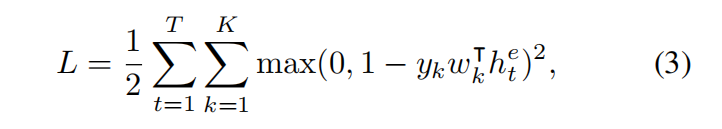
其实就是针对所有帧的每个类别的损失求和,如果视频属于第k类,那么yk=1,否则为-1。
注意力模型
我们需要让模型关注每个时间步不同的特征子集。在这个情境下,有两个关键问题需要解决:
- 使用目标跟踪算法来将不同帧的检测结果相连接,这样可以得到个体特征更好的表示
- 角色注意力取决于事件的状态,随着事件的变化需要跟着变化。
为了解决这些问题,作者提出了他们的模型(分为with tracking和tracking-free)
- Attention model with tracking
首先使用KLT tracker得到角色跟踪结果,之后使用单独的BLSTM得到特定时间步下每个角色的隐状态表示:
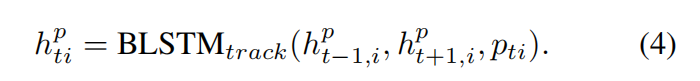
在每一个时间步里,我们希望选择最相关的角色。我们可以通过计算
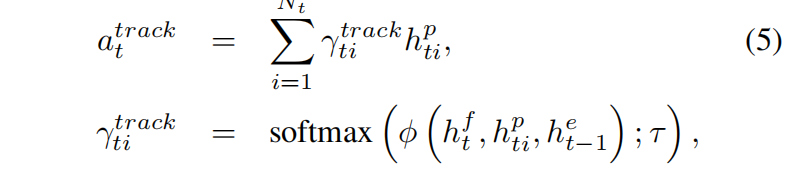
其中Nt为第t个帧所有检测的数量,我们得到的注意过的(attended)角色表示之后作为输入送入第二个式子的单向LSTM中进行处理。
- Attention model without tracking
有时,移动过快或是有遮挡时,使用tracking-free的模型会有比较有利。在这个无跟踪的场景下,我们假设每一帧的检测独立于其他帧:
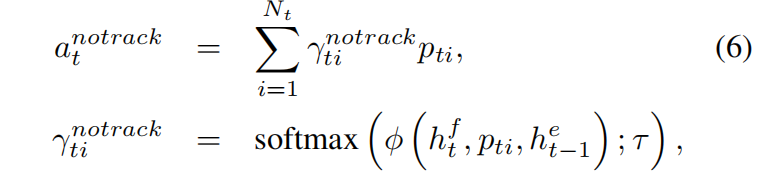
与上面的不同的是,它直接使用了player检测特征
实验结果
组行为分类
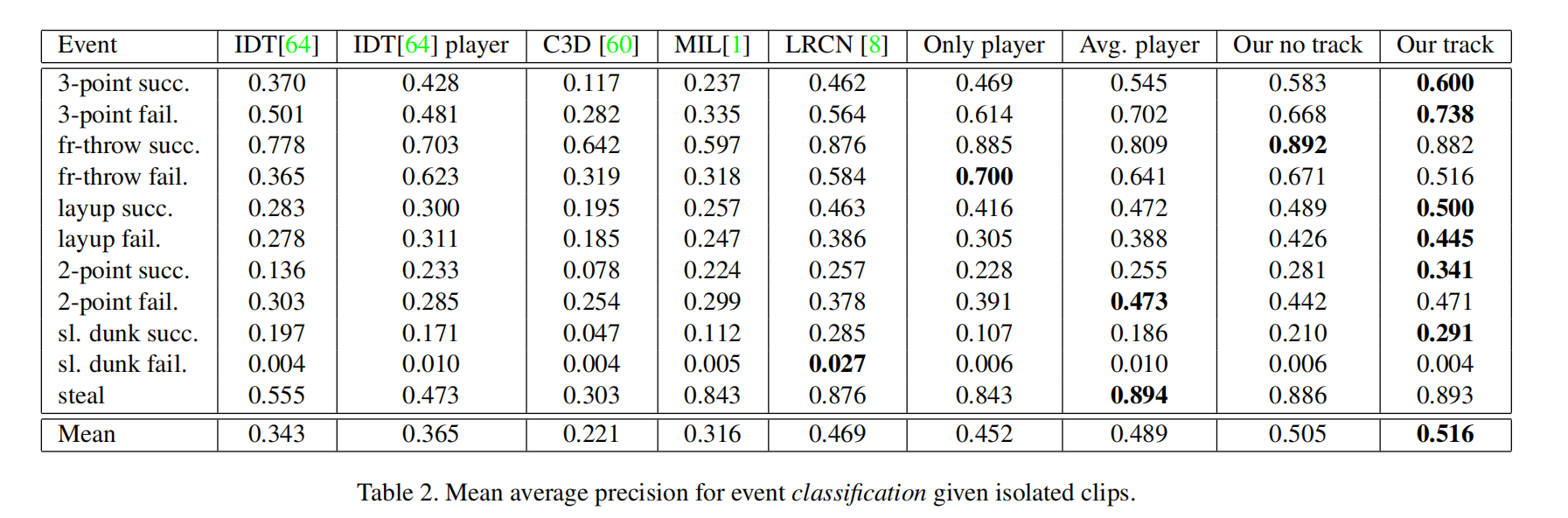
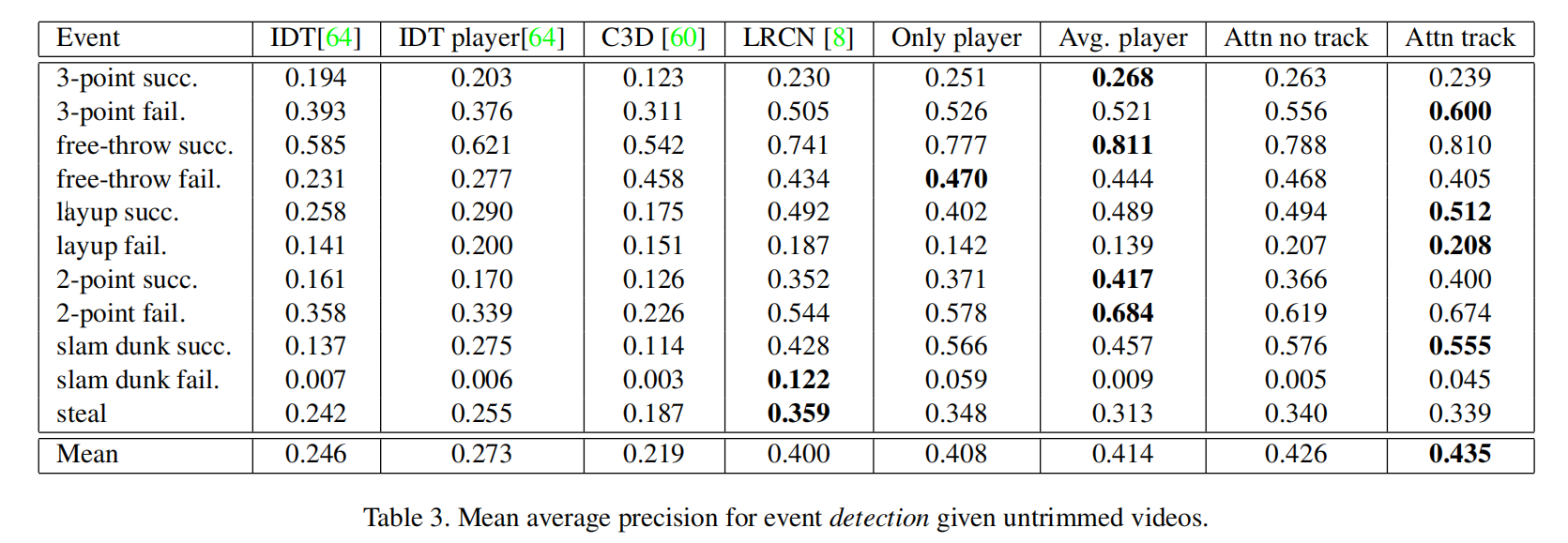
事件检测
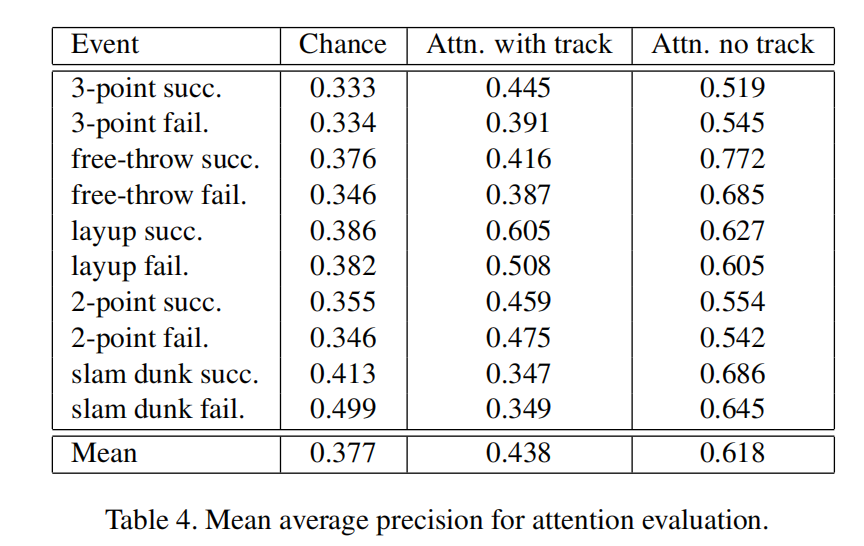
对于注意力进行评估
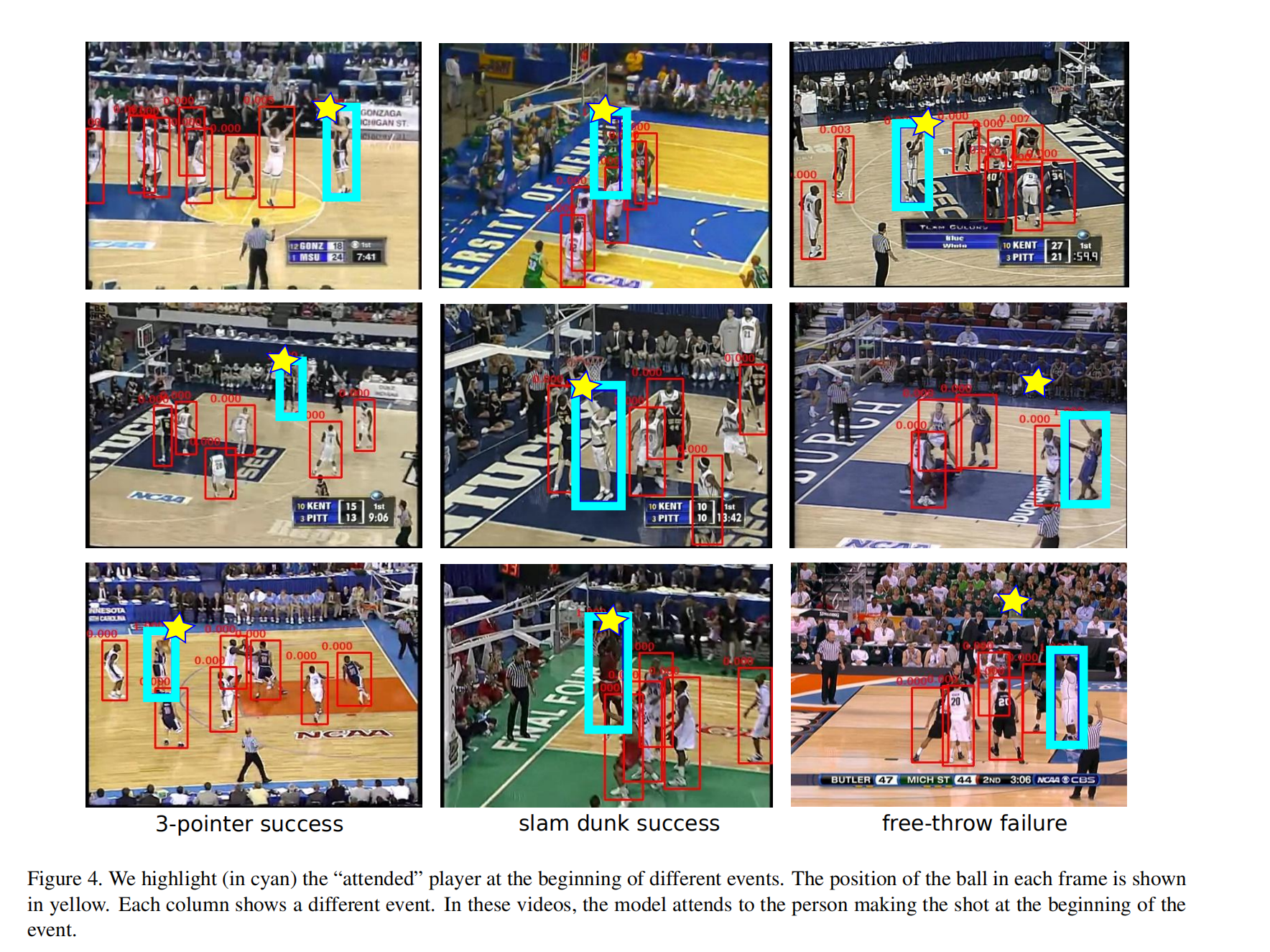
- Post title:论文阅读笔记:“Detecting events and key actors in multi-person videos”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_039/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments