论文阅读笔记:“ Spatial Transformer Networks”

Spatial Transformer Networks
引言分析
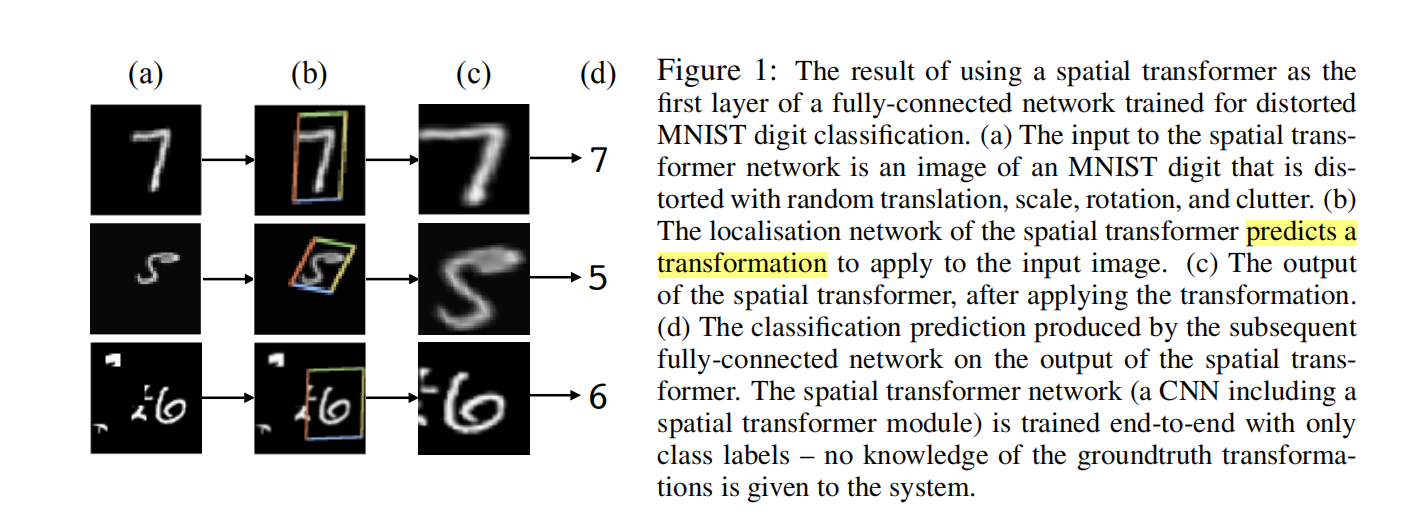
CNN不具备在网络的浅层或是中间层对于输入数据的空间不变性,论文提出了一种新的模块spatial transformer,该模块不仅会帮助我们选择图像中最相关的区域,同时还能将这些区域变换为经典的、预期的姿态来简化在后续层中的识别。如下图b所示,定位网络可以预测使用何种变换;c图是应用了变换后,transformer的输出。
核心亮点
空间变换网络 Spatial Transformer Network
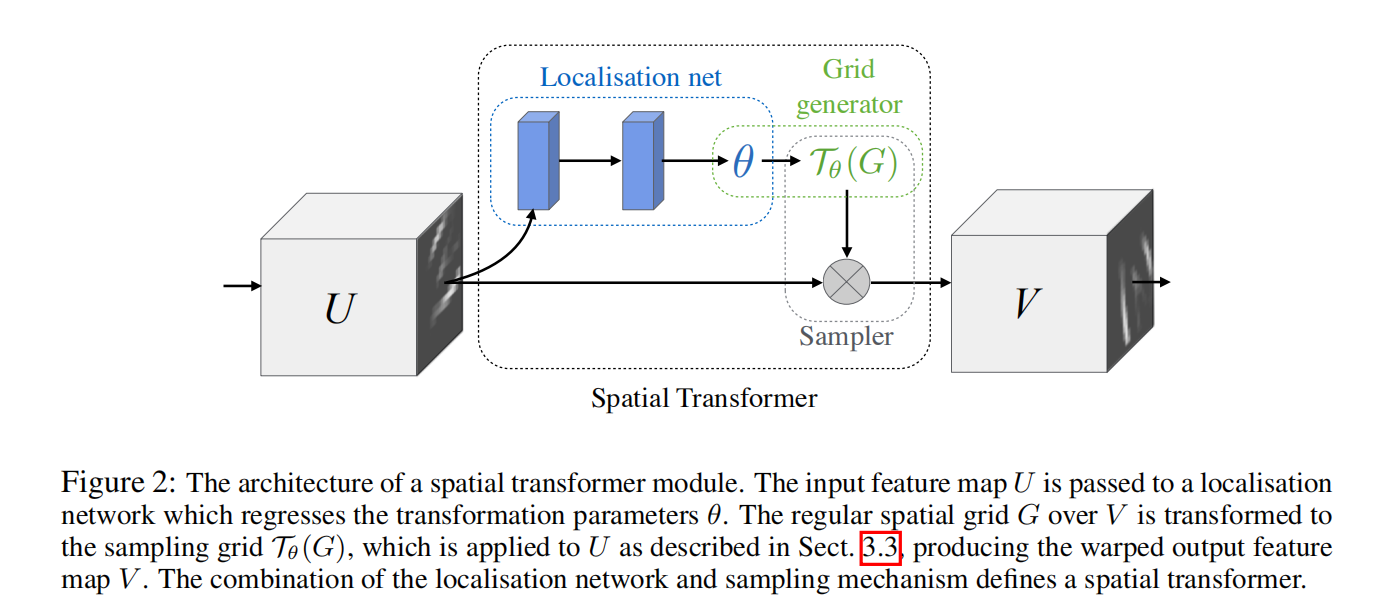
Spatial Transformer Network包含了三个组件:定位网络和参数化网格采样机制(网格生成器)和图像采样器。在CNN中加入该模块可以帮助最小化总体的网络花费函数。关于如何变换每个训练样本被压缩或缓存到了定位网络中的权重参数中。
定位网络 localization network
其输入是特征图U,输出是参数
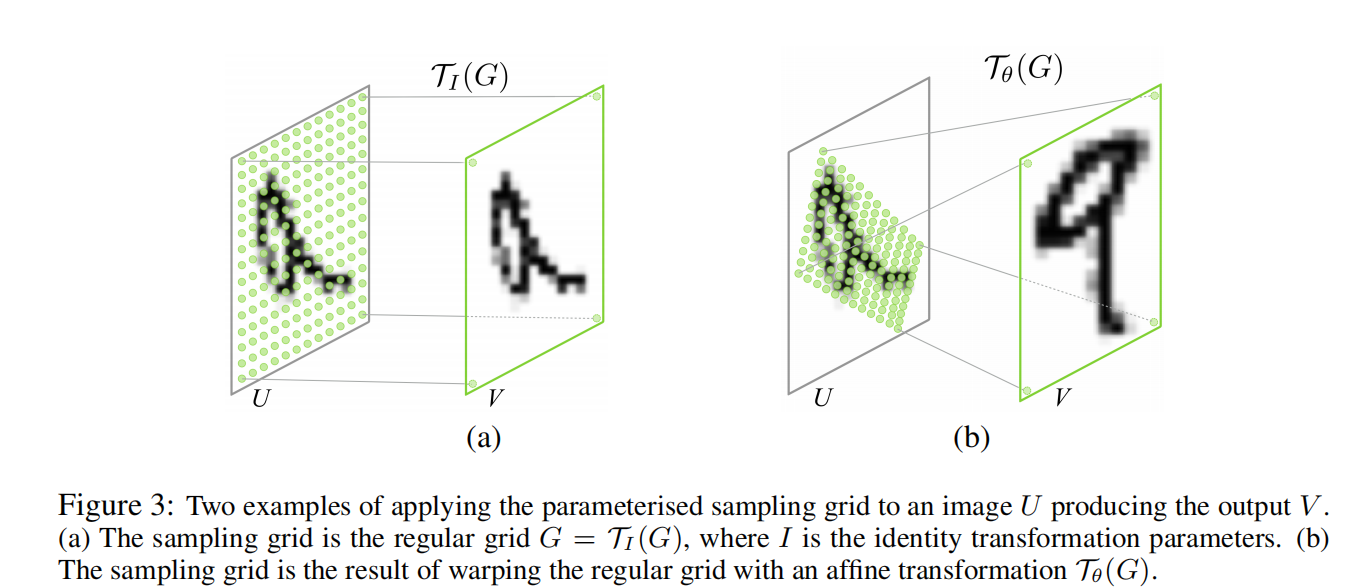
参数化采样网格(网格生成器)
 、
、
为了对输入特征图进行变形,每个输出像素都是由在输入特征图的特定位置应用一个采样kernel来计算的
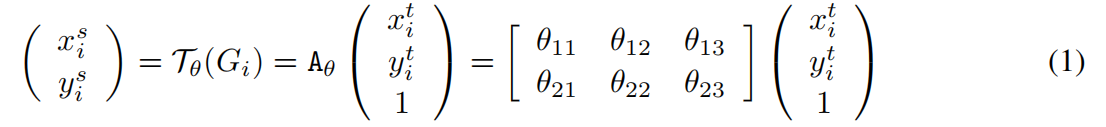
可微分图像采样
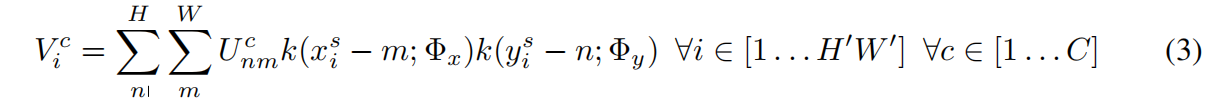
通过上式可以计算每个通道中每一位置的输出值。因为采样函数的不连续性,次梯度(sub-gradients)必须被使用。
实验设计
Distorted MNIST
探索网络可以学习到的多种变换
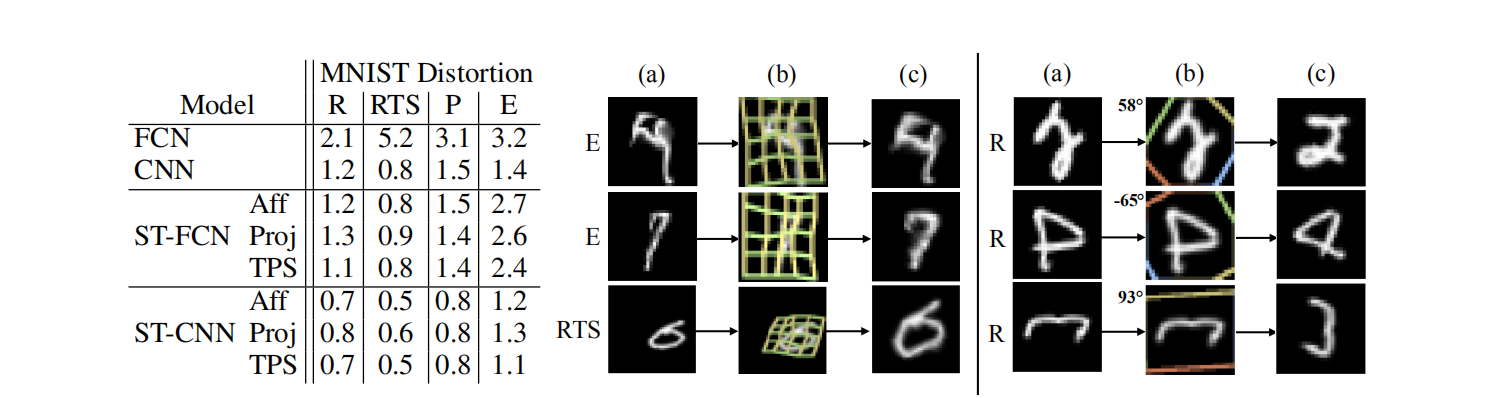
如图使用TPS变换+CNN+ST的效果最好
街景房号识别
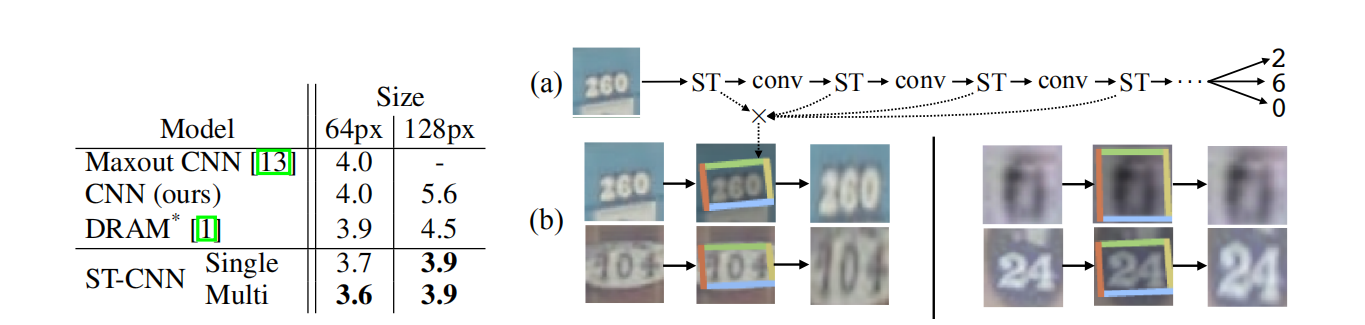
细粒度识别

由右图,不同的transformer识别不同的部位
- Post title:论文阅读笔记:“ Spatial Transformer Networks”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_042/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments