
VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text(nips 2021)
核心亮点
VATT整体框架
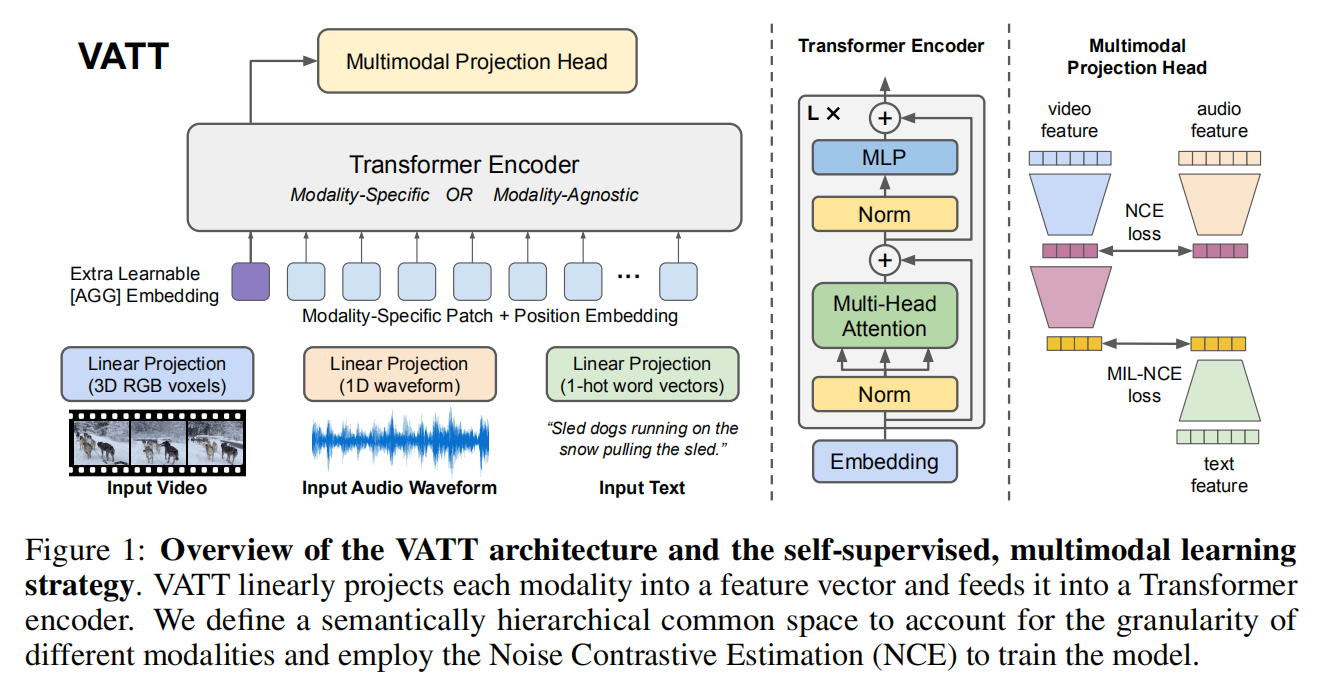
上图是VATT的整体架构,作者将每个模态输入到一个标记化层,在该层中原始输入被投影为一个嵌入向量,并在之后送入transformer中。作者使用了两种设置进行对比:
- 对于每种输入,其backbone都是分离的,权重不共享
- 使用单一骨干网络,共享不同模态的权重
网络提取模态特定的表示,并将它们映射到公共空间以通过对比损失相互比较
DropToken
因为transformer的计算复杂度是平方级别的,这个方法可以有效减少计算复杂度。我们得到标记序列后,随机采样其中的一部分,然后将采样后的序列送入transformer。对于可能包含冗余的数据,该方法可以大幅降低训练时间的同时保持很好的效果。
标记化及位置编码
作者将整个视频剪辑进行切分,每个patch的大小为
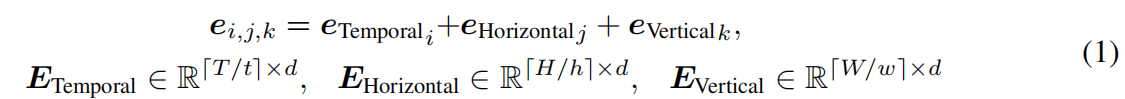
对于音频和文字的处理同理。transformer的输入如下:
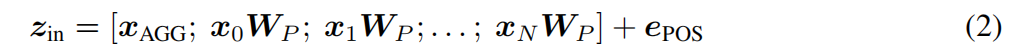
公共空间投影
给定视频-音频-文字三元组,作者定义了一个语义层次式公共空间映射,通过它我们可以利用余弦相似度来直接比较视频-音频对,视频-文字对。作者假设这些模态直接有不同级别的语义粒度,所有他定义了不同级别的投影:
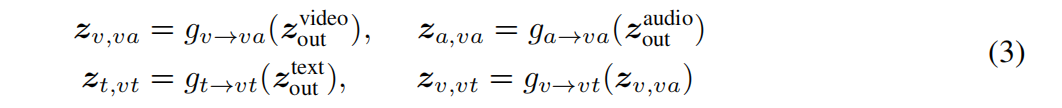
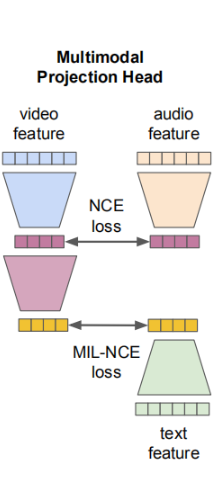
多模态对比学习
作者使用噪声对比估计(NCE)来对视频-音频对进行对齐,使用多实例学习NCE来对齐视频-文字对。正样本为采样视频中同一个位置的对应的模态信息流,负样本为视频中不匹配位置的采样样本。损失函数如下式所示:
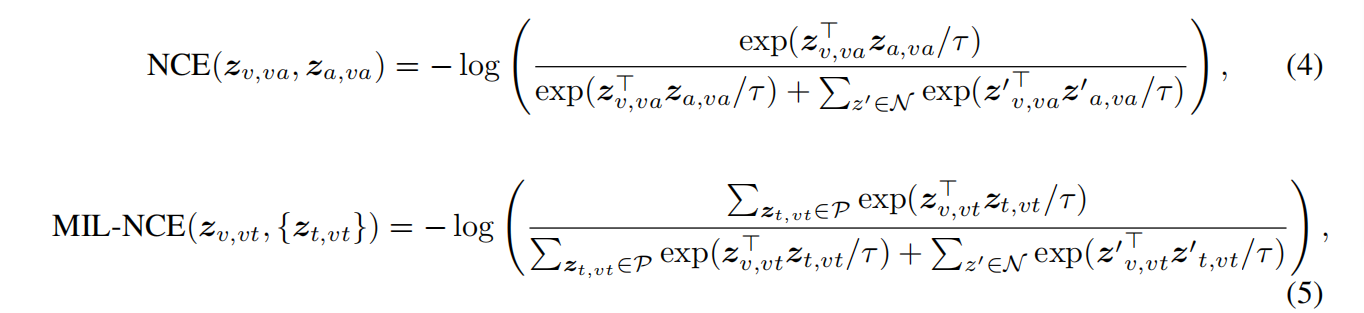
其中N中包含了所有的负样本。式5中,P包含了5个离视频剪辑时间上最近的文字剪辑。
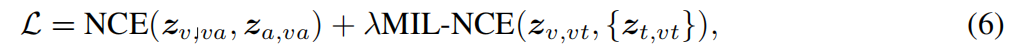
实验结果
action recognition
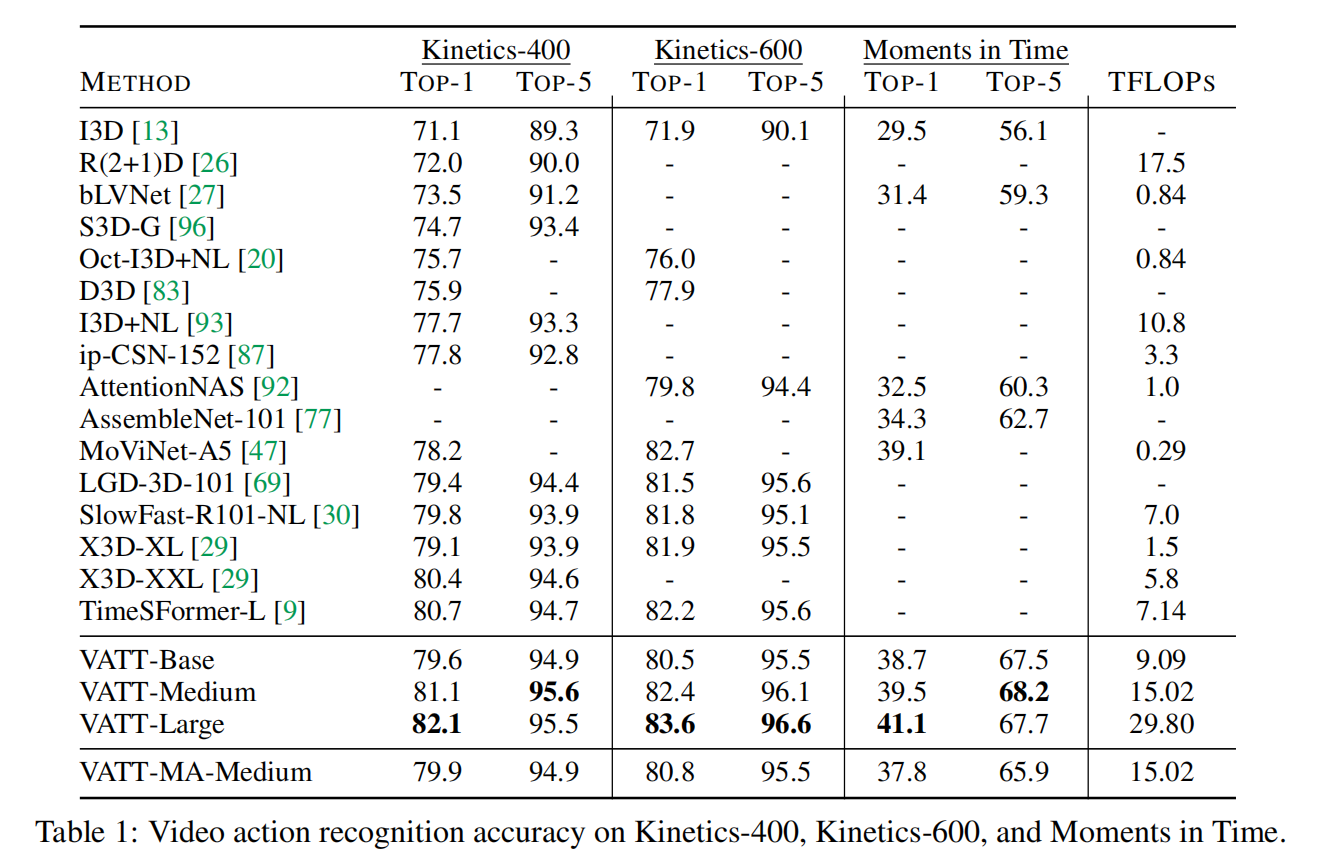
值得注意的是,如果从头开始训练(没有预训练),其精度会大幅下降
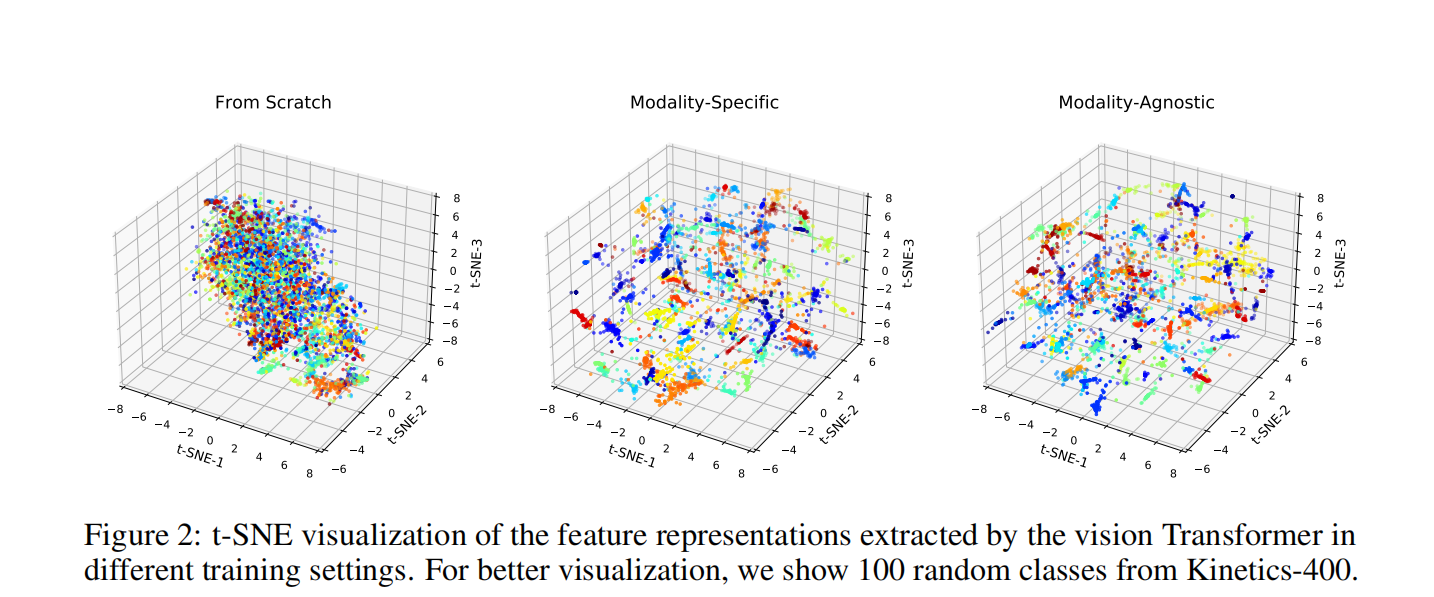
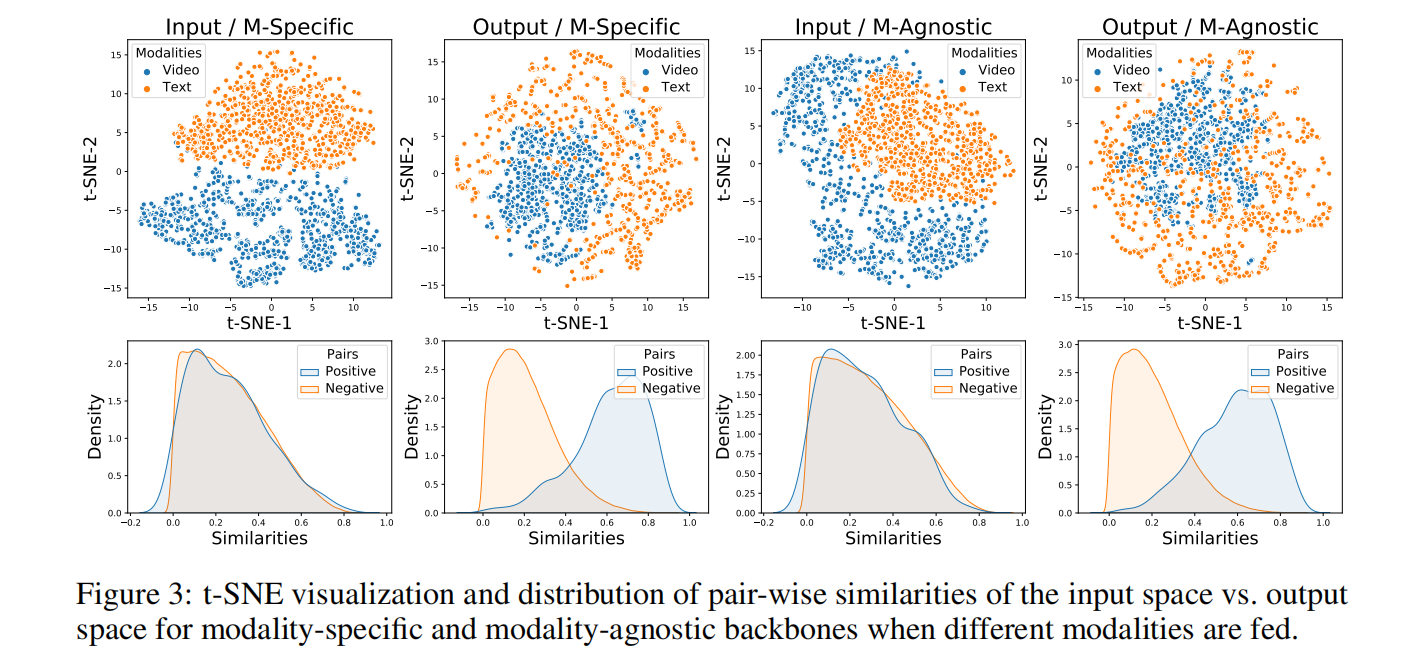
可视化
- Post title:论文阅读笔记:“VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_043/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.