论文阅读笔记:“COMPOSER:Compositional Reasoning of Group Activity in Videos with Keypoint-Only Modality”

COMPOSER: Compositional Reasoning of Group Activity in Videos with Keypoint-Only Modality
主要思想
将整个场景按照粒度的不同进行划分,形成了不同尺度大小的场景元素。这些不同尺度元素存在着组合关系。
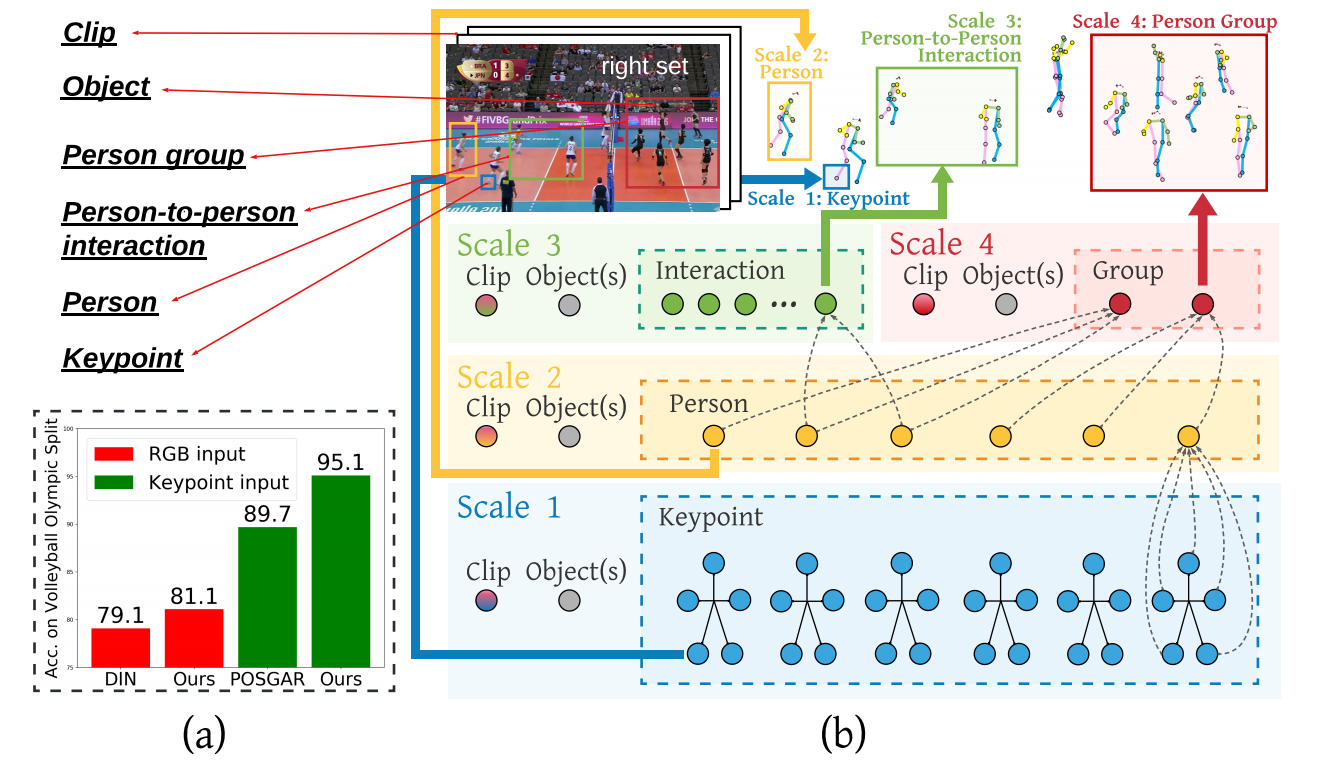
GAR任务要解决的两个难题:
- 对于整个复杂场景做复合式理解
- 在所有场景元素上进行关系推理
使用key-point模态的好处:
- 对数据进行去隐私化,减少道德问题
- RGB输入对背景、光线亮度、以及纹理信息较为敏感,而key-point不会
网络结构
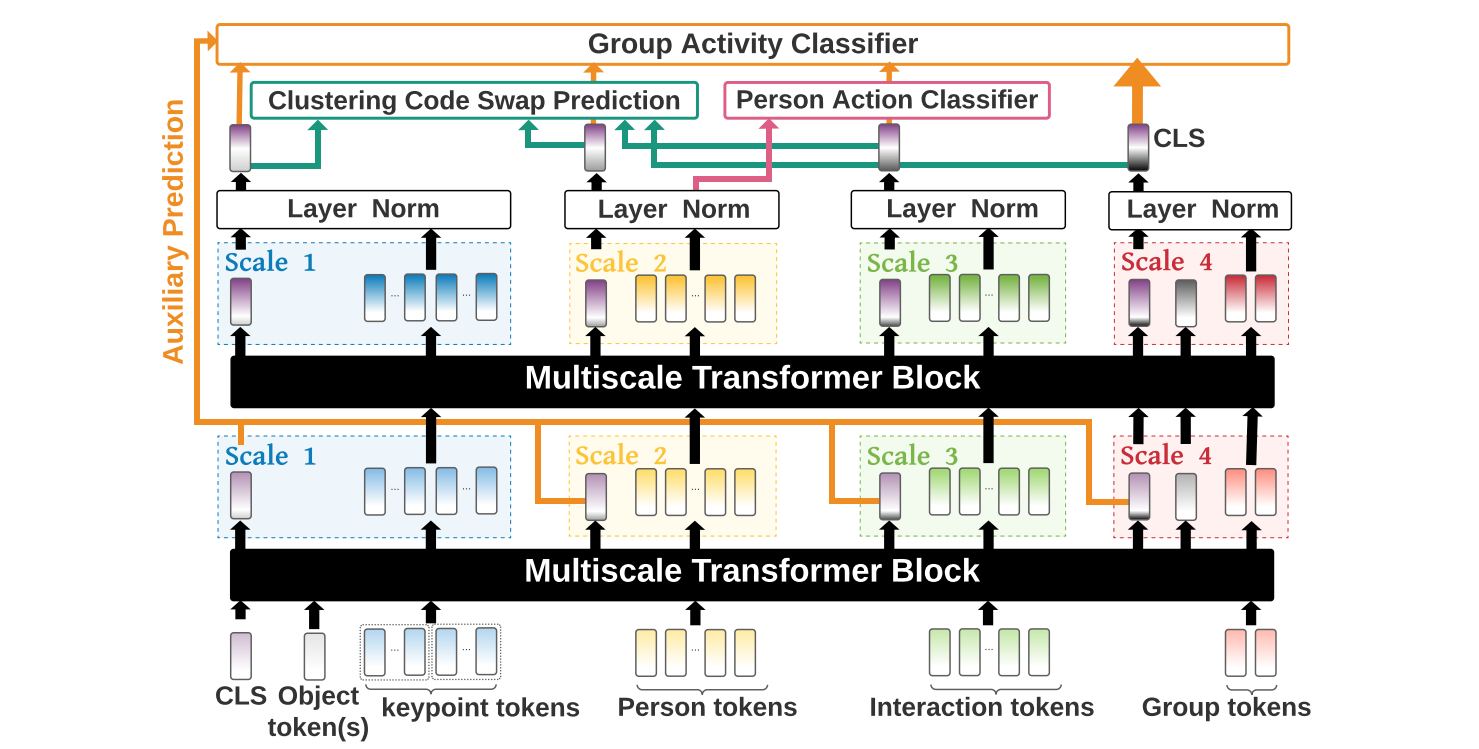
Multiscale Transformer Block
多尺度transformer块可以层次式地对不同尺度的tokens进行关系推理。
- 人体关键点(key point):
—第p个person第j个关键点的特征。人体关键点初始化包括:坐标嵌入,时间信息嵌入,关键点类型嵌入。 - 人(person):
—对person关键点坐标在时间维度进行聚合,并作线性变换。 - P-to-P交互(interactions):
—人p和人q之间的交互初始化为, 的连接,并作线性变换。 - 人群(person group):
—对场景内的人进行聚合(使用k-means等算法) - 剪辑(clip):CLS是一个可学习的嵌入向量,它可以使得transformer可以从输入序列的所有tokens中总结分类相关的特征表示信息
- 对象(object):这里特指球关键点
,因为它可以帮助我们更好地识别关键球员。
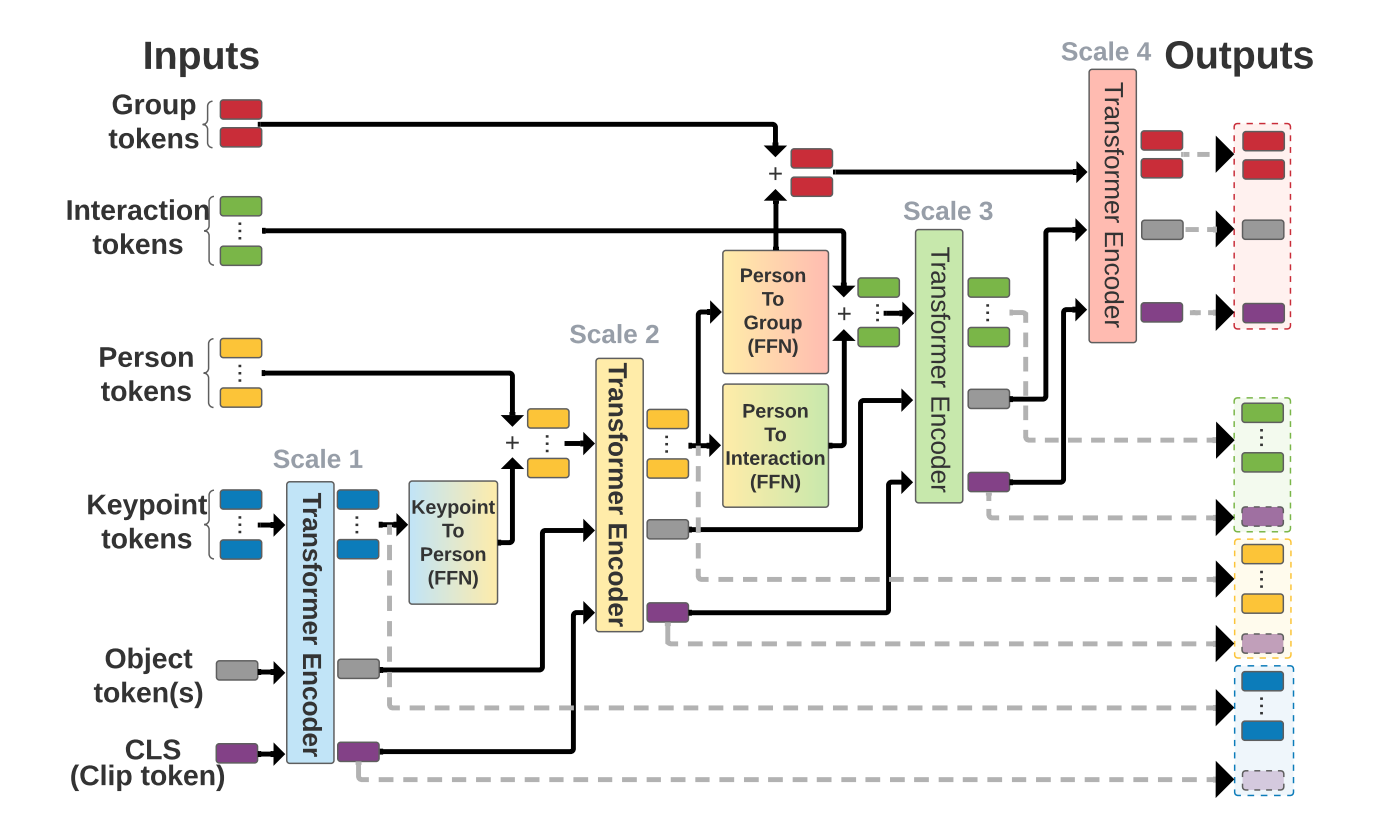
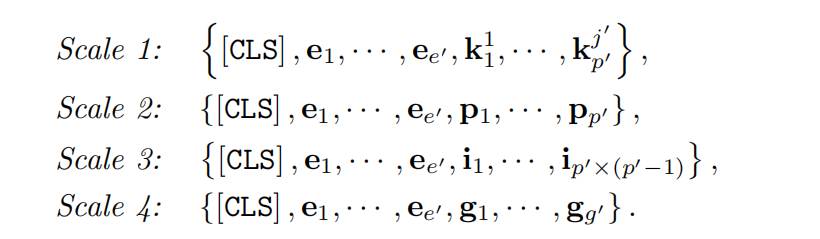
由上图可知,multiscale transformer block在不同的尺度上有着差异化的输入,但是每个尺度的操作都是相同的。
尺度一致的对比聚类
我们强制同一clip的不同scale下的表示在聚类时所分配的标签是一致的,这其实是对特征空间的一种正则化处理。论文使用了交换预测(swapped prediction)机制来保证一致性。
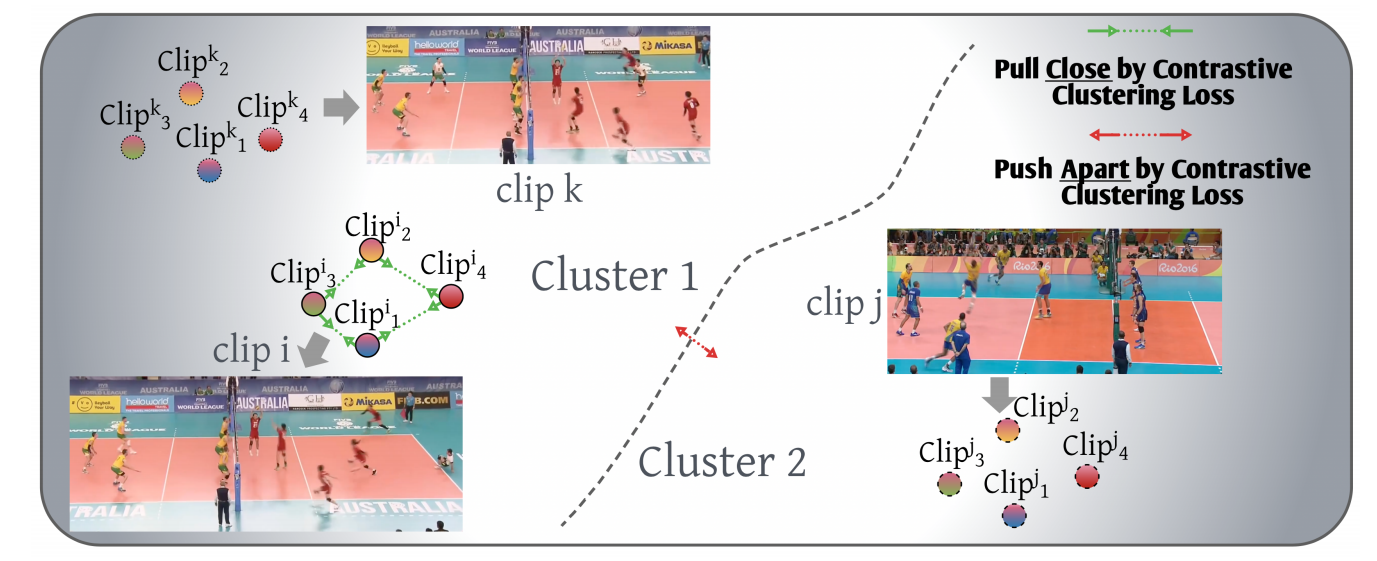
这种对比学习方法可以增强中间特征表示,从而提升总体效果。
- 假设$v {n,s} \in \R^d
{c_1,…c_k} q{n,s} \in \R^K v_w q_s v_s q_w$,交换损失函数如下式:
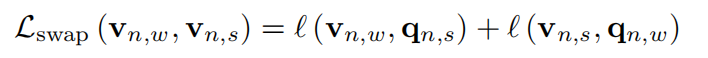
其中l函数计算匹配程度:
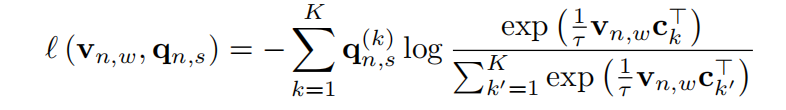
总体的交换损失为:
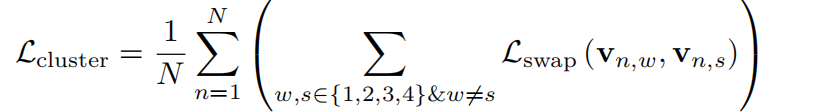
实验结果
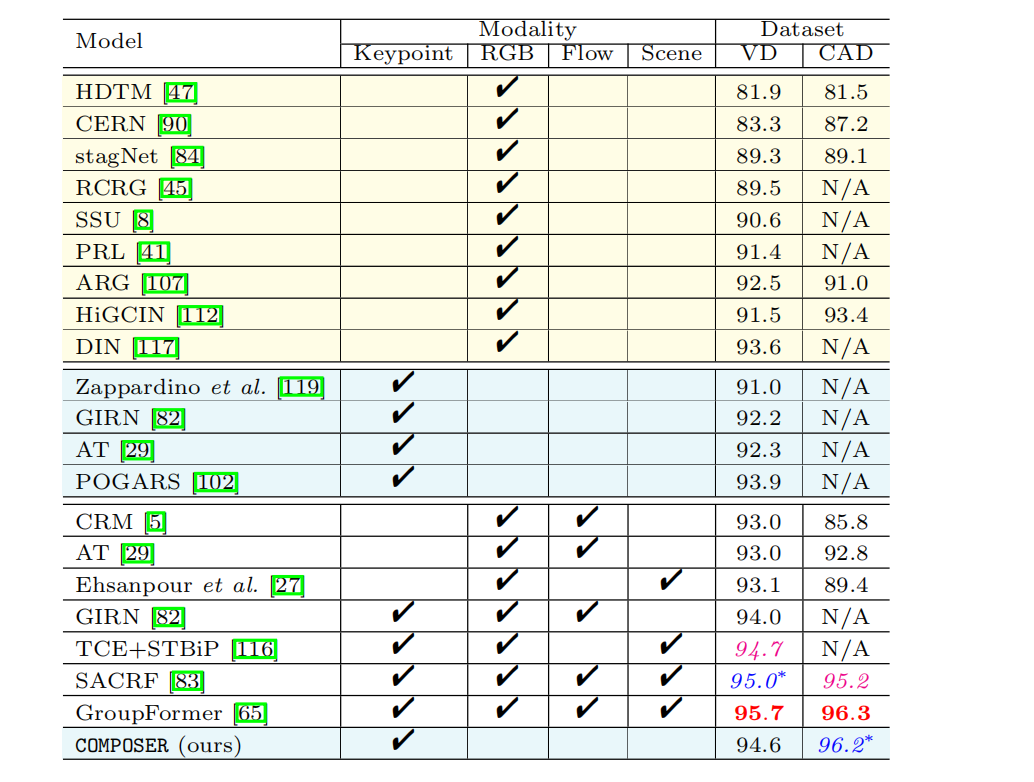
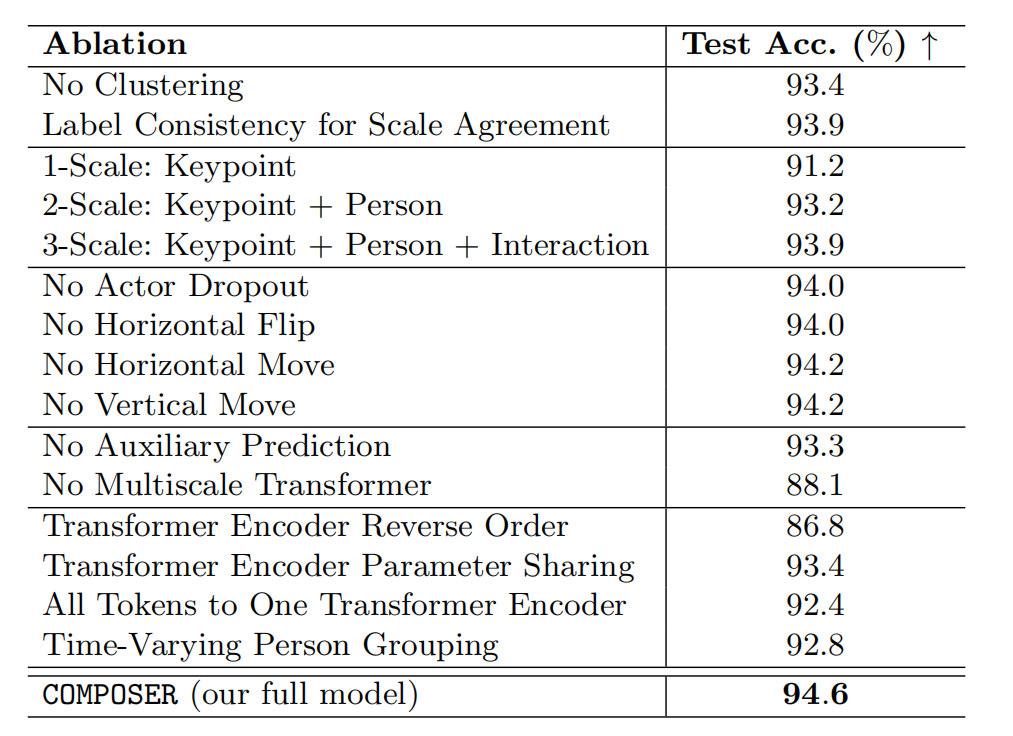
- 正则化多尺度表示
- 多尺度表示可以表达更多的信息,和更有效的尺度一致性
- 数据增强可以有效增加训练数据大小,注入有效噪声,使得泛化更容易
- 辅助预测可以帮助学习中间表示
- 多尺度transformer可以通过组合推理的方式从细粒度到粗粒度学习视频的高层信息表示
- 参数共享和只使用单一的encoder效果都不好,使用反向的encoder效果会更差。

GroupFormer中的CSTT模块有5个transformers并且还对图像场景进行了处理,所以计算昂贵。如果只使用RGB模态,composer的计算量为127M,因为它只需建模3个scales。
- Post title:论文阅读笔记:“COMPOSER:Compositional Reasoning of Group Activity in Videos with Keypoint-Only Modality”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_051/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments