论文阅读笔记:“ActionVLAD:Learning spatio-temporal aggregation for action classification”

ActionVLAD: Learning spatio-temporal aggregation for action classification
论文思想
时空信息聚合
将特征空间划分为K个区域,该区域可以表示为“action words”,也可以称其为锚点(achor points ck)
公式:
上面的公式对特征与锚点(typical actions)之前的差异在整个视频维度进行了求和。
why use VLAD to pool?
HOW to combine RGB and FLOW streams?
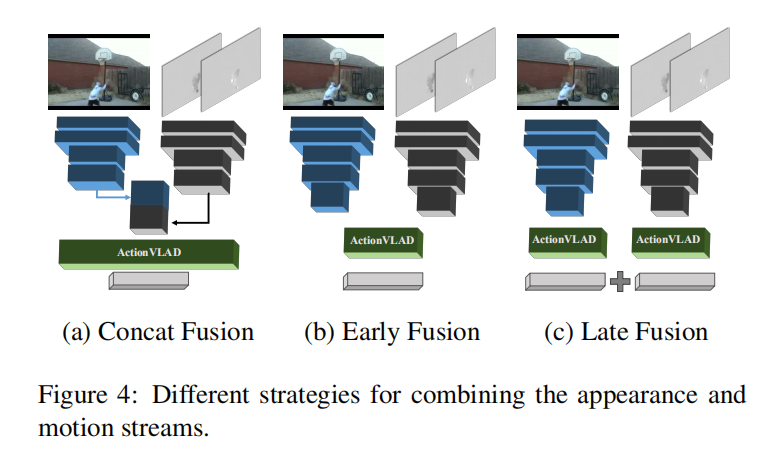
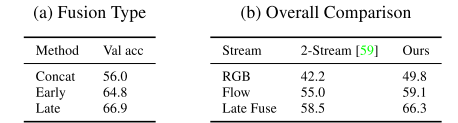
Ideas?
- can I add a attention to VLAD?
- where to add attention?
- can I add non-local to VLAD?
Todos
- run the VLAD code
- look at the core codes where the VLAD is implemented
- try out the ideas that may work well
- Post title:论文阅读笔记:“ActionVLAD:Learning spatio-temporal aggregation for action classification”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_056/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments