论文阅读笔记:“Real-world Anomaly Detection in Surveillance Videos”

论文阅读笔记:“Real-world Anomaly Detection in Surveillance Videos”
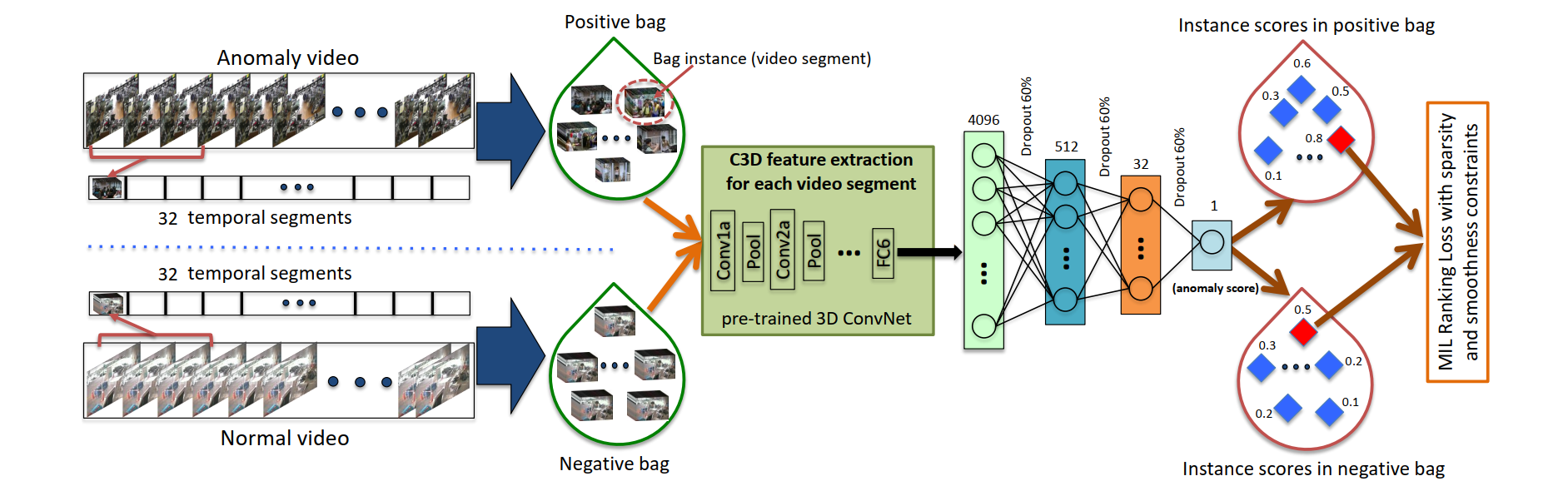
实际异常检测系统需要实时对那些偏离正常模式的行为发出警告,并识别发生异常的时间窗口。检测到异常行为之后,可以进一步用分类的方法来识别是哪种异常行为。
难点是现实中的异常行为很多,很难去列出所有的异常事件。所以我们应该期望我们的算法不依赖于任何关于异常事件的先验知识。所以异常检测应该用尽量少的监督来完成。之前的方法用正常事件构建正常行为字典,异常行为没有办法通过正常行为字典来重建(机器学习中的稀疏编码)。但是现实中背景可能剧烈变化,导致不同背景下的正常行为可能被误认为异常行为(高假阳率)。
正常情况下,把所有的正常模式考虑进去来定义正常行为是几乎不可能的。而且正常行为和异常行为之间的边界有时也比较模糊。在不同条件下,同一个行为在一个 场景下是正常的,在另一个场景下确是异常的。所以正常行为和异常行为数据集能帮助我们去更好地构建异常检测系统仍是有争议的。
这篇论文创新性地把标注的范围上升到视频级别。也就是说只标注某个视频是否含有异常行为,但在哪里不需要标注。论文使用了多实例学习的方法,将正常和异常的监控视频视为包,并将每个视频的短片段/剪辑作为包中的实例。基于训练数据,可以自动学习异常排名模型,预测视频中异常片段的高异常分数。在测试过程中,一个未经修剪的长视频被分成多个片段并送入深度网络,该网络为每个视频片段分配异常分数,以便检测到异常。
多实例学习损失
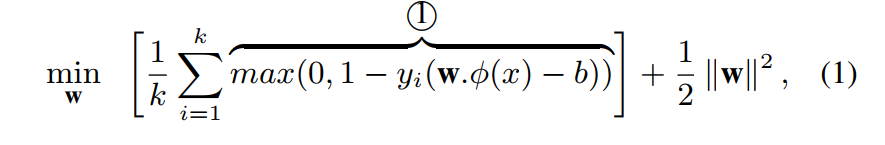
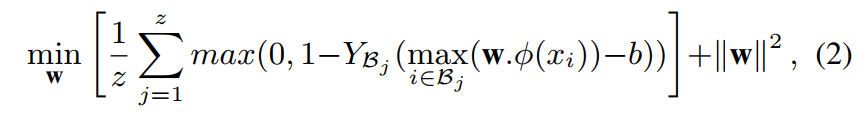
我们把一个异常视频作为一个正标签包,这其中包含许多视频片段,至少有一个实例是异常的。可以通过每个包中的最大分数实例来优化目标函数
多实例排名模型
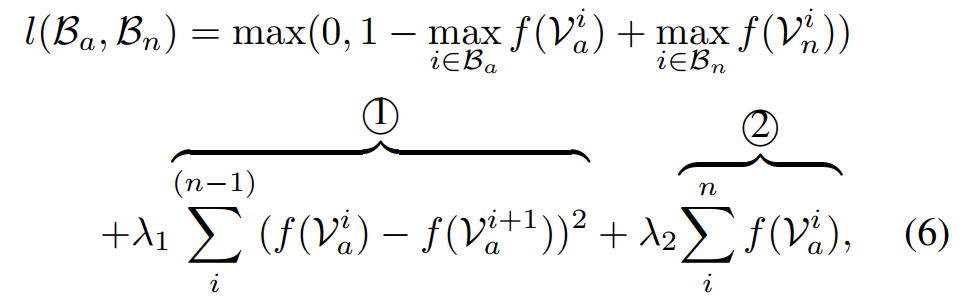
序号1时间上是尽可能平滑连续片段的分数,序号2是希望只有异常行为有较高分数,正常行为分数较低;主项是希望正样本和负样本尽可能地远离
评价指标
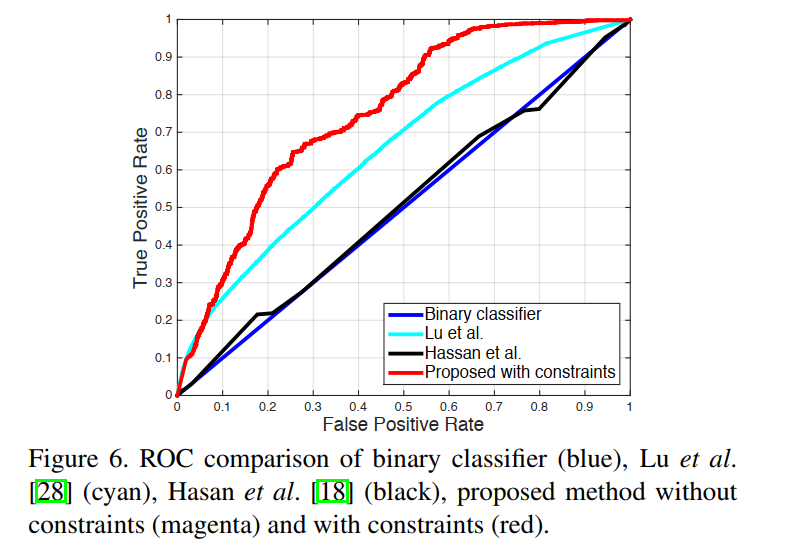
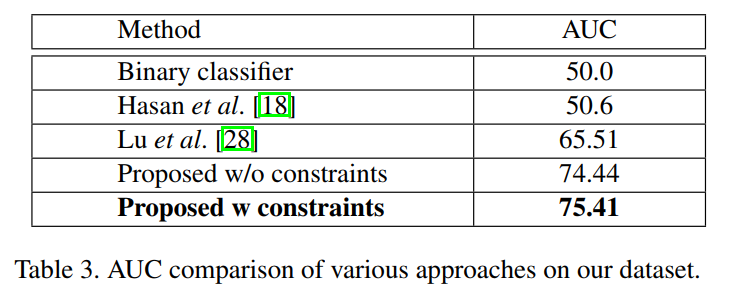
对于论文中的方法曲线下的面积是可以接受的
- Post title:论文阅读笔记:“Real-world Anomaly Detection in Surveillance Videos”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_064/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.
Comments