
Paper Reading Reflections on Action Recognition
3D Convolutional Neural Networks(TPAMI 2013)
多通道输入(input),包括灰度,x方向梯度,y方向梯度,x方向光流,y方向光流信息
模型组合(architechture)
捕获潜在的相互补充的信息
高层特征正则化(model)
对每个类别预编码一个高层特征,期待学习到的特征与预编码特征尽可能地接近
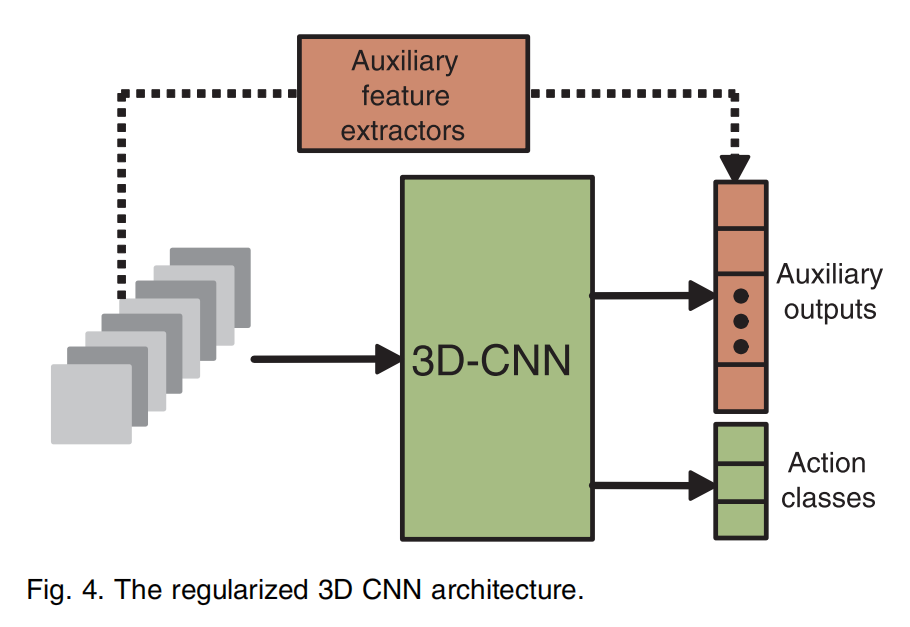
可视化(experiment)
对于没有正确分类的视频序列进行分析:

Large-scale video classification(cvpr 2014)
数据集(data)
计算效率(architechture)
双流法: scene stream and centre stream时空连接模式(model)
对于时域信息,我们采用在网络的早期(early fusion),后期(late fusion),或是处理过程中(slow fusion)进行融合的效果数据分析(experiment)
分类置信度bar图+对比
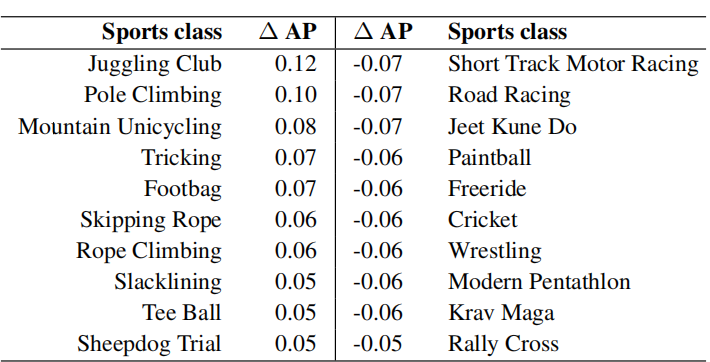
 **类别分类精度对比排序**
**类别分类精度对比排序**
 **filters可视化**
**filters可视化**

Learning Spatiotemporal Features(ICCV 2015)
- 模型可视化(experiment)

对学习到的特征进行分析(experiment)
紧凑性
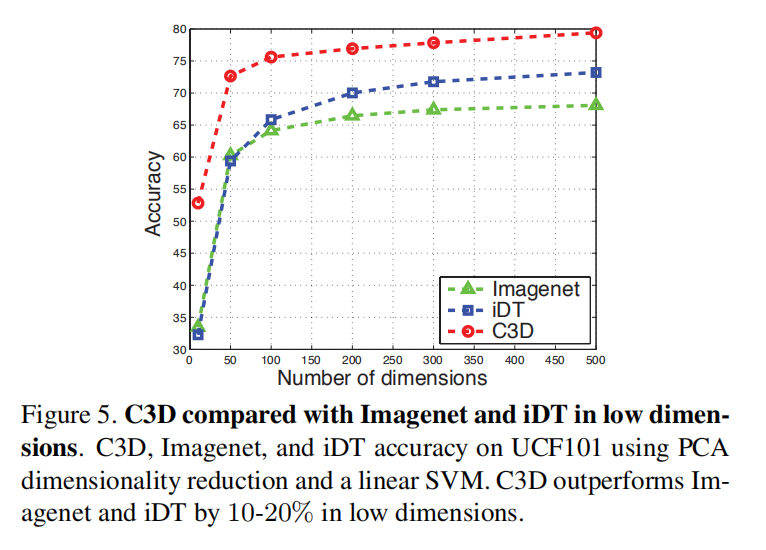
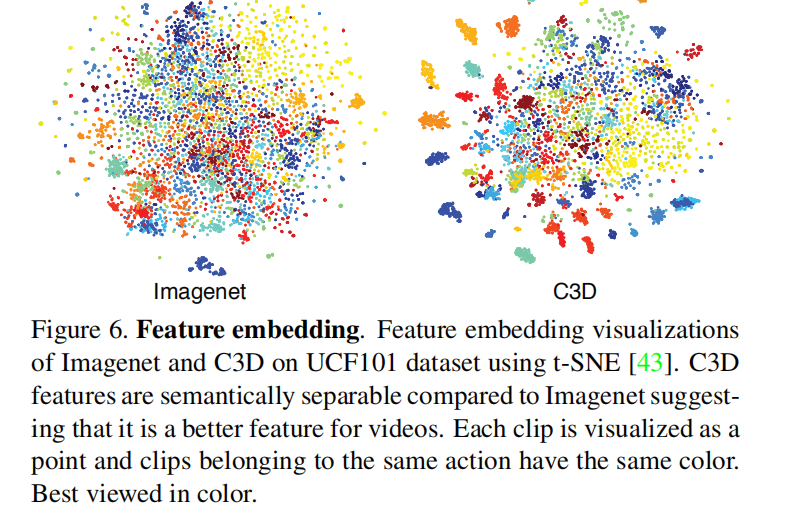
区分能力(t-SNE)
Quo Vadis, Action Recognition(cvpr 2017)
数据集(data):Kinetics
2D 卷积膨胀(model)
从视频中学习时空特征的同时,利用优秀的ImageNet网络架构及参数
双流架构(model)
双流算法采用的是 TV-L1 algorithm
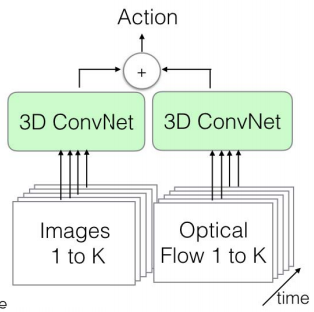
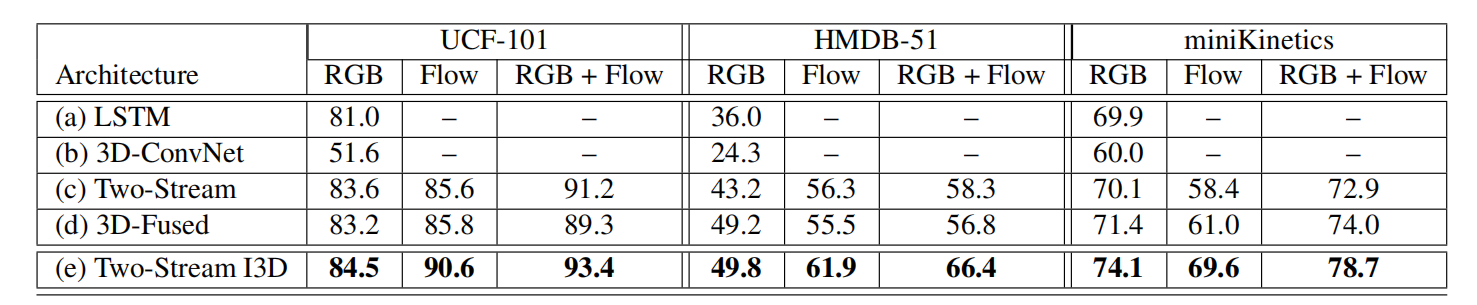
数据分析(experiment)
不同架构对比
Pseudo-3D Residual Networks
- P3D Block: 3D卷积解耦(model)
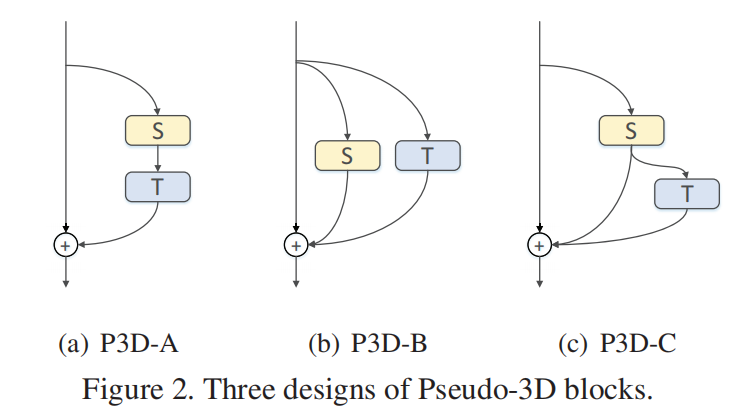
- P3D Chain: 利用结构多样性(architecture)

- 类别知识可视化(experiment)

A Closer Look at Spatiotemporal Convolutions
- 在解耦3D Filter方面对P3D做了优化(model)
R(2+1)D卷积块
它将
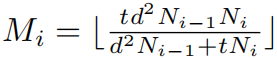
- mixed convolution(architecture)
3D卷积在网络的早些层,2D卷积在网络的后面的层
- 精度与复杂度对比(experiment)
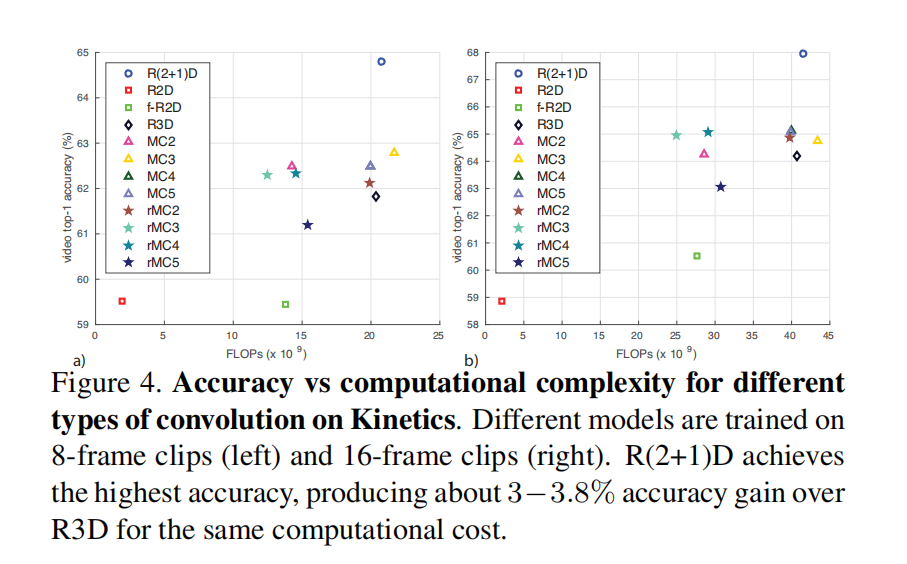
- 精度与输入帧数的关系(experiement)
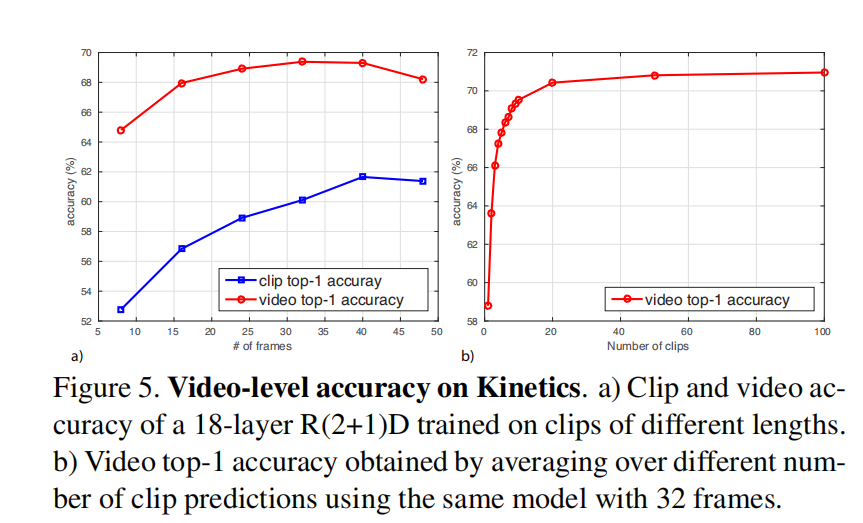
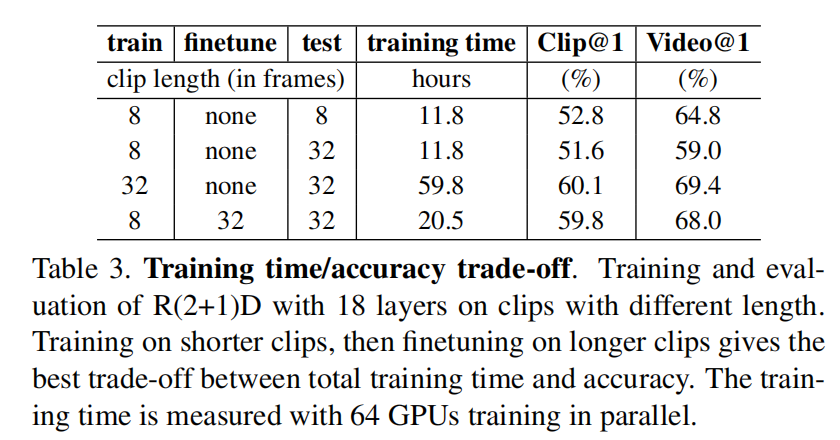
Findings: 在较短帧上进行训练,在较长帧上进行finetuning,会达到比较好的效果。
Long-Term Temporal Convolutions
主要看它的实验部分:
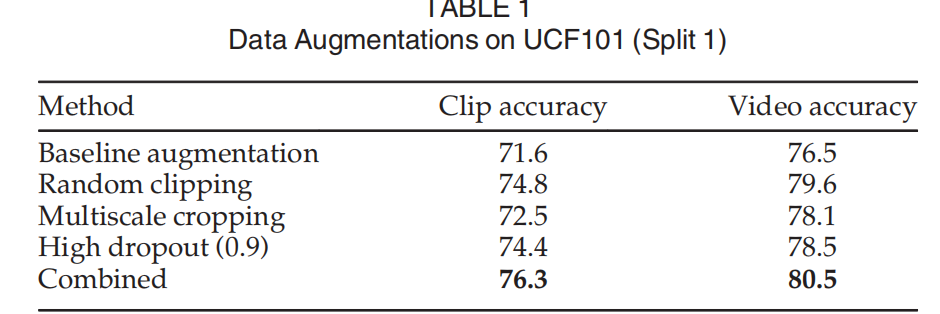
- 数据增强实验
- 模型组合

- 学习到的filters可视化

Non-local Neural Networks
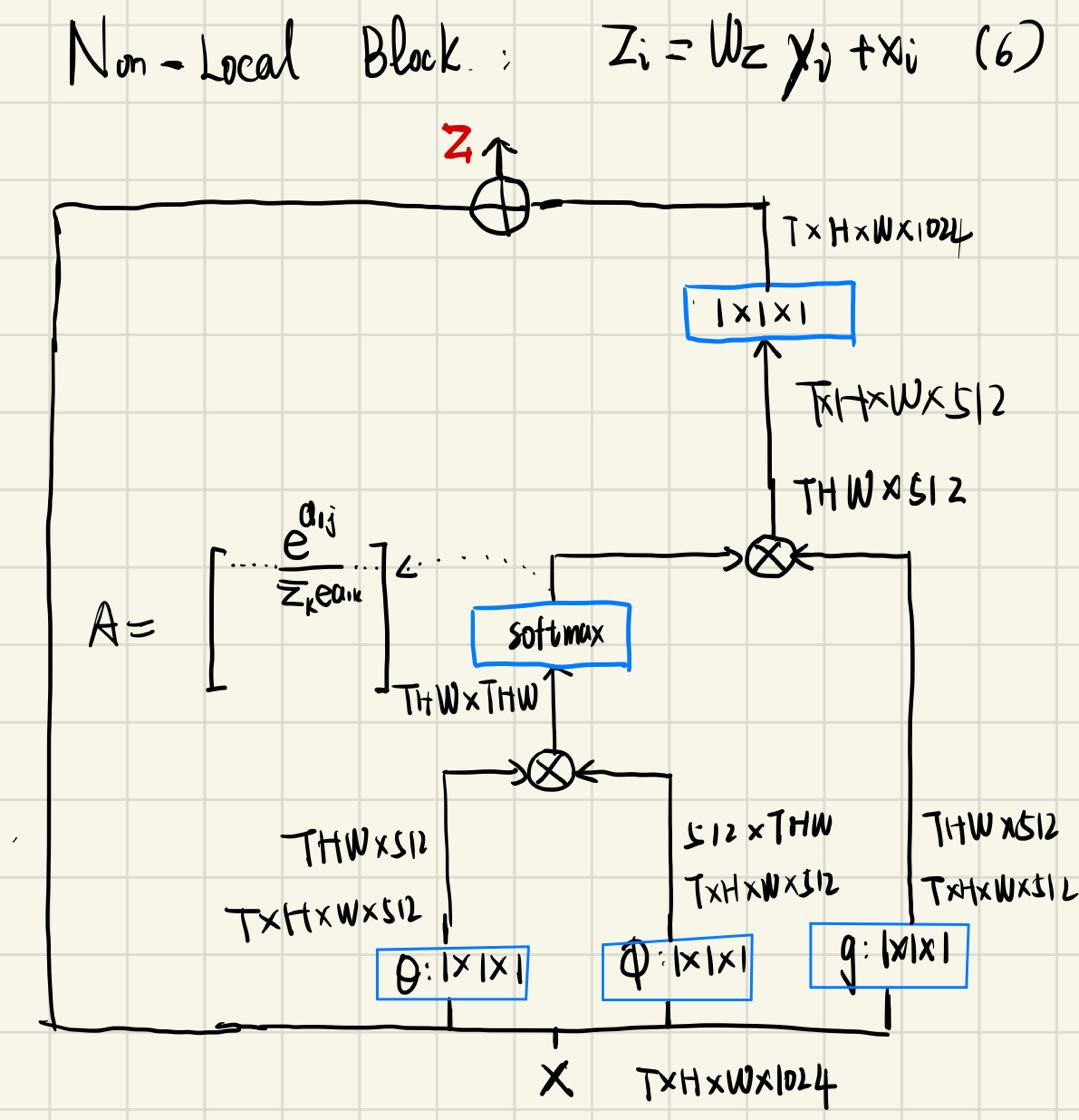
Non-local Block — 捕获长期时空依赖(model)
理解non-local块的前提是理解非局部操作:
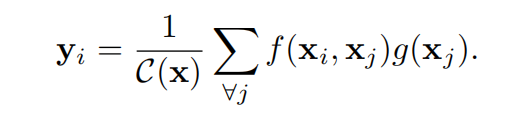
简单来讲,它计算的是第i个位置与其他所有位置的关系,进行求和与归一化后的值。在我的理解看来,
就像是两个位置的关系进行建模,而 是这个关系的权重。 二元函数f的选择是论文讨论的重点:
- 高斯:
- 嵌入高斯:
- 点积:
- 连接:
- 高斯:
文章还说明了自注意力模块与嵌入高斯版的非线性操作的异同,他们的最终形式是一样的:
作者将non-local块形式化地定义为:
- 能够让我们将新的non-local块插入任何预训练模型但不改变他的任何行为,只需将
初始化为0即可。 - 而是可以增强特征(+), 同时防止梯度消失。
加入non-local块的位置选择
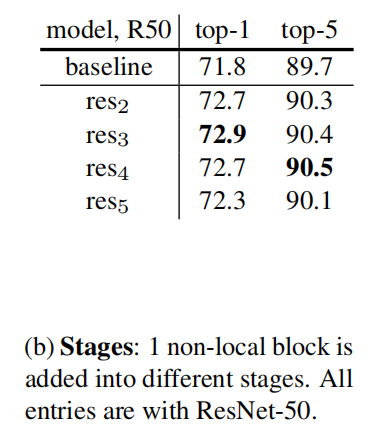
如图,加入到3,4 stage都是合适的
加入non-local块数的影响
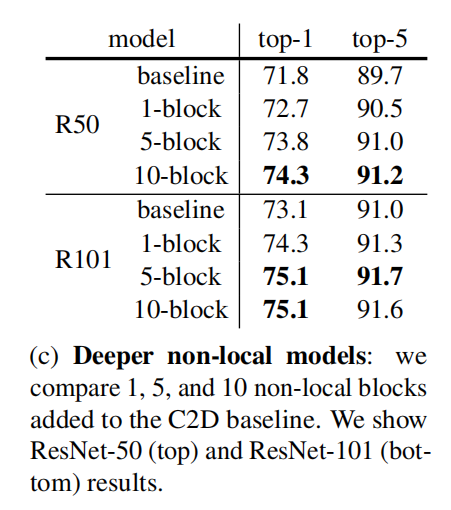
而且该实验也证明了精度的提升并不全部来自网络深度的增加
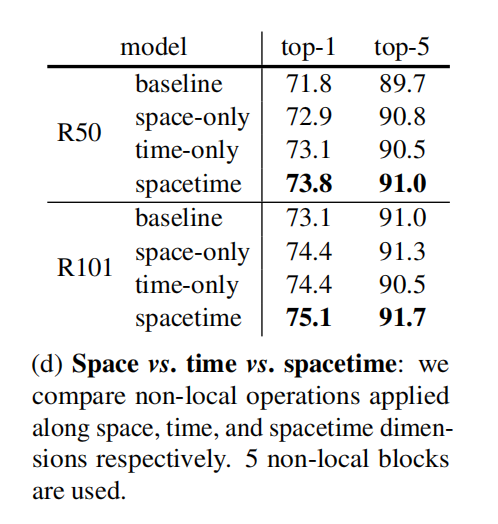
时间-空间-时空维度的non-local操作对模型的影响
- Post title:论文阅读笔记:“行为识别论文总结”
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/paper-reading/paper_reading_conclusion_01/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.