
pytorch 模型迁移复盘1
遇到的问题
VPN连接
目前,该问题已解决
连接华为提供的服务器需要vpn,在连vpn时遇到了一些问题:
- IP访问地址未设置正确
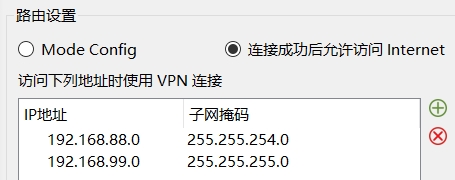
- 需启用隧道验证功能和IPSEC安全协议,通过预设身份验证字来连接
数据集大小
目前,该问题已解决
因为数据集较大,imagenet有近140G,直接下载会较慢,通过OBS链接进行下载会快很多。下载后对数据集解压会出现硬盘存储空间不足的问题:
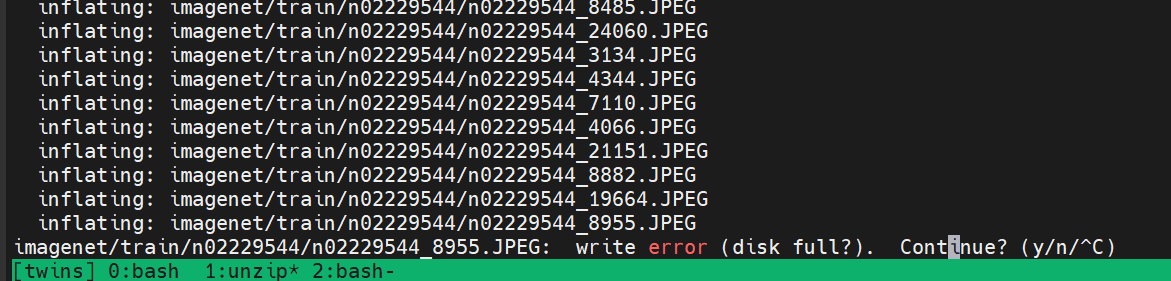
解决方法:
直接从gpu环境上scp一份解压好的上去
scp -r imagenet root@192.168.88.155:/opt/npu
Linux scp命令用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。可能会稍微影响一下速度。当你服务器硬盘变为只读read only system时,用scp可以帮你把文件移出来。另外,scp还非常不占资源,不会提高多少系统负荷,在这一点上,rsync就远远不及它了。虽然 rsync比scp会快一点,但当小文件众多的情况下,rsync会导致硬盘I/O非常高,而scp基本不影响系统正常使用。
从本地服务器传到另一台服务器的docker容器而无需密码
nohup scp -i /home/lyc/.ssh/id_rsa -P 10035 -r ImageNet2012/train/ root@202.117.21.93:/home/workspace/dataset/imagenet > transfer_imagenet_to docker 2>&1 &
代码版本不匹配
目前该问题已解决
因为我用的代码是pytorch1.7, 其中有一些新的接口1.5不支持,因此在NPU的torch1.5环境上需要修改API使之能跑通。主要修改点是torch.cuda.amp.autocast这个接口,将torch原生的amp接口改成apex的amp接口。
NPU环境不太好改
目前环境未出现问题
需要直接在裸机上跑,不能使用conda,因此想改变环境不太容易,目前的环境启动方法为:’’source /home/gp/test_op/setenv.sh’’。该文件的主要内容是设置一些NPU相关的环境变量。
GPU训练僵化
目前,该问题未解决
因为是多进程训练,当只有主进程输出的时候若其他进程意外退出,会导致整个程序僵死,而且其他进程出现了什么问题难以获知。因此可以将设置改为所有卡都进行输出,这样哪个卡报错从日志就可以获知。
如下是发现的问题:

从日志可以发现损失变成了nan导致训练直接结束
一开始以为是Loss scale过大导致loss为nan,实则发现,loss scale是在获得损失值并判断它是否为nan之后,也就是模型采用的loss函数导致了其为nan,和混合精度没有关系,目前还在想办法解决这个问题
循环依赖
目前,该问题已解决
首先,因为想迁移到NPU的同时兼容GPU,所有在获得参数后将其保存在了主程序的函数(useNpu)中,并在之后用到cuda的地方进行判断,看从main.py中引入的useNpu是否为True,如果为真就使用适配NPU的API,否则不变。但是这样改了之后出现了循环依赖:
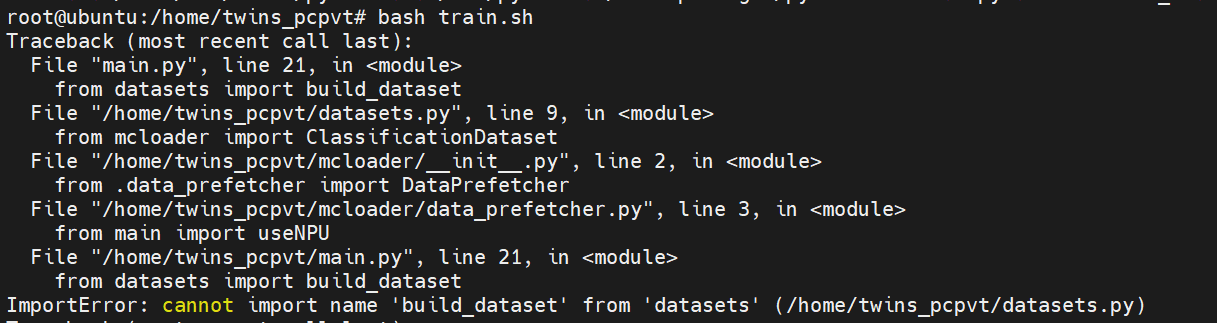
原因是main中引用了datasets中的build_dataset函数,通过层层import,最终又引用回了main文件,所以又需要再次引用datasets中的build_dataset函数,因此导致了循环依赖。
- 目前的修改方法主要有两种,将usenpu作为参数传给对应方法的默认参数,从而取代原先的import
- 去掉兼容GPU的功能,这样改兼容性差,不是很合理
采用第一种方法可以完美解决问题
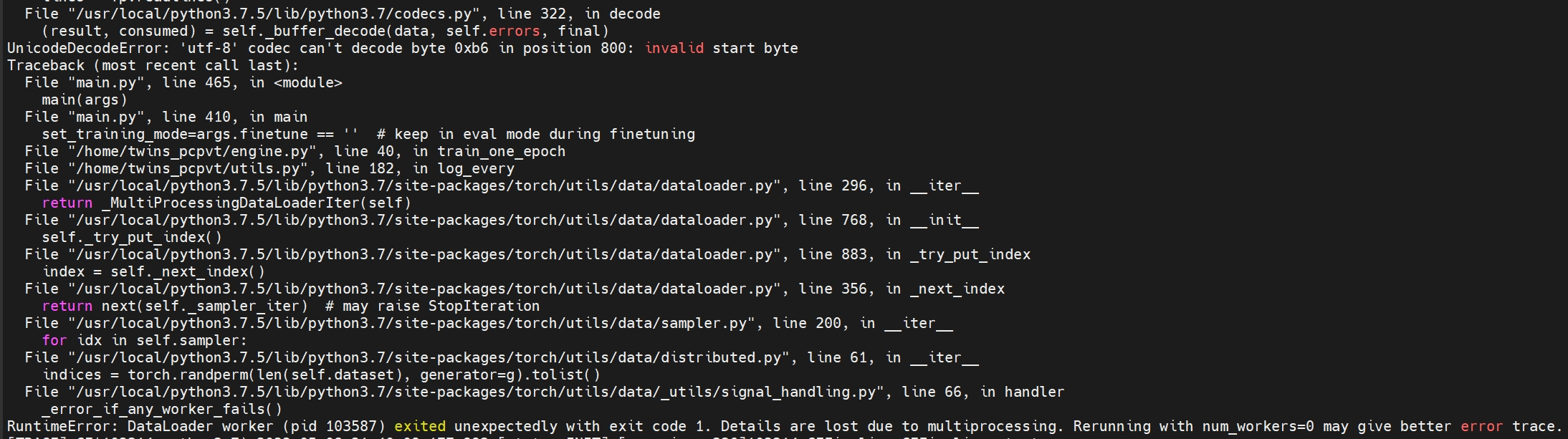
unicode编码错误
目前,该问题已解决
当把循环依赖改好了后,出现了UnicodeDecodeError,我怀疑是我在注释里用了中文所以导致出现了问题,但是utf-8是支持中文的而且gpu跑就没有这个问题,所以有点困惑。因为之前是在服务器上改的,没有语法错误提示,我拉到本地IDE中同步一下看看代码有没有问题。
- Post title:
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/projects/huawei project/华为项目:过程记录及复盘/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.