自动半精度(混合精度)训练
一. apex 与 amp
apex是英伟达构建的一个pytorch扩展,amp为其中提供混合精度的库
二. fp16的问题
2.1 数据溢出(下溢)

2.2 舍入误差

三. 解决方法
3.1 FP32权重备份
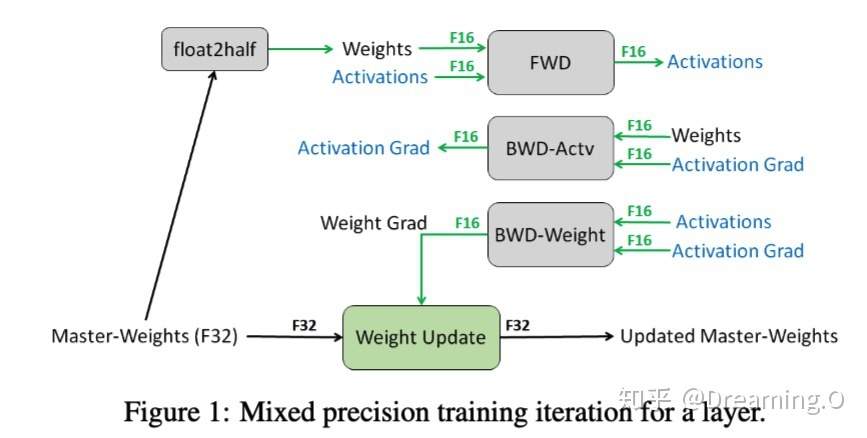
只有更新的时候采用F32
3.2 loss scale损失放大
根据链式法则,可以通过放大loss从而放大梯度来解决舍入误差
3.3 提高算数精度
利用fp16进行乘法和存储,利用fp32来进行加法计算,来减少加法过程中的舍入误差,保证精度不损失
四. 快速使用
1
2
3
4
5
| from apex import amp
model, optimizer = amp.initialize(model, optimizer, opt_level="O1",loss_scale=128.0)
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
|
opt_level 优先使用O2,若无法收敛则使用O1
如下是两个pytorch原生支持的apex混合精度和nvidia apex的loss scaler的具体实现:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| import torch
try:
from apex import amp
has_apex = True
print("successfully import amp")
except ImportError:
amp = None
has_apex = False
print("can not import amp from apex")
class ApexScaler:
state_dict_key = "amp"
def __call__(self, loss, optimizer, clip_grad=None, parameters=None, create_graph=False):
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward(create_graph=create_graph)
if clip_grad is not None:
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), clip_grad)
optimizer.step()
def state_dict(self):
if 'state_dict' in amp.__dict__:
return amp.state_dict()
def load_state_dict(self, state_dict):
if 'load_state_dict' in amp.__dict__:
amp.load_state_dict(state_dict)
class NativeScaler:
state_dict_key = "amp_scaler"
def __init__(self):
self._scaler = torch.cuda.amp.GradScaler()
def __call__(self, loss, optimizer, clip_grad=None, parameters=None, create_graph=False):
self._scaler.scale(loss).backward(create_graph=create_graph)
if clip_grad is not None:
assert parameters is not None
self._scaler.unscale_(optimizer)
torch.nn.utils.clip_grad_norm_(parameters, clip_grad)
self._scaler.step(optimizer)
self._scaler.update()
def state_dict(self):
return self._scaler.state_dict()
def load_state_dict(self, state_dict):
self._scaler.load_state_dict(state_dict)
|
apex + 分布式:
apex ddp默认使用当前设备,torch ddp需要手动指定运行的设备,用法和torch类似,
但需注意
1
| model, optimizer = amp.initialize(model, optimizer, flags...)
|
应在
1
| model = apex.parallel.DistributedDataParallel(model)
|
之前
