
基于知识图谱的开放域问答系统
一. 项目总体介绍
1. 任务目标
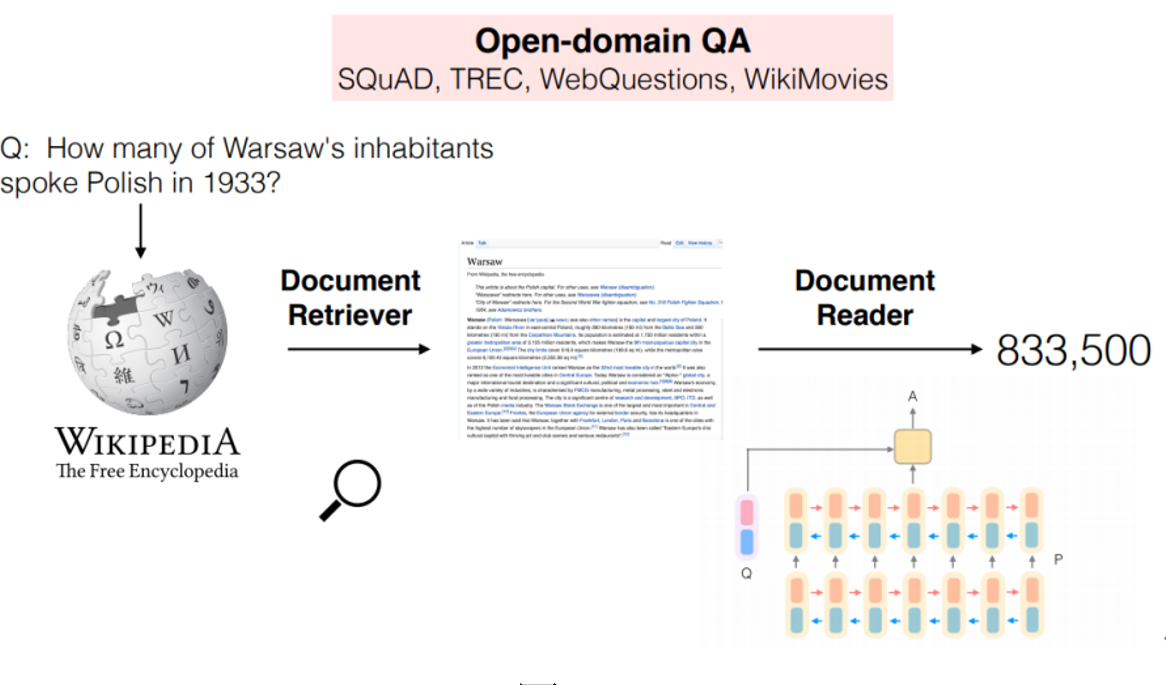
开放域问答系统:
使用大量不同主题的文档来回答问题,是自然语言处理(NLP)、信息检索(IR)和相关领域长期研究的主题。
知识图谱:
知识图谱(Knowledge Graph),是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构。

2. 模型整体设计及流程
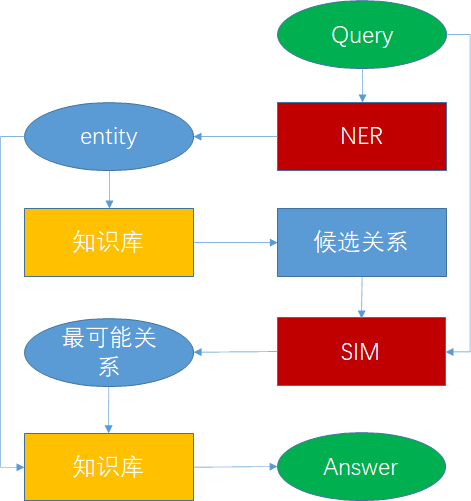
具体流程如下:
- 使用NER模型从问题中抽取实体并将其送入知识库进行匹配,找出所有可能的候选关系。
- 使用相似度模型计算所有候选关系与问题实体的相似度,找到可能性最大的候选关系。
- 使用该候选关系在知识图谱中查找,找到最终答案。
二. 模型介绍
1. 命名实体识别(NER)
命名实体识别( NER )是信息提取、问答系统、句法分析、机器翻译等众多NLP任务的重要基础工具,旨在将非结构化文本中提到的命名实体定位并分类为预定义的类别,例如人姓名、组织、地点、医疗代码、时间表达、数量、货币价值、百分比等。
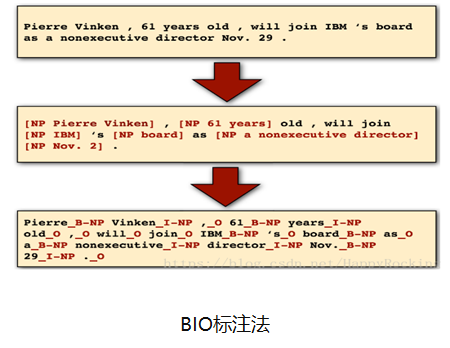
BIO标注法
将每个元素标注为“B-X”、“I-X”或者“O”。其中,“B-X”表示此元素所在的片段属于X类型并且此元素在此片段的开头,“I-X”表示此元素所在的片段属于X类型并且此元素在此片段的中间位置,“O”表示不属于任何类型,如下图所示:
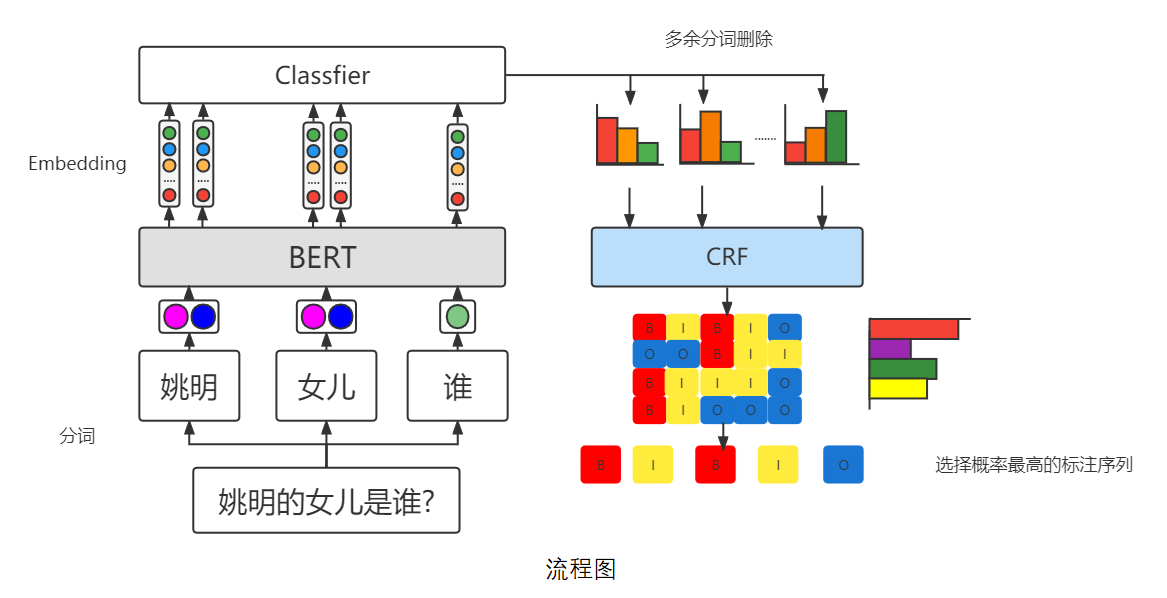
NER模型结构
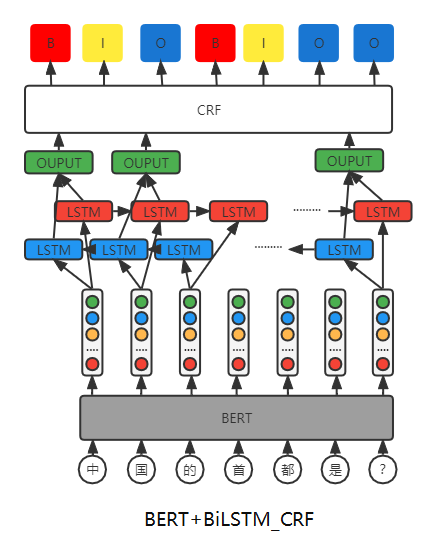
上图展示的NER模型使用Bert+BiLSTM+CRF的结构,首先使用Bert对输入的句子进行embedding,然后将这些向量输入BILSTM提取句子信息,最后输入CRF测算不同标注序列的概率,最后选取概率最大的序列作为最终结果。具体流程如下图所示。
2. 相似度计算(SIM)
模型设计
KGQA子任务(关系识别)
确定哪个关系必须被逻辑形式的特定部分使用是一项关键任务。类似于实体链接,我们需要学习映射自然语言表达到知识图谱,在该任务中是针对关系映射。
阶段目标
获得问题与知识三元组<头实体,关系,尾实体> 中相对应的关系。
上游任务
获得通过NER阶段识别到的头实体。
下游任务
通过头实体与SIM计算得到的关系检索尾实体(答案)。
流程实现
根据识别到的实体,通过es接口找到可能的候选关系的列表
训练相似度模型进行关系预测:输入为问句和候选关系的拼接,输出为两者相似度
获得问句和候选关系的相似度,以最高相似度的关系作为结果用于下游任务
三. 数据集介绍
知识库
知识库来源于百科类数据,由百科类搜索页面的事实性三元组构成。格式为<头实体,关系,尾实体>

| 实体数量 | 关系数量 | 高频关系(>100) | 三元组数量 |
|---|---|---|---|
| 3121457 | 245838 | 3833 | 20559652 |
问答数据集
问答数据集为json格式,每行为一条问答对。问题是one-hop问题,即答案为知识库中的一条三元组。数据格式如下,其中id为问答对索引,quetion为问题,answer为答案,来自知识库,以’ ||| ‘分割。

| Corpus | Train | Dev | Test Public | Test Private |
|---|---|---|---|---|
| Num Samples | 18k | 2k | 2k | 3k |
| Num Relations | 2164 | 1258 | 1260 | 423 |
四. 项目设计与体验优化
1. 项目设计前端
项目采用前端采用uni-app框架,开发者编写一套代码,可发布到iOS、Android、Web(响应式)、以及各种小程序、快应用等多个平台。

2. 项目设计后端
项目后端采用flask框架,搭建简便快速,较其他同类型框架更为灵活、轻便、安全且容易上手;flask社区活跃,基于flask的应用插件及其丰富,足够满足后端需求,同时它也具有很好的扩展性。

3. 体验优化
意图识别
普通的问答系统难以满足日益增长的用户需求,如果是知识库中不存在的问题或是用户的意图不够明确的话,问答系统都难以给出我们期望的回复,因此实现一个可以能够理解我们在问什么的,并能根据我们的询问以不同的方式来回复的聊天机器人是很必要的。目前的话,该项目采用的svm分类器,对预先可能的结果进行分类。作为训练数据目前主要有三类,如打招呼,百科信息询问,普通聊天。若分类为信息询问,则接入我们的问答接口,如果是普通聊天,则接入我们的聊天机器人接口。因为是手动构想用户可能的输入作为训练数据,所有难免效果不好,未来我们打算采用RASA这一更加强大的框架作为我们的意图分类器。
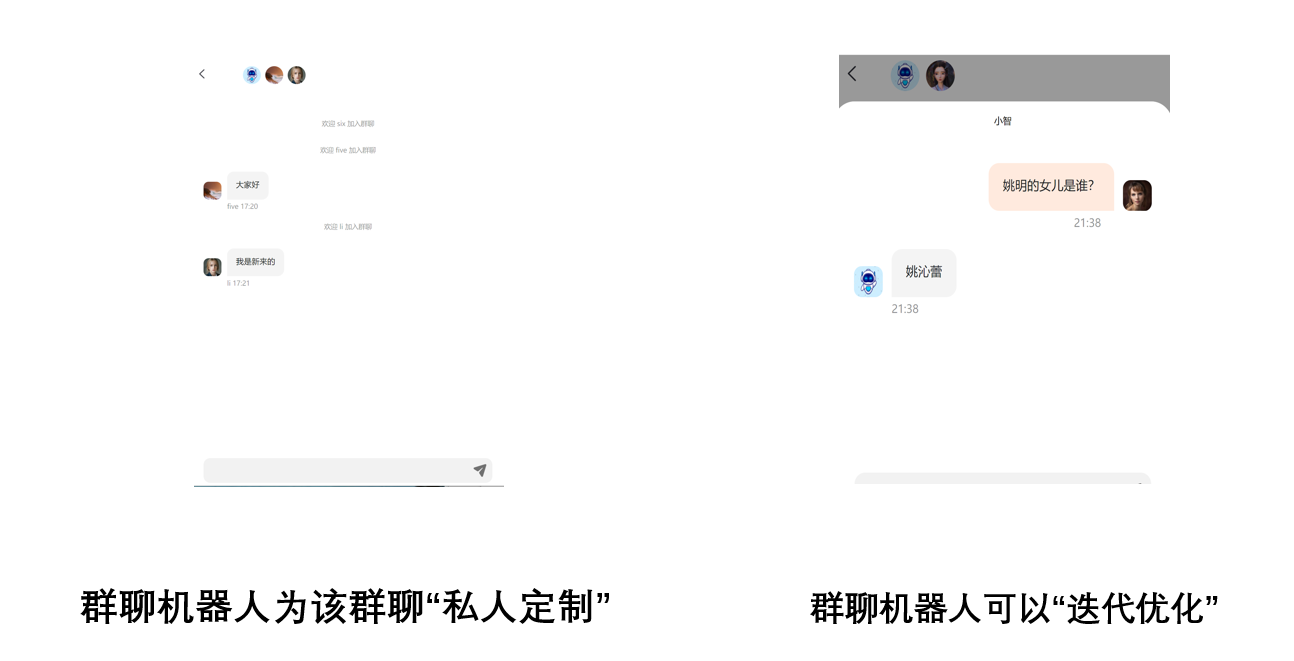
聊天室
设计聊天室的功能,是有多方面因素推动的,而非冗余的扩展。
首先的目的是分不同的群组,每个群组有特定支持的机器人,即该机器人是用该领域的语料训练的,并且表现较好。
二是收集特定领域的语料数据,有利于机器人把握句子的语义,持续有新的训练数据补充来对模型进行更新,有利于模型的迭代优化。
五. 个人工作总结
后端模型代码基于该仓库进行修改
NER和SIM模型解耦(提取出推理部分,去掉了冗余wrapper)
Flask服务器搭建及与前端交互的代码(socketio)编写加调试
前端Uniapp聊天室编写及与后端交互的代码编写加调试
将该项目开源到gitee仓库并进行维护
- Post title:基于知识图谱的开放域问答系统
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/projects/nlp project/项目概览/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.