
数据挖掘-AI-Earth项目
背景
2021 “AI Earth”人工智能创新挑战赛:链接
发生在热带太平洋上的厄尔尼诺-南方涛动(ENSO)现象是地球上最强、最显著的年际气候信号。准确预测ENSO,是提高东亚和全球气候预测水平和防灾减灾的关键。
任务
基于历史气候观测和模式模拟数据,利用T时刻过去12个月(包含T时刻)的时空序列(气象因子),构建预测ENSO的深度学习模型,预测未来1-24个月的Nino3.4指数
模型
STTransformer
训练
学习率衰减策略
训练初期学习率大一些,使得网络收敛迅速,在训练后期学习率小一些,可学习该post了解更多
STTransformer采用了Noamopt优化策略,详细可参考Annotated Transformer, Harvard NLP Group, ArdalanM/annotated-transformer,衰减公式如下所示:
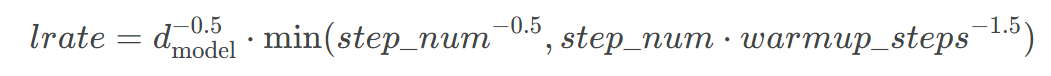
训练器
包含变量:
- 配置 config
- 设备 device
- 网络结构 network
- 优化器 opt
optim作用:基于梯度更新当前的参数,具体地,其
step()方法可以更新所有参数(要在梯度计算出来之后调用,例:loss.backward())
注意,将model放入gpu在构建优化器之前
- 权重 weight
我们可以由下图得知,不同的月份有不同的权重,self.weight实际上是公式1.2中的

1 | self.weight = torch.from_numpy(np.array([1.5]*4 + [2]*7 + [3]*7 + [4]*6) * np.log(np.arange(24)+1)).to(configs.device) |
包含函数:
得分函数score
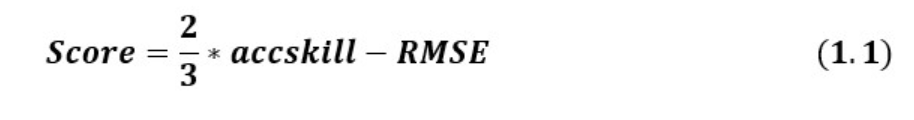
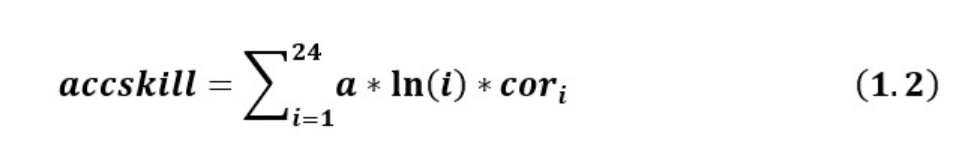
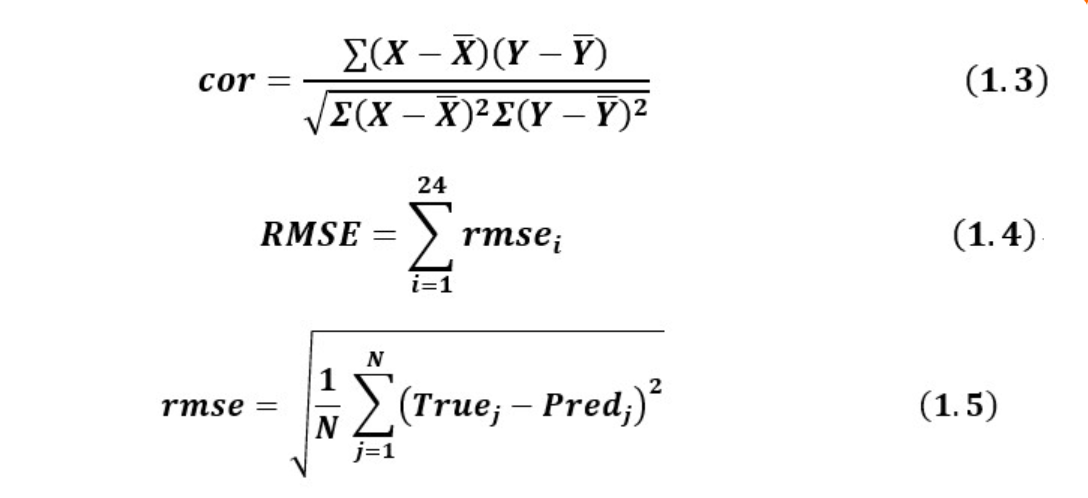
1 | # 中心化 |
- sst损失函数
在经纬度上计算均方根误差,再在样本维度上求均值,再返回所有月份的和
1 | # (5400+5010,26,1,24,48) |
- nino损失函数
1 | # (5400+5010,24) |
- 训练单步
需要三个输入:input_sst, sst_true, nino_true, ssr_ratio,将input_sst和sst_true作为source和target送入STTransformer进行处理,输出为sst_pred, nino_pred。
注:该模型虽然提供了两个Loss函数,但是只根据sst损失函数来更新梯度
在计算得到梯度之后,更新参数之前,代码使用了梯度裁剪的方法来防止梯度爆炸
注:梯度裁剪:如果梯度变得非常大,那么我们就调节它使其保持较小的状态
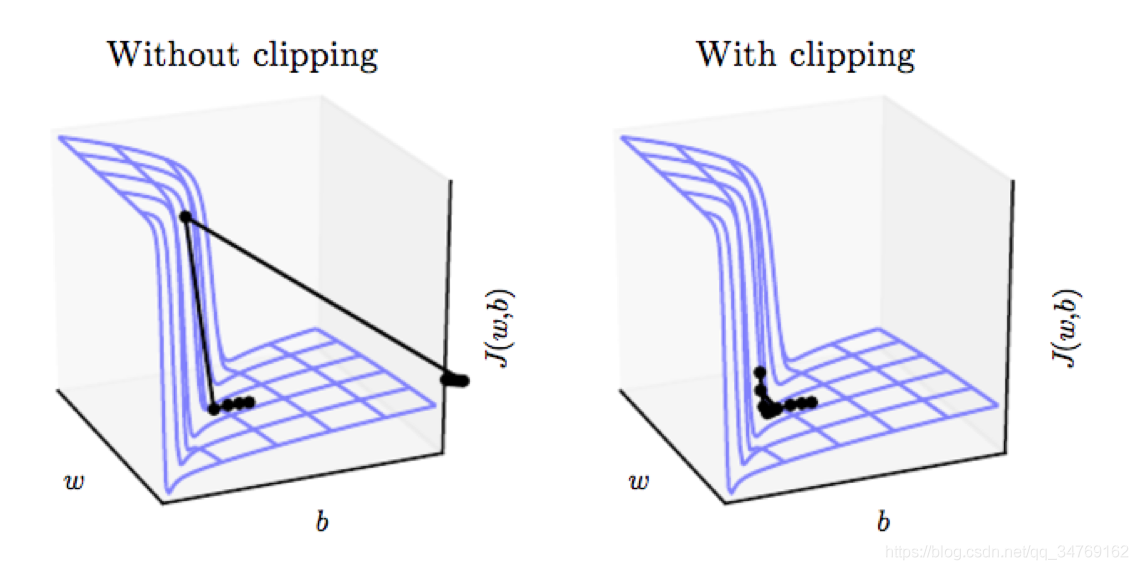
训练单步的返回为sst损失, nino损失和nino_pred
- 测试
测试函数将测试数据数据送入网络得到了sst_pred, nino_pred,将他们存入了列表中,之后在样本维度将他们连接起来,这样的好处是损失计算是针对整个测试数据集的。
- 推理
在推理函数中使用了上面的test函数,可以直接计算损失:
1 | nino_true = torch.from_numpy(dataset.target_nino).float().to(self.device) |
推理函数的返回值即为loss_sst,loss_nino,sc
- 训练
训练时首先将准备好的训练集和验证集用dataloader封装一下我们的cmip_dataset,并设定其为随机采样。将最好的score设定为负的无穷大浮点数。在每一个epoch里,更新ssr比率,调用train_once得到我们的损失和nino预测。根据nino预测和真实值我们可以得到score,它不只是在每个epoch结束后进行evaluate而是每300个batch评估一次,以免最优点被错过,因为该模型的训练时间较短。训练还设计了patience机制,若多个epoch之后score未变好就直接结束训练。
保存config
保存模型ConvTTLSTM
训练入口main函数:
main做的都大同小异,首先读入数据,并划分为训练,验证和测试集,之后使用cmipdataset对训练集和测试集进行wrap,初始化训练器进行训练即可:
1 | trainer = Trainer(configs) |
模型
模型结构
论文设计的自注意力模块(Space-Time Attention)如下图所示,
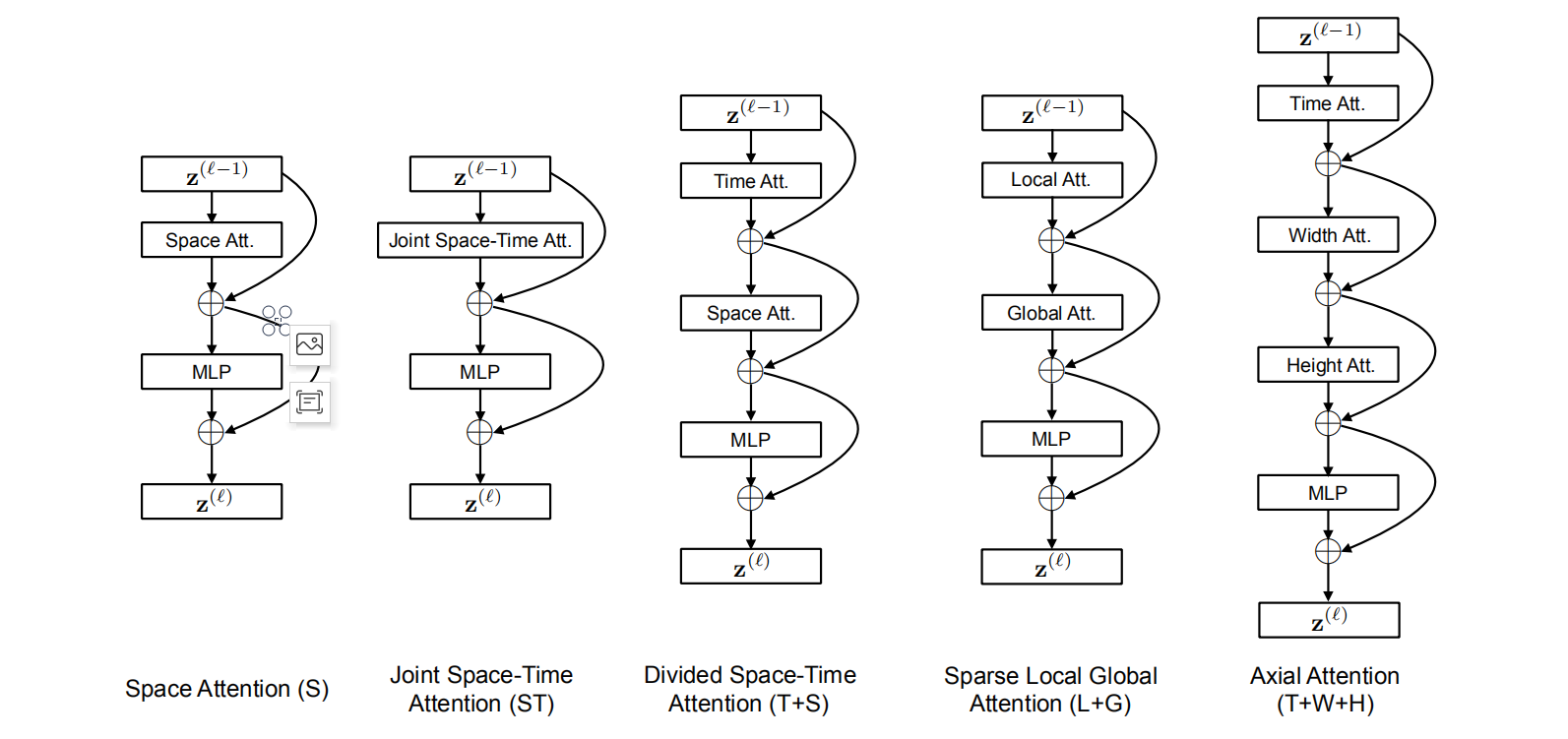
首先我们要定义一个SpaceTimeTransformer类,在其初始化函数中,首先保存其设置,设备,输入维度
线性嵌入
首先论文将clip分解为patches,用x来表示每一个patch,公式1进行了线性嵌入得到嵌入向量z,其中E和e都是可以学习的参数,e代表对每个patch的时空位置进行编码的位置嵌入向量。
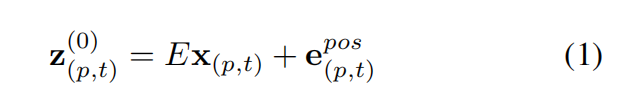
查询键值计算
模型包含了L个编码块,在每个块中,为每一个patch的表示(由上一个块编码得到)中计算查询/键/值向量。其中LN()代表LayerNorm;a = 1,…,A,其中A为多头注意力的数量,其中每个注意力头的隐维度数量为Dh = D/A
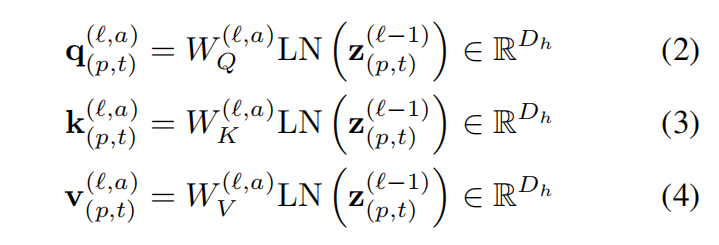
自注意力计算
自注意力权重可以按照如下的公式进行计算:
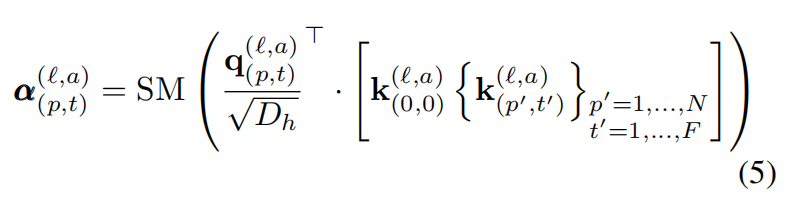
SM()代表softmax激活函数,自注意力仅在p(空间维度)或t(时间维度)上进行计算所以计算量被显著地降低了。
编码过程
第l个块的patch编码z可以通过:
- 先计算值向量的加权和,公式如下:
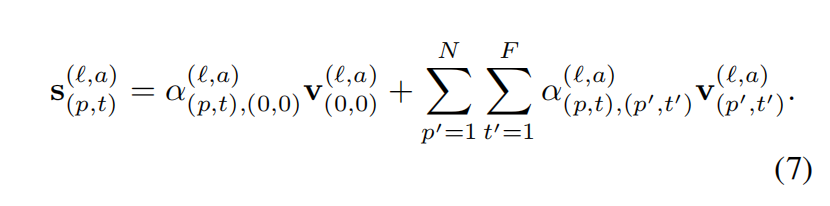
- 将这些向量沿HEAD维度进行连接,再传入多层感知机即可得到最终编码向量(注,在每一个操作中还使用了残差连接):
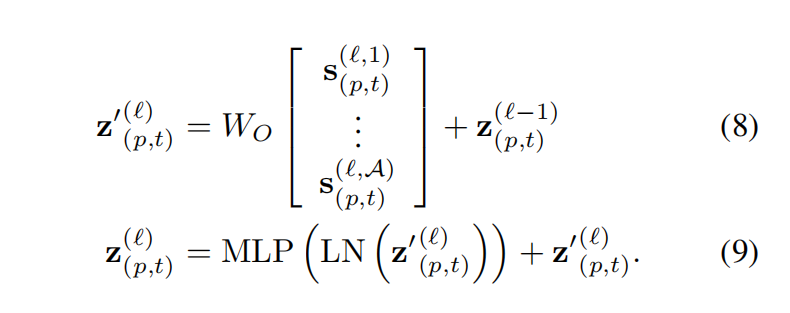
模型实现
上边主要从理论方面解释了如何计算attention权重,下面从代码的角度分析如何去实现模型:
我将encoding和decoding所做的处理进行了分析,如下图所示:
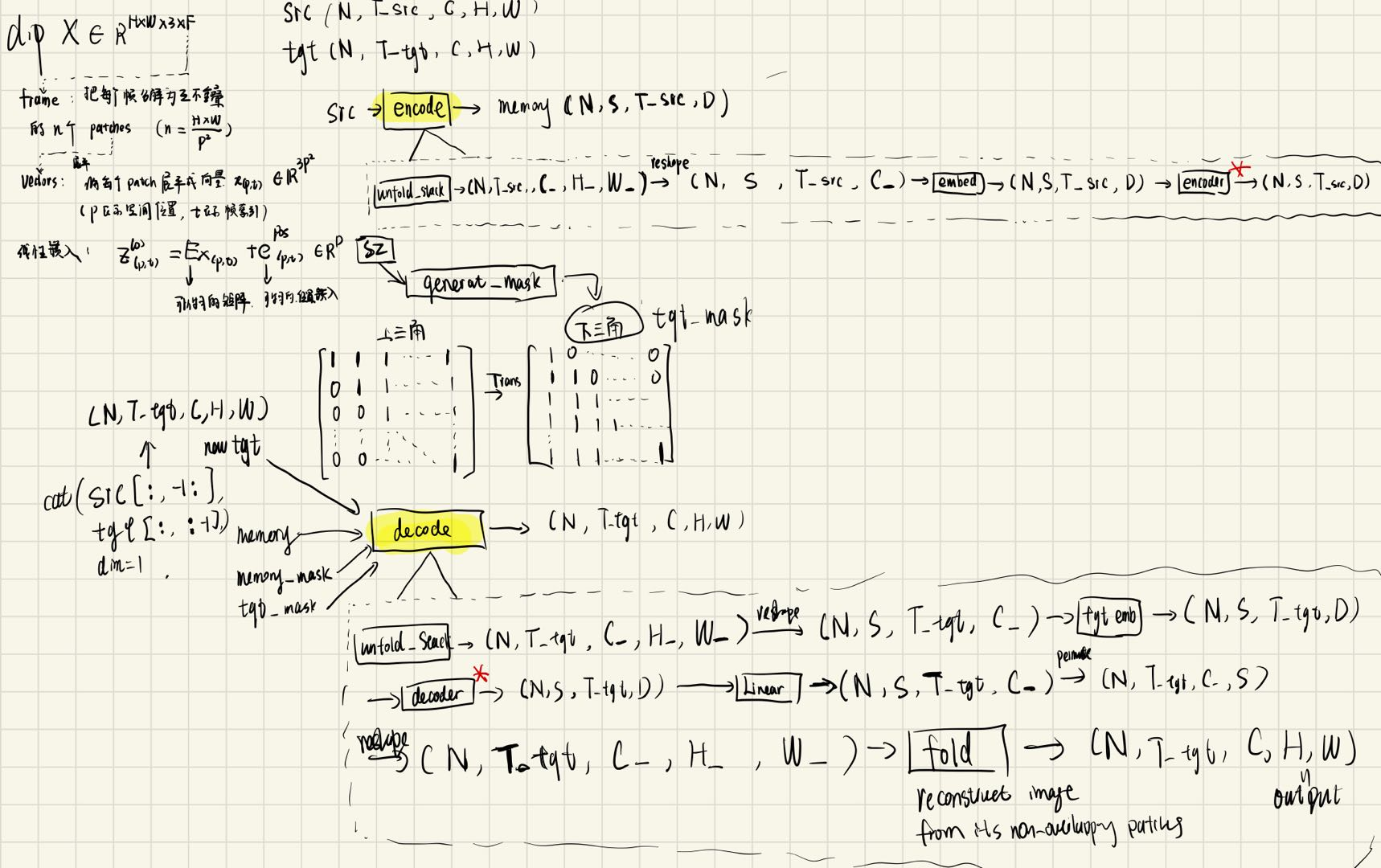
首先代码定义了SpaceTimeTransformer类,在该类中定义了如下变量:
src_emb
该变量是input_embedding类的实例,用于对输入进行嵌入,所作的简而言之就是进行一个线性变换,加上位置编码和时间编码:
1
2
3
4assert len(x.size()) == 4
embedded_space = self.emb_space(self.spatial_pos) # (1, S, 1, D)
x = self.linear(x) + self.pe_time[:, :, :x.size(2)] + embedded_space # (N, S, T, D)
return self.norm(x)tgt_emb
该变量是input_embedding类的实例,用于对输出进行嵌入。
encoder
decoder
linear_output
由 定义的变量可以看出,该模型采样了encoder-decoder框架,src即输入序列期待通过该框架生成目标序列tgt,encoder将输入句子通过非线性变换转化为中间表示,decoder根据中间表示和历史信息yi-1生成yi。
该类的方法为前馈操作,编码方法,解码方法,生成掩膜:
forward
在forward方法中首先调用了encode方法将src和src_mask作为参数进行编码,如果处在训练过程中:为target生成mask,并将必要参数传入解码器进行解码得到了sst_pred。如果ssr_ratio>1e-6,那么使用Teacher forcing生成一个teacher_forcing_mask,否则该mask为0,Teacher forcing就是直接使用实际标签
作为下一个时间步的输入,由老师(ground truth)带领着防止模型越走越偏。但是老师不能总是手把手领着学生走,要逐渐放手让学生自主学习,于是我们使用Scheduled Sampling rate来控制使用实际标签的概率。在训练初期,ratio=1,模型完全由老师带领着,随着训练轮数的增加,ratio以一定的方式衰减(该方案中使用线性衰减,ratio每次减小一个衰减率decay_rate),每个时间步以ratio的概率从伯努利分布中提取二进制随机数0或1,为1时输入就是实际标签 ,否则输入为 。再将新的tgt送入decoder进行预测得到了sst_pred。 如果处于验证阶段,每次预测一次sst_pred并加入,之后计算nino_pred并返回。
encode
在encode方法中,使用了unfold_StackOverChannel方法将原图像分解为patches
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20def unfold_StackOverChannel(img, kernel_size):
"""
divide the original image to patches, then stack the grids in each patch along the channels
Args:
img (N, *, C, H, W): the last two dimensions must be the spatial dimension
kernel_size: tuple of length 2
Returns:
output (N, *, C*H_k*N_k, H_output, W_output)
"""
n_dim = len(img.size())
assert n_dim == 4 or n_dim == 5
pt = img.unfold(-2, size=kernel_size[0], step=kernel_size[0])
pt = pt.unfold(-2, size=kernel_size[1], step=kernel_size[1]).flatten(-2) # (N, *, C, n0, n1, k0*k1)
if n_dim == 4: # (N, C, H, W)
pt = pt.permute(0, 1, 4, 2, 3).flatten(1, 2)
elif n_dim == 5: # (N, T, C, H, W)
pt = pt.permute(0, 1, 2, 5, 3, 4).flatten(2, 3)
assert pt.size(-3) == img.size(-3) * kernel_size[0] * kernel_size[1]
return pt分解为patches后,将其reshape并做一个embeding,再将编码张量送入encoder中进行处理并返回(memory)
decode
与encode的过程类似,也需将tgt分解为patches并将其嵌入传给decoder进行解码(还有memory,mask等参数)并返回
generate_square_subsequent_mask
该方法为生成掩膜的方法
实验
数据处理
读入数据
- 首先使用xarray库读入数据集
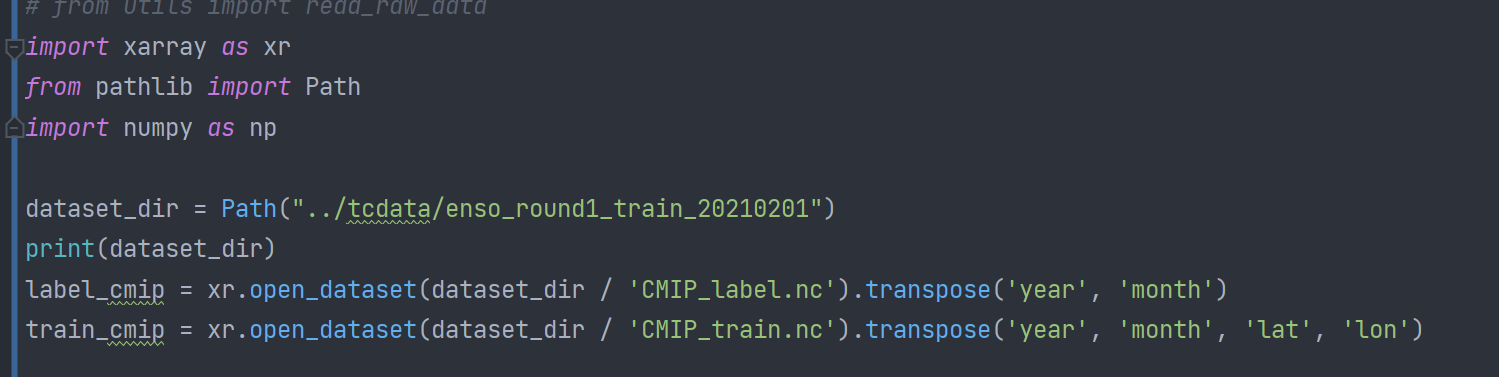
- 查看cmip数据集的sst变量的shape
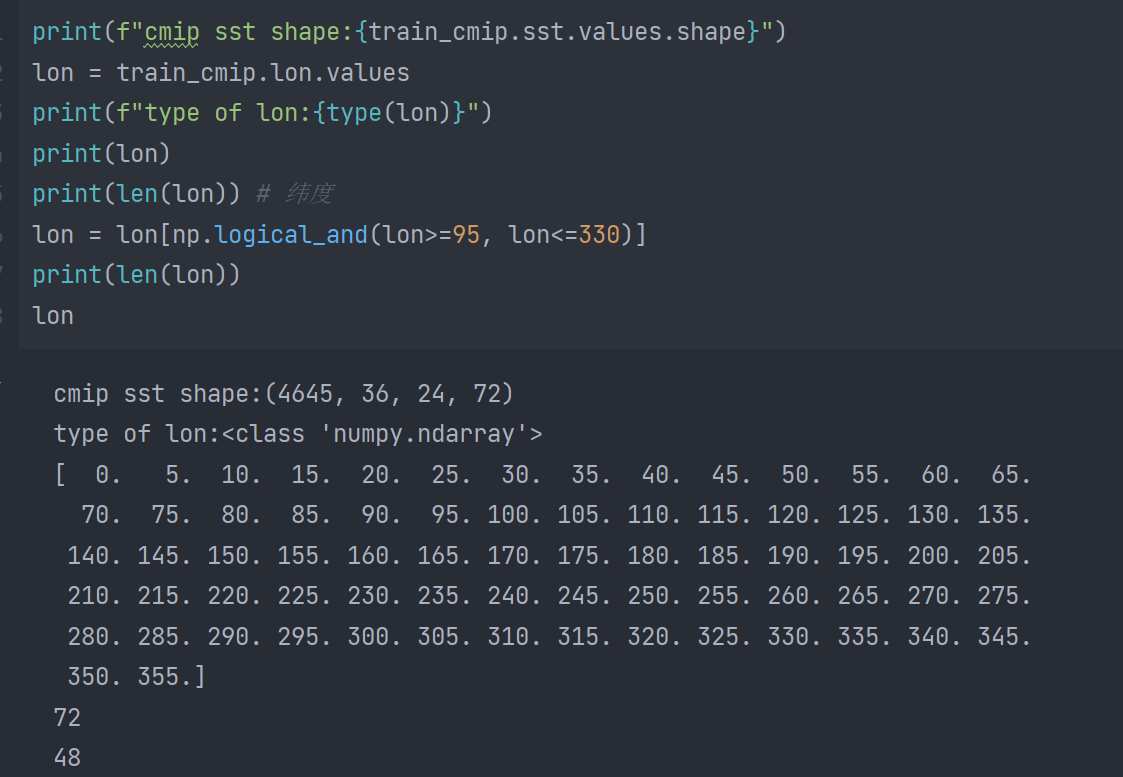
数据扁平化
使用sel方法选择纬度在一定范围内的数据:

这一步的主要作用在于降低空间分辨率,从而减少计算量
- 分解为cmip6和cmip5并对每一个数据集进行数据变换,以cmip6为例,他只使用sst特征,一共有15个模式,每个模式151年,并将同种模式下的数据拼接起来,之后采用滑窗构造数据集(每3年采样一次,去重):
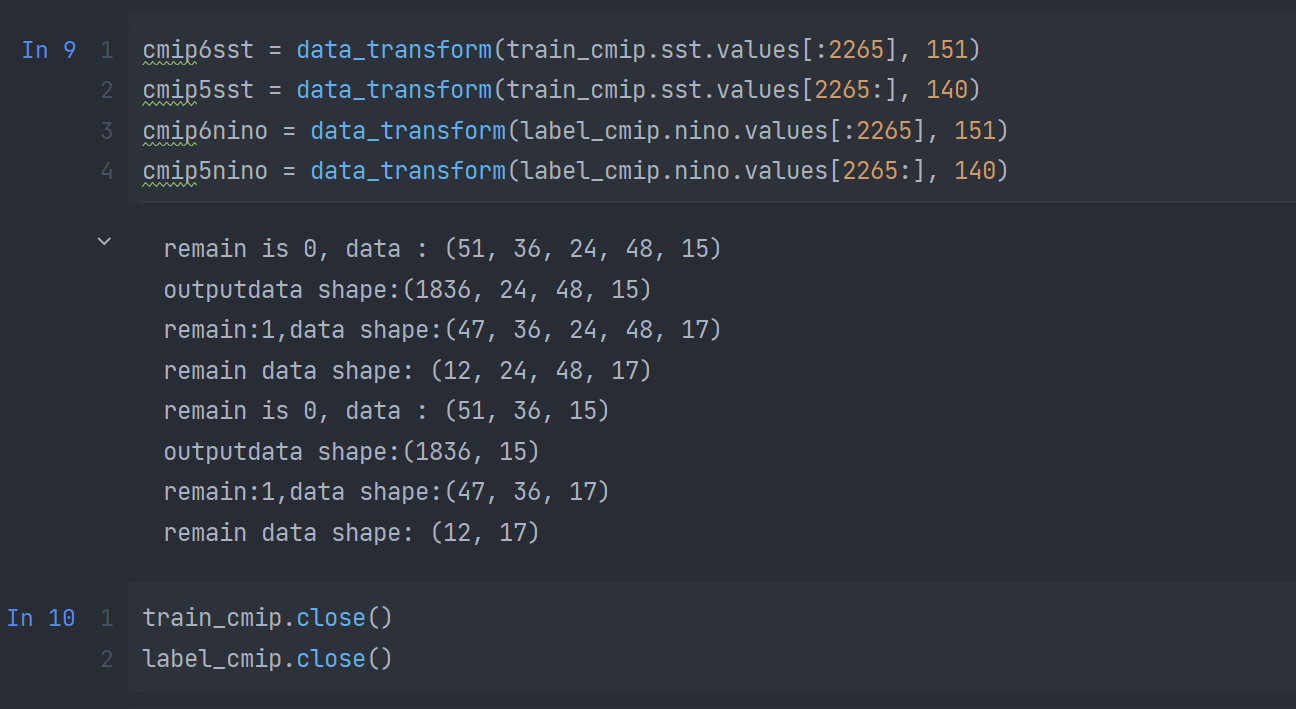
构造CMIP数据集
12+26 = 38
下面是我手动分析如何构造cmipdataset的过程,简要概括一下就是,cmipdataset将cmip5、cmip6连接在了一起,对于cmip5的操作,对于cmip6是同理的。下面的红色的shape主要是针对cmip6的,概括一下数据集构建的过程:
- 将序列数据集模拟为视频数据集,设定输入帧时间间隔,输入帧长度,预测偏移和要预测的未来帧长度,具体如下图所示;
- 以gap=5为采样间隔提取clips,将clips分为input_sst(长度为12)和target_sst(长度为26),每两个输入clip之间有7个月是重复的,输出clip之间有21个帧是重复的;
- 维度转换在每一步中已清晰列出,注意,为了模拟视频数据集,代码手动添加了channel维度;
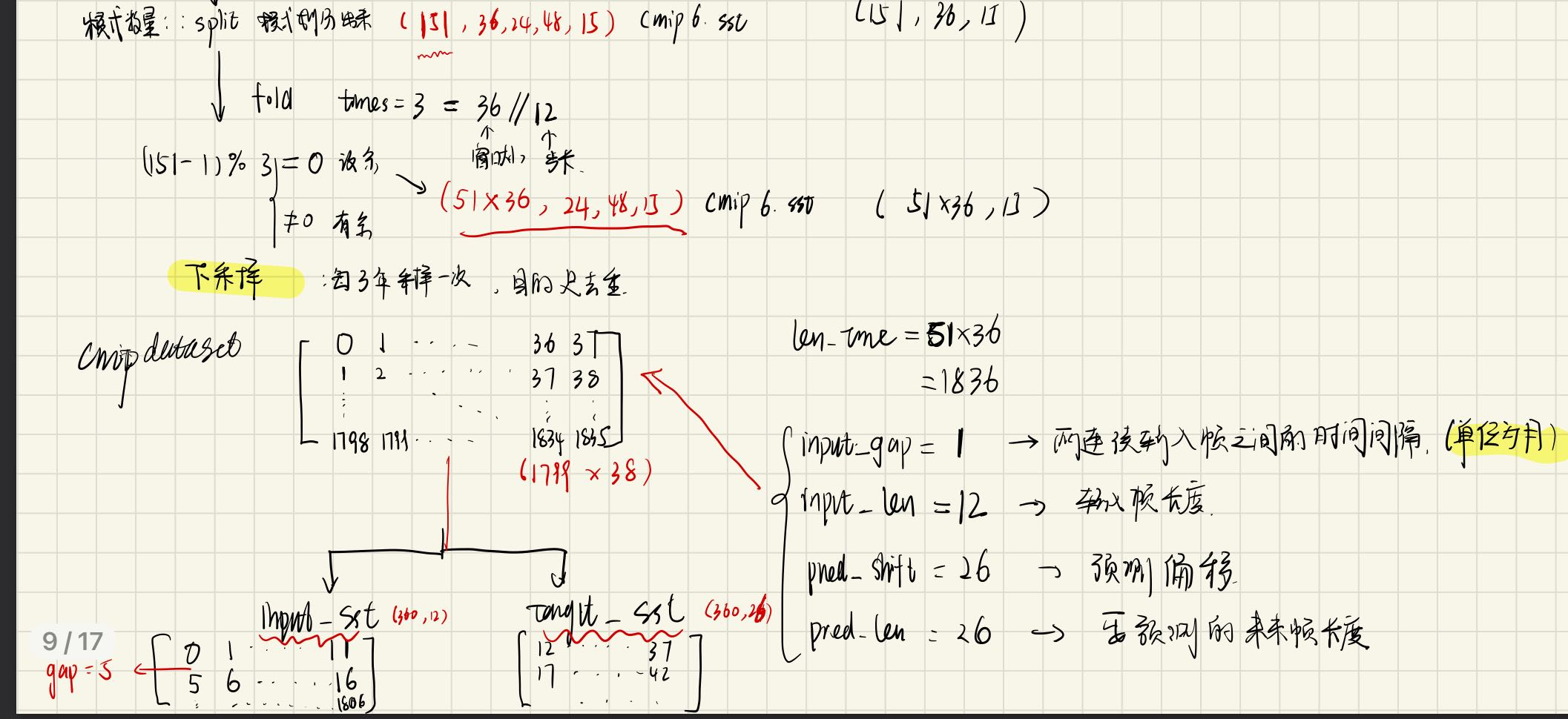

下图是数据集的生成结果,可以看出sst_input,sst_target,nino target均与手动推导的shape是一致的:
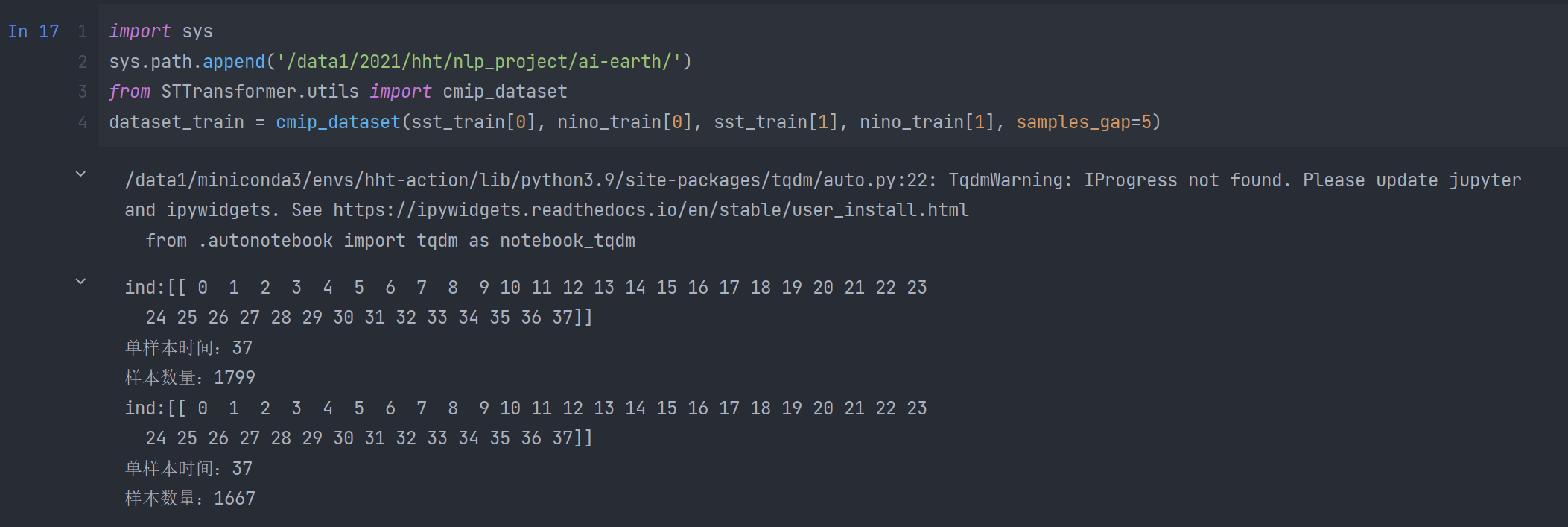
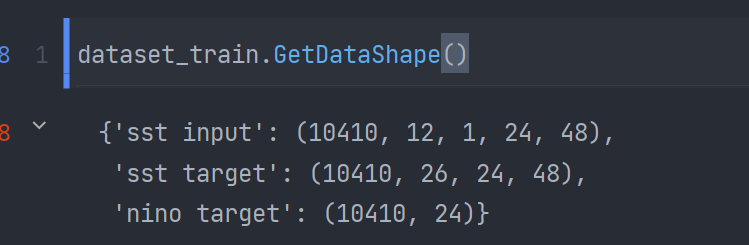
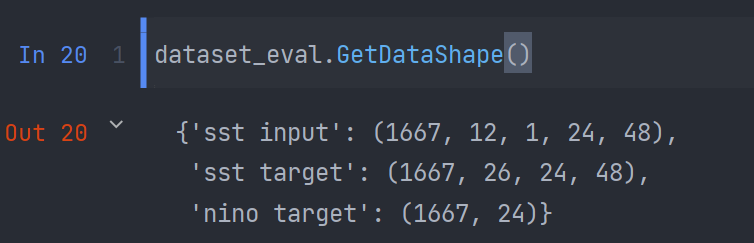
验证集的处理类似,这里不再赘述:
模型训练
导入训练以及模型配置:
- 单卡gpu
- batch-size=8
- epochs=100
- gradient_clipping = False
- weight_decay=0
- d_model=256
- patience = 3
- patch_size=(2,3)
- emb_spatial_size = 12*16
- number of heads = 4
- num of encoding layers = 3
- num of decoding layers = 3

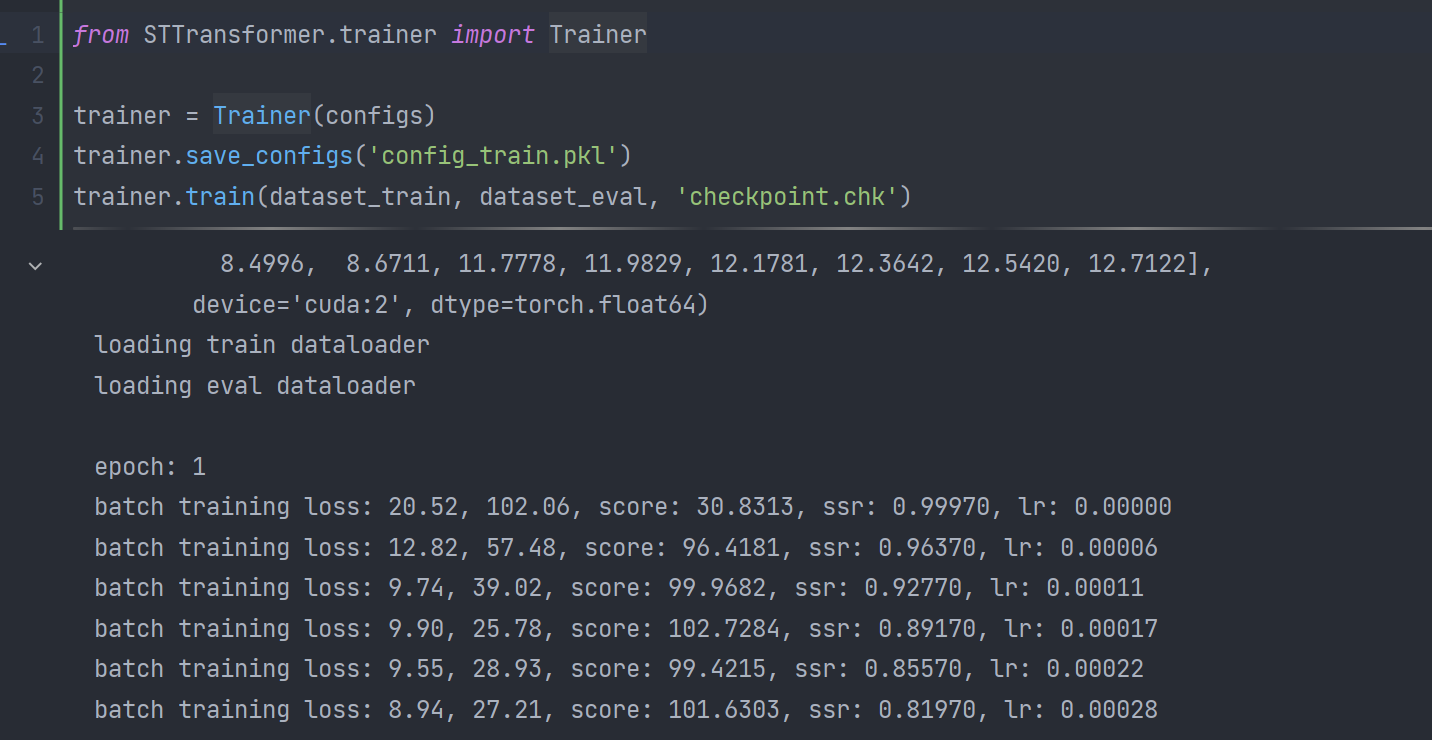
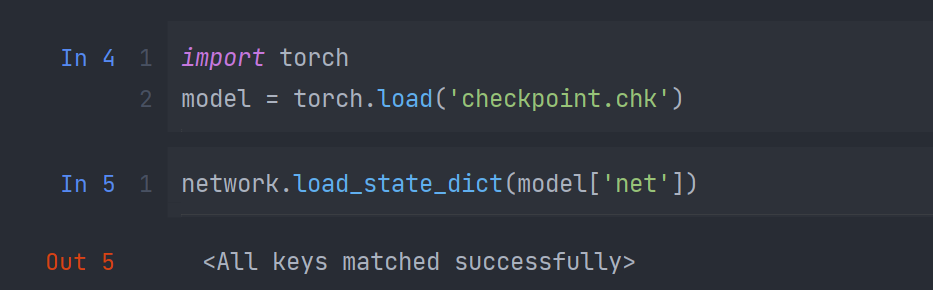
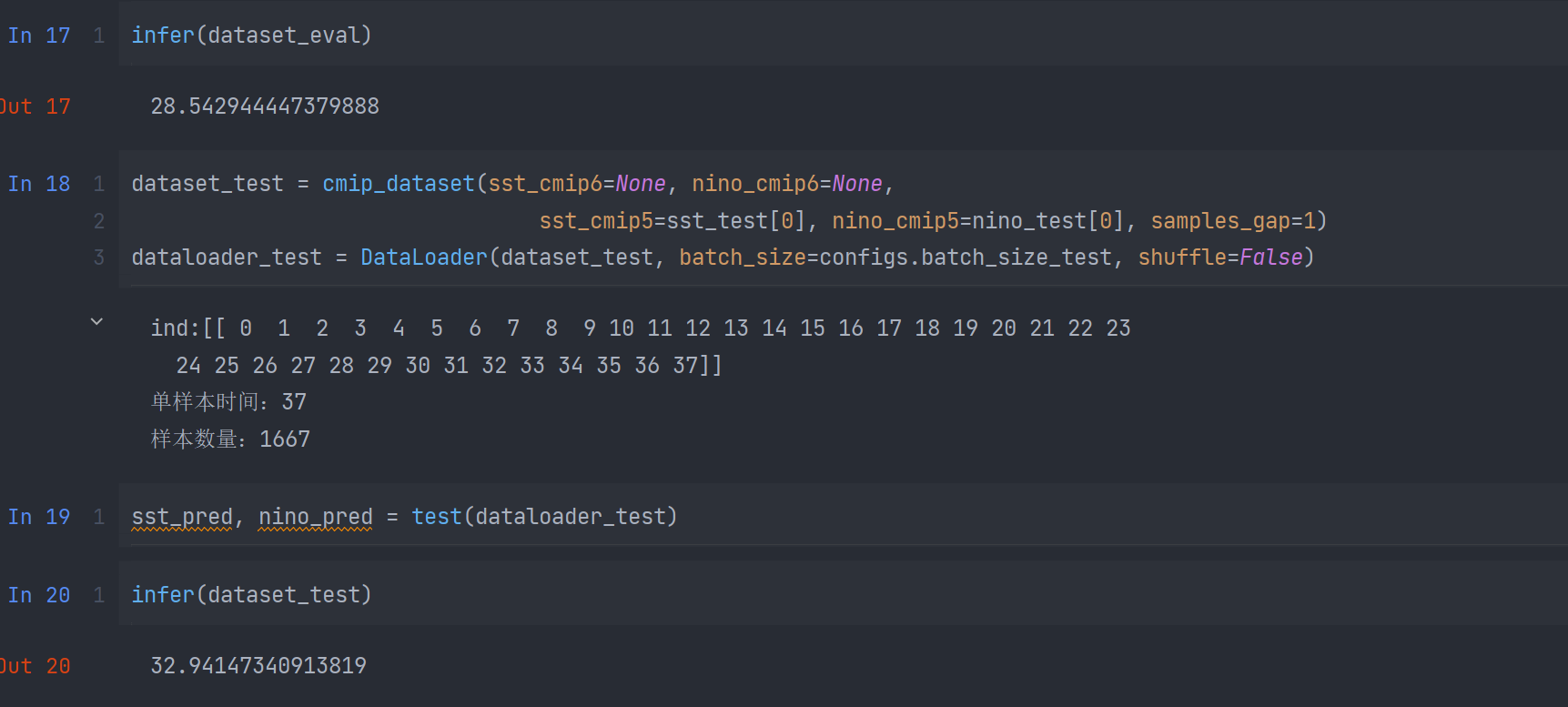
模型验证
将训练好的模型进行验证,先将模型的weight进行读取,将得到的模型在测试集上进行推理,最终的score分数约为33,如下图所示:
精度优化
自注意力权重修改
计算注意力权重时,将顺序计算改为对空间和时间同时进行计算
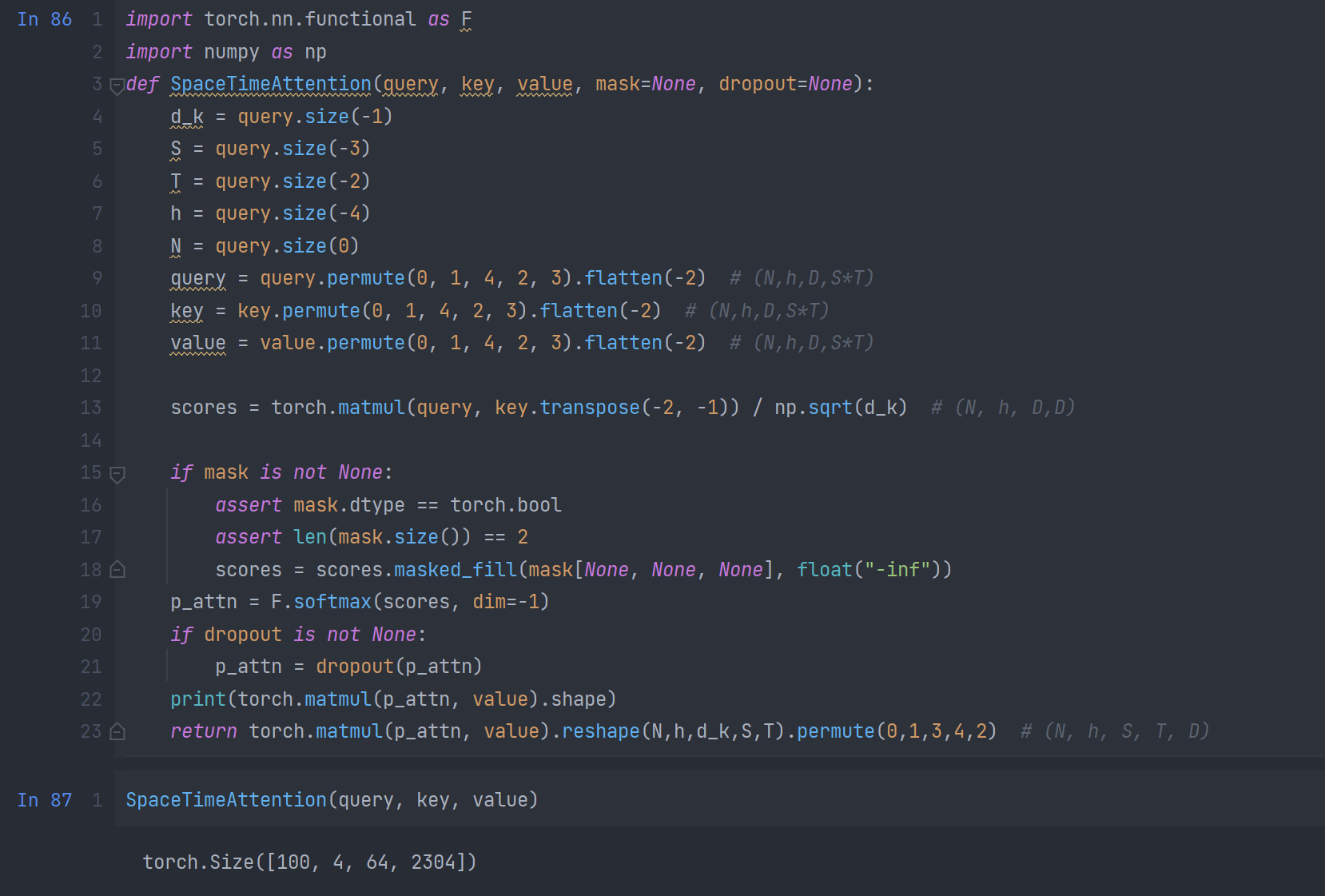
并将合并式注意力替代分离式注意力重新进行训练,发现效果没有提升
结论
实验证明,将时间序列数据集当作视频使用transformer进行训练是可行的,最终的score可以达到32。相较于CNN,transformer的结构更加复杂,而且自注意力的设计对于网络的性能影响很大,稍微修改一点,网络就有可能无法收敛。实验证明使用transformer去捕获长范围的时间依赖是十分有效的。
- Post title:AI-EARTH学习记录
- Post author:sixwalter
- Create time:2023-08-05 11:14:26
- Post link:https://coelien.github.io/2023/08/05/projects/nlp project/ai-earth_with_pytorch/
- Copyright Notice:All articles in this blog are licensed under BY-NC-SA unless stating additionally.